Technologies
QUEUES & STREAMS
Queues (and to some extent Streams) are well-established integration techniques that exhibit useful technical qualities, such as:
- Scalability.
- Availability, Resilience, and Reliability.
- Evolvability, mainly through Loose-Coupling.
- High Extensibility (Streams only).
Both are commonly employed techniques to protect systems from downstream failures, particularly when those systems are outwith your control (i.e. third-party services).
Queues are one-to-one channels; one thing places a message onto the queue, and only one (logical) thing processes it (whilst thre may be multiple instances, it's of the same consumer). Streams, however, follow a different (Publish-Subscribe) model, where one thing publishes a message onto a topic (not a queue), and one or more consumers process it, blissfully ignorant of each other.
THE PUBLISH-SUBSCRIBE MODEL
The term Publish-Subscribe originates from the publishing world, where one publisher “publishes” content to multiple (possibly millions) of subscribers (also known as consumers). Think of any global publication that publishes to millions of paying subscribers. The publishing model is the same, regardless of the number of subscribers.
The power of Streams lies not in the fact that you can push messages to multiple consumers, but in the ability to add new consumers with great ease. This supports high Extensibility and Evolvability. You can create a framework to support existing business cases, cognisant that new business cases can be easily catered to, simply by creating and attaching (i.e. plugging in) a new consumer (Open/Closed Principle).
STREAMS AND PUBLISH-SUBSCRIBE
Streams are really just a supercharged form of Publish-Subscribe, with the addition of extreme scale, and durable, reliable, and replayable delivery.
But both Queues and Streams also offer several other advantages. Consider the figure below, showing a schematic of the RMS Titanic.
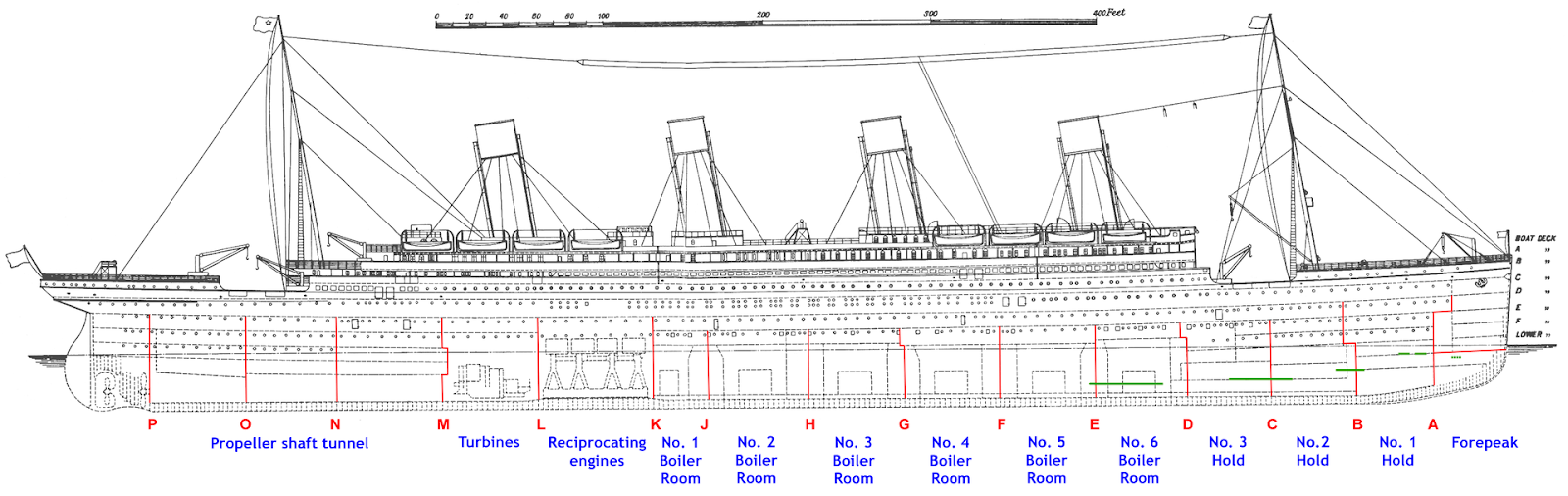
Bulkheads in RMS Titanic [source: Wikipedia]
The idea of bulkheads is not a new one. The Chinese have been building ships using bulkheads (compartmentalising) for many centuries (Chinese junks contained up to twelve bulkheads), for several reasons:
- To prevent goods contamination.
- To harden ships (i.e. structural integrity).
- Reduce the likelihood of sinking, by creating watertight compartments that will fill, but won’t let others; i.e. when one part of the ship floods, compartmentalisation ensures that other parts don’t flood, keeping the ship afloat.
You might wonder why I chose the RMS Titanic; it is, after all, notorious for its tragic failure. However, it failed not because of the compartmentalisation approach but mainly due to the poor implementation of it (and some pure misfortune). And it’s a good example of how no (or poor) compartmentalisation can have disastrous outcomes. Once the water flowed over one bulkhead it would then flood the next, in a cascading fashion, until sinking was the only outcome.
Contamination is another interesting one, and plays into Domain Pollution. The Chinese didn't want a catch of fish contaminating other perishable goods, such as grain, so they kept them isolated and prevented their intercourse.
All these ship analogies are also good analogies for how we should build software, which we can also relate back to Queues and Streams. We want to prevent the flooding of our systems, and no part of a system should bleed responsibilities or data into another domain, or we contaminate that domain with productivity, evolutionary, and data integrity challenges.
REAL-WORLD EXAMPLE - THE THAMES BARRIER
The Thames Barrier (built in 1982) is another great example of a compartmentalising technology that helps prevent flooding; in this case, it protects central London by raising barriers that stop the flow of water from an otherwise uncontrollable party (the sea). In the software sense, the Thames Barrier behaves (in some ways) like a queue, by separating a large body of water from an important landmass.
By placing intentional barriers between distinct domains, we ensure one can’t flood another, giving us time to pump out the water (or messages) when convenient.
Consider the following. I once worked on a project to act as a return channel for external customer systems, enabling interesting internal events about a user to be returned (using webhooks and Apache Kafka Streams). We could have used a queue, or even a synchronous API call, but (in this case) using Streams showed the greatest promise. We didn’t know all the consumers we’d want, but when the time comes, we’ve got all we need to add (a) single-customer view database, (b) a events area to feed visual timelines, (c) feed a reporting database, (d) reporting aggregators, for business metrics (e.g. how many customers bought productX in the last hour). The possibilities are almost endless (the framework handles it - the Open/Closed Principle at its best).
Streams also seem like a good option for rollback actions in distributed systems. Suppose we must manage a complex transaction across several key components of a distributed system. We complete four out of the five actions, but the final one fails, and we must undo them all (this is a common problem with Microservices). Rather than now orchestrating four explicit undo operations, alternatively, we might register them all on a stream, and manage the rollback internally. If the workflow growth does six things, we just attach another consumer onto the stream.
Before finishing this part, let’s consider some of the challenges of Queues and Streams:
- User presence. How important is it to your business to have the user present at time of processing (e.g. point of sale), to receive immediate feedback? When a user interacts in a synchronous manner (i.e. we block, awaiting a response), then the user always receives a response (regardless of its success). However, when requests are actioned offline (i.e. asynchronously), sometimes hours later, then we can’t expect the user to be present. In this case, how do you inform the customer about the result of their action? This problem often falls under the Useability versus Scalability & Resilience question; do we build a scalable solution where the user receives an eventual response, or block critical system resources and supply the user with immediate feedback?
- Developing and testing an asynchronous solution is more challenging than a synchronous one. Each action is temporal, and requires greater knowledge (and patience) of a more implicitly defined flow. Ordering may (or may not) be important, but also tends to be implicit and decentralised (rather than a more centralised synchronous flow).
- Error handling. If an error occurs during consumer processing, should it retry? How long should we wait before retrying? Do you apply back-off-and-retry tactics? How often should we retry before giving up? Should we store poison messages on a Dead-Letter-Queue to prevent them clogging up the queue/stream?
- Message contents, data staleness, and (thus) inaccuracy. Do we place the entire contents onto the queue, or just a pointer to retrieve the data at a later time? If we embed sufficient data into the message for the consumer to process, without returning to the master data store, how likely is it that the master and the copy (within the message) lack synchronisation? Does it matter?
- Event ordering. What do you do if you receive one event before another (expected) one? Complex workflow typically expects some actions to occur before others; e.g. take a payment before enabling a service for the customer. This ordering requires more complex management and prevents some of the benefits of parallelism.
- Reporting upon queues. It’s generally easier to report on a centralised database than a disparate group of queues (including a Dead Letter Queue), as it’s a more established practice.
FURTHER CONSIDERATIONS
- Publish-Subscribe
- Open/Closed Principle
- Domain Pollution
- Dead Letter Queue