SYSTEMS THINKING
Work-in-Progress...
SECTION CONTENTS
- Assumptions
- Functional Intersection
- Domain Pollution
- Real-Time Reporting
- Build v Buy
- Entropy
- (the) Many Forms of Coupling
- Technical Debt
- Separaion of Concerns
- Indirection
- Refactoring
- Feature Parity
- Technology Sprawl
- Object-Relational Mappers (ORMs)
- System Tenancy
- Containers & Orchestration
- Feature Flags
- Gateways
- PAAS (PLATFORM-AS-A-SERVICE)
- Test Granularity
- Granularity & Aggregation
- When to Test?
- Types of Testing
- Regression Testing
- Flooding the System
- Smoke Testing
- Exploratory Testing
- Performance Testing
- Volume Testing
- Load Testing
- Stress Testing
- Endurance (Soak) Testing
- Spike Testing
- Cybercrime
- Penetration ("Pen") Testing
- Unit Testing
- End-To-End (E2E) Testing
- Integration Testing
- Acceptance Testing
- SLAS
- Synchronous v Asynchronous Interactions
- The Cloud
- Serverless
- Cloud Agnosticism
- Denial-Of-Service (DoS)
- (Distributed) Transaction Tracing
- IAAS, PAAS & SAAS Responsibilities
- Infrastructure-As-A-Service (IAAS)
- The Weakest Link is the Decisive Factor
ASSUMPTIONS
Assumptions are a root cause of Change Friction and Surprise. Assumptions are the remnants of a decision (verbal or technical), that may undermine the overall success of a feature.
At all levels of product development we make many assumptions, including:
- The level of skill and understanding of key decision-making stakeholders.
- How responsibilities are aligned within each software unit. One way to understand the level of Assumptions (potential coupling in software), is to look at its dependencies. Generally, the greater the dependencies, the more Assumptions exist about its execution environment, context, or constraints (e.g. temporal Availability).
- The assumed level of security (Perception) in a software component compared to its actual.
- The likely success of introducing a product into the market. You can do all the market research you want, but you'll never truly know until you do it.
- The types of coupling (e.g. temporal) employed at the software, or business level.
- The Availability of other systems.
- That correct (and accurate) information has been supplied, at the right time, to the right people, to successfully undertake a task (JIT Communication).
- That the customer's Perception of quality mirrors your own.
- The customer truly understands the proposed delivery plan.
- Understanding all the nuances of a new technology is seamless and quick to an uninitiated team (a common mistake).
- That a chosen technology is truly agnostic.
- 100% Test Coverage equates to zero bugs.
- Buy is always cheaper than Build.
- Connectivity assumptions - i.e. "I can connect this to that". This may not be true. For instance, a Governance or Security function may stop you from doing so.
- Scaling assumptions; i.e. "System A will scale to my needs, so I don't need to test that assumption." Possibly, but I'd label that a risk.
Individually, each assumption seems manageable, but when viewed in its entirety, we have a Complex System, exposing a myriad of minutiae that makes second-guessing impossible.
I categorise Assumptions into four areas:
- They are correct and require no remedial action. These have positive outcomes.
- They are embarrassingly wrong, but will be quickly noticed due to their inaccuracy (and thus, are relatively inexpensive to resolve).
- They are entirely wrong, yet insidious, and remain undiscovered for years. These are highly problematic as they infer the inaccuracy of a foundational decision that (a) has remained so for a long time, and (b) that remedial action may no longer be possible (e.g. due to high expense). Failing tend to be architectural decisions, such as poor security, vendor coupling, business logic in the database, overuse of a DB triggers strategy, integration by data duplication, never undertaking performance tests.
- They will seem unimportant, and thus will be ignored, but combined with other seemingly innocuous decisions, accrue over time into something more dangerous (like little fish that take many small bites from you). This might include: a bottom-up API design, no clear versioning upgrade strategy, failure to encrypt sensitive data, client-dictated upgrade timelines, Domain Pollution. Many developers tend to focus on solving immediate problems, and don't necessarily appreciate that a single, seemingly innocuous assumption can significantly impact a system, and thus, a business.
Assumptions tend to be more wrong when dealing with an unknown quantity (i.e. the opposite of Known Quantity). However, that should not dissuade us from change, else we fail to evolve!
To some extent, Assumptions can be countered with:
- Feedback cycles. By regularly testing the accuracy of an idea and feeding it back in, we can quickly identify gaps in thinking.
- Continuous practices such as Continuous Integration (CI), Continuous Delivery (CD), and Continuous Learning. It’s one reason why CI and CD are so popular; they expose Assumptions sooner.
- Agile, DevOps, and Cross-Functional Teams. All these are approaches to increase collaboration across a more diverse range of people, with varying skill-sets. Assumptions are caught sooner, often before any significant effort is undertaken.
- Safety Net. Techniques like sprint Spikes are a form of Safety Net that test the veracity of an assumption. Quality test automation reduces flawed assumptions that a change works.
- Prototypes. Placing a basic prototype in front of your customer early provides vital feedback about how something should function (and look). This reduces the likelihood of incorrect assumptions.
- A flatter employee hierarchy, where everyone contributes with valuable insight to make more accurate decisions.
FUNCTIONAL INTERSECTION
When looking at any significant systems integration (including the Build v Buy option), it’s important to consider Functional Intersection.
In the context of systems integration, Functional Intersection indicates the amount of functionality (or behaviour) that (fundamentally) represents the same concept, across two distinct systems. It is a common cause of Technology Consolidation headaches.
Consider the figure below, showing two systems being considered for an integration project (A is your existing system, whilst B is the one under inspection).
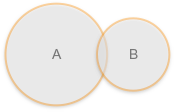
Small functional intersection between two distinct systems
In this case, we have a small intersection between System A and B.
FUNCTIONAL INTERSECTION IN RESPECT TO SYSTEM SIZE & COMPLEXITY
The size and complexity of the two systems being considered for integration is also important. Typically, the larger they are, the more complex there are, and thus, the greater the number of Assumptions they contain. This suggests an increase in the number of integration tasks required.
Why even care about the intersection, and specifically its size? Well, to generalise, a large intersection infers that each system must know a lot more about each other than a smaller intersection, and this may have unexpected and sometimes damaging results.
Functional Intersection often leads to data duplication, by duplicating of domain concepts across systems (we must synchronise the same domain entities across both systems for all changeable events; i.e. create, update, and delete operations), and thus, a duplication of integration tasks. The problem is that all this duplication has little to do with business needs, it’s simply to meet system expectations (Satisfying the System), and that leads to the Tail Wagging the Dog syndrome; e.g. technology dictates the business’ direction to travel.
INTEGRATION == COMBINING
When we discuss “integration”, we’re really describing the joining or combining of multiple systems (or subsystems) together to form (typically) a larger, more functionally-rich software solution.
Consider the following example. Let’s say both systems A and B (from the earlier figure) are e-commerce solutions. We are actively using System A, but have found it lacks some key features. The business has identified an opportunity to better engage web customers to increase spend, by providing them with a richer and more immersive product catalogue experience. We’re undertaking a due diligence to identify the right strategy (Build v Buy).
Before continuing it's worth mentioning a key oft-neglected point. We already have existing sales coming through System A‘s order processing subsystem (which our business is too tightly coupled to, to change), so we must also continue to support products in system A. In Layman terms, that means we must mirror the same product in both systems.
Now, to successfully reflect one entity in another system, we must handle all changeable events (events that have a state change on that entity). For a product (and I’m underselling this too), must support the following actions:
- Create Product.
- Update Product.
- Delete Product.
That’s three events. But remember, since both systems need the same products (one for a rich user experience, and the other to process orders), we must reflect the same changes. That’s a duplication of effort.
Thankfully, in our case, the intersection seems relatively small (a good sign), indicating a relatively clean integration. However, there’s deeper considerations around dependencies.
Let’s say the business had decided that System B’s Payments solution (it enables us to offer additional payment capture options on top of System A) was also impressive, and they’d like to incorporate it into System A and sell it. The thing is, they still want to keep aspects of System A’s Payment solution too (it’s currently being used by some significant customers).
Again, we undertake our due diligence; this time not only analysing the desired feature, but any dependent features it uses. We identify the following dependency hierarchy:
- Payments (in both system A and B)
- Carts (in both system A and B)
- Customers (in both system A and B)
-
Products (in both system A and B)
- Catalogue (in both system A and B)
- Carts (in both system A and B)
Again, we’re Satisfying the System - to incorporate one function, we must satisfy every other function dependency. For example, to use the Payments feature, we must ensure we’ve stored a Customer and managed it through a Cart, and added a Product to a sales Catalogue.
MASTER/SLAVE
The duplication of domain concepts across different systems (boundaries) also raises the notorious Master-Slave question. We get cases where system A is the master of some concepts, and system B the other. In the worst case, you may have two masters for the the same domain concept, but offering different consumer flows. Apart from the massive system complexity this causes, it may also cause cultural tension as teams lose sight of business intent and become a slave to the system.
The Functional Intersection for Payments now looks very different; see the figure below.
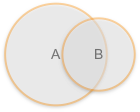
New functional interaction
It is significantly larger, and more complex than the earlier case. It also means we must synchronise across every entity:
- Product (create, update, delete).
- Catalogue (add, move, delete).
- Cart (create, add, remove, clear, checkout).
- Customer (create, update, forget).
- Payment (create, update, refund).
I make that a rather hefty 34 integrations (17 integrations * 2 systems).
That’s far less appealing, and potentially leads to Integration Hell. What might have been a few weeks of effort has now turned into a quarter or two. Is there still a competitive advantage of undertaking such a lengthy and risky integration?
I’ve witnessed poor Functional Intersection in (at least) three different contexts:
- Attempt to introduce an open-source product into the existing stack. Was unsuccessful, and not attempted due to integration effort.
- Introduce an existing internal (legacy) system to plug the functional gap. Was done, but lead to duplication of work, throwaway work on a legacy system, increased release and deployment effort and time, scalability and resilience concerns, productivity concerns.
- Use data replication techniques to share domain concepts across multiple systems. Massive complexity, pollution of master-slave concept, Domain Pollution, cultural concerns.
I haven’t yet seem a satisfactory way to handle the integration of large, tightly-integrated systems.
FURTHER CONSIDERATIONS
DOMAIN POLLUTION
Domain Pollution is often the result of poor software development practices, where one (or more) domains assumes another’s responsibility. It's relatively common in monolithic applications, and exposes significant system failings. The figure below shows an example.

Example of Domain Pollution
This system has five distinct domains, D1 to D5. Note that all domains use D5’s data (I have only represented D5’s dataset, but it's likely the other domains also manage their own datasets too).
This breaks the Single Responsibility Principle - a fundamental software structuring principle. Based upon Single Responsibility Principle, D5 should only interact with D5’s data. However, D1, D2, D3, and D4 have also assumed a responsibility of D5 and thus, have hoodwinked it. Domain Pollution has hampered D5’s evolution, further causing innovation, security, and scaling challenges.
SCALABILITY
"Just join domainA and domainB's tables, and you've saved yourself a database trip."
Beware! This argument suggests that you'll improve scalability by joining (coupling) domains together, since only a single database interaction is required (database interactions are generally expensive).
This is true, and false. You probably will improve scale... but only to a point. This advice advocates a vertical scalability strategy over a horizontal scalability strategy (the stronger of the two); thus, opting for the weaker alternative for the sake of productivity.
The join argument makes a dangerous usage Assumption (i.e. coupling). One domain has assumed another domain:
- Is always accessible, and available.
- That data will always reside within the same partition.
- That the same technology/vendor is suitable and will be used for both domains.
The SQL joins have:
- Tightly-coupled the domains to a database type (e.g. relational).
- Tightly-coupled the domain to a specific vendor (e.g. Oracle, Postgres).
- Made an assumption about where the data resides (i.e. on the same instance/machine).
EVOLVABILITY
Evolvability is a key, oft-forgotten, architectural quality. It indicates the ease with which a system (or part of a system) may evolve. In a scenario where Domain Pollution has taken over, we are severely hampered in our ability to modernise. To make any change, not only must we identify every area of change, we must also:
- Collaborate with all the domain experts to understand (and contain) the Blast Radius.
- Plan the capacity for the change.
- Fix/replace broken unit tests.
- Restructure (potentially) large swathes of code in the affected areas (e.g. passing an id through a set of layers to the persistence mechanism).
- Recompile and redeploy the domain.
- Regression test a large area of the system, and any of those area’s dependents.
- Load test it.
This is Change Friction. I’ve seen cases where only an individual (a “Brent” in The Phoenix Project) can resolve this friction, and that individual is unavailable for the next two months. This is a terrible situation. It affects your Agility and (potentially) Brand Reputation, and can leave your customers in a precarious position. The business may face a dilemma; do they let their customers down and lose their custom (possibly also suffering reputational damage), or do they choose to hack further (proprietary) changes into the solution and exacerbate evolutionary issues?
FORMS OF DOMAIN POLLUTION
Domain Pollution tends to be caused by the introduction of incorrect Assumptions in software. Several forms of domain pollution exist:
- Assuming another’s responsibility. One domain embeds a responsibility belonging elsewhere. I often see this anti-pattern applied in unexpected places; e.g. a developer copies some logic from one domain, and pastes it into another domain, and now there’s two polluted domains and a duplication of logic (a code smell).
- Assuming another’s data. Foreign key relationships actually tightly couple two domains together (e.g. the cross-domain SQL pollution I described above), incentivises developers to introduce Domain Pollution into code, and may hamper Evolution, Scalability, and Security.
- Exposing consumers to internal details. In this article on API design, I described the importance of the "Don't Expose your Privates" practice (Don’t Expose your Privates). In this case, an API exposes unnecessary details to external consumers, who become tightly coupled to those details. This adds (avoidable) complexity to an API integration, and also reduces Evolvability.
REAL-WORLD EXAMPLE
Many developers tend to focus on solving immediate problems, and don't necessarily appreciate that a single, seemingly innocuous, assumption can significantly impact a system, and thus, a business.
“Clean” domains can protect Business Agility and Brand Reputation, with flexible, evolvable, scalable, and secure software. Pollution can do the opposite.
I witnessed the ultimate form of Domain Pollution whilst analysing potential replacements to a large, monolithic application. The common approach to solving this problem is to break the monolith into smaller units (typically microservices), by identifying the seams and strangling (the Strangler pattern) each, one at a time.
However, I found this approach ineffectual due to significant domain pollution. Domain Pollution hindered evolution, and (to me) was the key technical factor for the product's demise. Change Friction dictated our direction, and resulted in the construction of a new (costly) product.
Some good approaches to counter Domain Pollution include:
- Encapsulating the data store, so others can’t access it.
- Always use an interface (e.g. REST API), and never undermine it through the circumvention of the data owner.
- Where practical, force the issue. For instance, by intentionally selecting to use a different data storage technology per domain.
- Employ user privileges (Principle of Least Privilege). Note that this approach has a positive side-effect as it also protects each domain's data from “polluted domain injection attacks”.
- Drive API design from the top-down (i.e. Consumer-Driven APIs), not the bottom-up. Let consumers drive flows, and models (if possible). Consider the need, name, and purpose of every data field before exposing it.
FURTHER CONSIDERATIONS
- See: https://medium.com/@nmckinnonblog/api-integration-manifesto-8814dbc7261a
REAL-TIME REPORTING
I've worked at several organisations that reported directly off the transactional database. Whilst it meant information was highly accurate, it also presented the business with some significant problems; namely:
- Scalability - labour-intensive reports reduced the system’s ability to scale for important customer interactions (including on-boarding and payment processing). Whilst reports are important, they are a side plot to the main story - to make a profit from custom. When less important processes dictates the capabilities of higher priority processes, we have a problem (Tail Wagging the Dog).
- Availability - running heavy reports can (I’ve seen it a few times) cause the transactional system to fail (Self-Inflicted Denial of Service), preventing access to legitimate users.
- Evolvability - one of my biggest bugbears. When the reporting scripts are tightly coupled to transactions data structures (and specific technologies), it becomes almost impossible to evolve (Domain Pollution).
- Security - in order for a report user to be effective, they’re often given higher access privileges, sometimes to the entire production database. This goes against a fundamental security practice (Principle of Least Privilege), and - if the account is compromised - could lead to a highly effective SQL injection attack.
Most modern business systems I’m aware of don’t report off the transactional database (although I suspect there’s sometimes a case for it). Several approaches are available, but most revolve around extracting (or pushing) and duplicating data to another data store (such as a data warehouse or data lake), and pointing reporting tools at it. This approach makes minimal contact with the transactional database, enabling us to respond effectively to heavy transactional user loads, whilst business-oriented reports and metrics are processed elsewhere. Typical push mechanisms include an ETL (extract a delta and push elsewhere), and event-based pushes (my preference), using technologies like Queues & Streams.
Whilst transferring reporting work off the transactional data store is (generally) a good approach, it does add some complications. ETLs may still cause negative performance effects on a transactional data store if not carefully controlled; for instance, by the delta extract. Event-based pushes tend to happen at the business tier (but not always; e.g. some NoSQL databases support event-based pushes; relational databases have triggers), that may still negatively impact the production system. These approaches lessen the impact, they do not mean no impact.
There’s also the question of accuracy and consistency. None of these duplication approaches quite gives us real-time accuracy, and (depending upon the context) may occasionally see a disparity of results. Generally, though, it’s sufficient for most. It also brings complexity into play, as generating the data to report on is more challenging; we must handle all changeable events (inserts, updates, and deletes). Of course, running reports directly off the transactional data store doesn’t require this step as the data is already available.
REPORTING IN A DISTRIBUTED WORLD
It’s worth noting that reporting on data across a distributed (potentially Microservice-based) system is very different to the well-worn Monolith path, for two reasons:
- Each Microservice controls access to its own domain data, and doesn’t allow anything other than itself to directly access it. Remember, to prevent Domain Pollution and support Evolvability, we need all interactions to be controlled from the microservice’s (REST) interface.
- Technology Choice per Microservice. If we allow each Microservice to select the appropriate data store technology for its needs (i.e. the right tool for the job), the end result may be a sprawl of disparate data storage technologies for one product. This makes a pull model (ETL or direct reporting access) impractical; you’d spend all your time finding the data, then integrating, rather than reporting. This approach strongly hints at an event push model.
FURTHER CONSIDERATIONS
BUILD V BUY
There’s always some friction between Build and the various forms of Buy, along with a common misconception that Buy is always financially superior to Build.
Consider the following example. You are employed to deliver a software system for a lucrative new customer. Let’s say you already have part of the solution, built out by an internal team, that meets sixty percent of the customer's functional needs.
It’s your job to decide how best to satisfy the remainder. The following options are on the table:
- Build out the remaining functionality using the internal team.
- Buy/Partner with a supplier to provide the remainder, giving them a cut of any profits.
- Reuse a legacy system.
- Use an open-source solution(s).
There’s many nuances to consider, and in the end, only you and your team have sufficient appreciation of your context to decide (i.e. external entities should guide you to the right decision), but I'd suggest the following considerations are a good place to start:
- The five business tenets (TTM, ROI, Agility, Sellability, and Brand Reputation), described earlier. Which ones are pertinent to this decision?
- How are these decisions being made? Are they made to satisfy immediate or long term needs.
- Capacity and appetite. Does your business have the capacity and appetite to undertake the work yourself? Is the work pivotal to your business, or just a sideline/subplot to the main story?
- You’re looking at the entire product lifecycle, not just an initial integration.
- Control. How much (and what type of control) do you require over the solution? Is the entire solution built, or does it require regular changes?
- Delivery speed. Can you, or the partner, deliver at the speed (and reliability) required by your customers?
- Reputation. Will a vendor relationship affect your reputation in the eyes of your customers (Perception)?
- Integration effort (particularly around Functional Intersection). What is the real integration effort, not the perceived effort? How often must you reintegrate, and what’s the cost of each?
- Who dictates when a change affects you? What sort of pre-warning do you get?
- Service Level Agreements (SLAs). What agreements around performance, scale, availability, security, and bug fixes are in place? Do they meet your needs?
- Consistency. If you provide either a UI or APIs facility for your customers to access your services, can you still provide a consistent experience if you buy it in? If the vendor supplies APIs, would you wrap them? What integration effort is required to do that? If the vendor supports a UI, cannot be rebranded?
- Expertise. What level of domain expertise do you have? Is it a highly complex domain, or one that can be quickly learned (e.g. would you really want to build a tax solution without having a complete understanding of the domain)? Does your business want to have that expertise?
- Evolvability. Is the repeated modernisation of the product important to you and your customers? What promises does the vendor make on this? For instance, if the software isn’t regularly modernised, it may lead to security vulnerabilities creeping in (and thus Branding Issues).
- Regression and verification. Who manages the regression testing of any changes? Are they automated?
- Test sandbox. I’ve seen numerous cases where test integrations are executed on a production system because no test environment is available. Testing using a production system may add significant risk and cleanup costs.
- Multi-tenancy. Although the standard Multi-Tenancy approach has many merits, particularly for the solution owner, it also has some difficulties, particularly around (a) single point of failure, and (b) noisy-neighbour interference; where other customers interfere with your solution, potentially causing slowdown or Availability failings. The converse is that you get new features quickly.
- Charge model. If Buy, what charge model is being used? One-off, free, licensed, per transaction, per subscription?
- Is the new system a direct competitor and replacement for yours? This raises product capability questions that may lead to political infighting. Is that important from a Sellability perspective?
Let's look at the options.
BUILD
Why would you opt for the Build option?:
- You have, or want, the expertise.
- There is no suitable alternative.
- You can’t hide a Buy decision. Potential customers may request information on all your suppliers and vet them prior to contractual agreement.
- You have (or can source) the requisite capacity to perform the work.
- There is value (i.e. profit) to be made from building it.
- It is expected by a customer, or any agreement to use another vendor is too challenging to explore.
- Control is important to you. Whilst Buy might work initially, you know each subsequent change is not guaranteed.
- You can fit the integration nicely with the remainder of the system.
ADVANTAGES
- You control your product’s direction.
- You can manage costs internally.
- It becomes a sellable feature.
- You gain expertise in it.
- You can make it fit, and Consolidation is no issue.
- Delivery, and change speed, are within your control.
- Operational costs are within your control.
- You may be able to claim tax credits for it.
- You can control the evolution of the software; e.g. manage security.
- You can control quality.
- You can control feedback loops for continuous improvement.
DISADVANTAGES
- Requires an initial expense.
- There is risk if the feature is not wanted.
- It may further blur the lines of the business’ specialism.
- You must manage (deploy, scale, and secure) the software yourself.
- May require domain learning.
- Availability of resources.
- It diverts your resources from other (potentially profitable) activities.
BUY/PARTNERSHIP
Why would you opt for the Buy option?:
- You are comfortable with handing control over to another.
- You have a strong relationship with the solution owner.
- You are comfortable with the solution’s quality.
- You don’t have, or don’t want the expertise.
- You don’t have the capacity to build it out (although this has some caveats).
ADVANTAGES
- If they are a specialist, they should be capable (at least from a domain perspective).
- The functionality (in the main) already exists.
- You minimise the financial risk if the solution is unappetising to your customers.
- Change, distribution, and evolution becomes another’s problem.
DISADVANTAGES
- You may sacrifice Control for features.
- The vendor’s feature-set may provoke arguments over ownership of value within your own organisation.
- The vendor may rank you lower in the pecking order than other competing customers.
- Consistency. It may not be possible (or practical) to present a consistent experience to your customers.
- Some integration effort still exists (see Functional Intersection). You may also be forced to wrap all interactions to support Evolvability.
- You may need to broach the subject with existing/potential customers.
- Ownership. Where does it stop? It’s not just development, it’s testing too.
- Reporting and business metrics. You may not have the detail you can get from internal business systems.
- GDPR - you’re now depending upon another system to manage sensitive information. You may also be required to indicate the partner system as part of the customer onboarding journey.
SAAS BUY IS MORE THAN MANAGEMENT COSTS
It’s easy to imagine the only costs of a Buy option - such as SAAS - only being the monthly management costs, but that's rarely the case. If you're integrating two systems together, you must pay for the integration work.
If there is a Functional Intersection, the only way to consolidate with an external partner is to reduce your own feature set; something most business owners would be concerned over. So, we end up with a non-consolidated mess.
REUSE LEGACY SYSTEM
Some businesses have several product iterations (if they’ve failed to Consolidate), which are often richer in functionally than their modern counterparts. It may be possible to reuse one of these products.
Why would you opt for the legacy option?:
- The functionality already exists.
ADVANTAGES
- Increased ROI on that legacy system.
- It’s a Known Quantity (whilst a new vendor/partner system may not be).
- It may be a better business fit than a vendor/partner solution.
DISADVANTAGES
Whilst this approach seems quite appetising (I’ve seen it used many times before), it has some fundamental flaws:
- Legacy system (probably) means Monolith, and that increases the likelihood of a Functional Intersection.
- There's no practical way to consolidate (Consolidation) the systems; the legacy is too old to be worth decoupling, the newer system can't lose features in favour of the legacy system.
- The legacy system has, in all likelihood, been built using technologies which are now viewed as antiquated and no longer supported; any changes to the legacy to support the new system translates into poor TTM (productivity, contention finding skilled resources, poor practices, long release cycles, unfriendly to the cloud), poor ROI (fine if your just using it as is, less so if you must change it), and Brand Reputation concerns (e.g. security vulnerabilities). You’re unlikely to want to invest in rectifying problems in a legacy system.
- Joining large systems together often results in increased complexity, which (due to Complex Systems), equated to reduced reliability and increased risk to Brand Reputation.
- Security vulnerabilities related to the legacy nature of the system; e.g. it's sitting on technology no longer supported and patched.
- Hybrid stack. This one's quite a challenge. You must manage two disparate technology stacks, treating it as one entity. Any attempt to use modern practices (e.g. continuous delivery) may be hampered by the legacy's lifecycle (months?). The lack of Uniformity also hinders understanding and causes Change Friction.
- More business coordination required. You're managing two disparate systems (and possibly teams), requiring a more formalised (heavyweight) project management approach.
- It revives the Legacy Mindset (e.g. Monolith, quarterly releases), and may also lead to others thinking this is acceptable behaviour when it should be discouraged (will it pollute the culture you've tried so hard to change?). We forget why we labelled it legacy in the first instance.
OPEN-SOURCE
The open-source solution has both similarities and differences to the other models. Unlike (for instance) a SAAS Buy model, an open-source solution is typically taken freely (including the source code) and deployed internally.
Why would you opt for the open-source option?:
- The requisite functionality exists, or most of it exists.
ADVANTAGES
- It's (generally) free.
- It can be modified to suit your needs.
- It's often been worked on by numerous persons, who vetted it (although there's still questions around this).
DISADVANTAGES
- The design and implementation technology are dictated to you; i.e. you might not have the skillset to understand (let alone modify) the source code.
- You're generally managing the software yourself, leading to the hybrid stack issues I described earlier.
- Many open-source solutions are no longer maintained. Whilst this shouldn't prevent you using the solution, it should raise questions about its suitability. Security vulnerabilities are the most obvious concern.
- Reliability and trust. Can/should you rely upon a solution that you may not trust? I suspect governmental bodies holding sensitive information shy away from software that they cannot guarantee the veracity for.
- What about licensing? Whilst most open-source solutions I've seen have royalty-free licensing, that's not always the case. You don't want to tightly couple your business to a solution only to later find you're liable for royalties.
- It may reopen the Consolidation question, along with product capabilities questions (i.e. if both systems do the same thing, which one do you keep?). This may lead to political infighting and cultural issues.
SUMMARY
Only you and your team have the context to truly understand the best solution for your needs. Consultants can offer guidance and advice, but in the end they haven’t lived and breathed in how your business (and it’s systems - both technology and practices) functions, and may not appreciate all of its nuances. As you see, the Build v Buy question is far more involved than outsiders may initially realise (we, as humans, tend to simplify things).
BUILD, BUY, DOMAIN SPECIALISTS, & CONSULTANCY FIRMS
I admit it, I'm a bit of a skeptic (and should watch out for Bias). But I think have good reason for it...
Repeatedly throughout my career I've seen work handed over to (supposed) specialists/experts, employed to provide a feature or level of service that there was no internal commercial appetite or capacity for.
Whilst it’s true that experts can offer good value for money, particularly when the domain is complex (managing tax springs to mind), or where they already have extensive experience and a stable product, I'm more skeptical of some big consultancy firms who take the work away then magically reappear months later with a (supposedly) highly scalable, secure, robust, testable, and maintainable (i.e. quality) solution.
Extensive experience does not necessarily correspond to a good, well-rounded solution (e.g. I’ve seen several cases where all the consultancy does is farm the work out to another unproven group of workers and expect the same result as if they were domain and technology experts; it doesn’t work like that I’m afraid) , and forms both positive and negative Bias and Perception.
FURTHER CONSIDERATIONS
- Functional Intersection.
- Consolidation.
- Integration Hell.
- Control.
- Antiquated Monolith.
ENTROPY
Everything suffers from Entropy. People (die), cars (malfunction), houses (fall into disrepair), the value of the words in this book (deteriorate, and lose context and meaning), empires (crumble), (supernovas destroy) the heavenly bodies, and software (degrades). Entropy even affects us if we do nothing.
Entropy in software can cause:
- Every change to be challenged (Change Friction).
- Evolvability and Maintainability challenges.
- Business slowdown (TTM, Agility), stagnation, and increased expense (ROI).
Entropy can’t be beaten, but its negative effects can be slowed; i.e. whilst death still comes, you have some control over the date of its arrival.
How may Entropy occur in software?:
- Waiting in Manufacturing Purgatory.
- Waves of new technology.
- Change.
- Architectural style.
- Failing upgrade paths.
- Doing nothing.
- ... any many others.
Let’s visit some of them.
MANUFACTURING PURGATORY
Remember, everything deteriorates over time. Not only is money lost the longer a work item sits in Manufacturing Purgatory (it’s unused, so there’s no ROI on it), but its value also deteriorates.
How can that be? I have two reasons to offer:
- Technology evolves extremely quickly. Something sitting unused, even for a few months, is potentially outdated with a more modern approach.
- Any important learnings about the value of a feature is impossible to glean because customers aren’t using it.
WAVES OF NEW TECHNOLOGY
(Some) New technologies make existing solutions seem mediocre by comparison. Cloud technologies are one example of this. Failing to embrace new technology may put your business behind the curve of your competition.
Consider the following. I once heard an executive opine that the technology team should “make a decision and stick with it”.
Whilst, in some sense, that executive’s reasoning was right; frustration was causing them to provoke a decision ahead of a vital deadline. At some point you must place a bet.
Yet there’s two sides to a coin, and Entropy is a strong influencer. Forcing everyone to live with a (unproven) decision for the foreseeable future, regardless of the other opportunities that appear over the horizon is demotivating, has a whiff of tactics rather than strategy, and may hamper Evolvability, Agility, and eventually TTM, ROI, and Brand Reputation.
CHANGE
Almost any form of software extension or maintainance (without a countering Refactoring phase) can increase brittleness and Assumptions, reduce reuse, and exacerbate Entropy.
When additions are made to an existing code base, we tend to add responsibilities. Even if we adhere to Single Responsibility, we invariably increase the assumptions that a unit encapsulates, lowering its potential reuse, and therefore introducing Entropy (e.g. if we can’t reuse it, we’ll find another solution, or worse, build another to perform a similar job, and thus, we’ve stumbled into a vicious circle of Entropy).
ARCHITECTURAL STYLE
Some architectural styles are more prone to Entropy than others. For instance, I’ve witnessed Entropy set in within an Antiquated Monolith, where Domain Pollution had taken center stage. The tight-coupling caused by an over-polluted domain made it practically impossible to make any form of change in a safe or efficient manner, causing poor Stakeholder Confidence, which lead to Entropy, and finally the product’s demise.
UPGRADE PATHS
Failing to undertake regular platform upgrades also leads to degradation and Entropy. The software applications we construct are built upon layer after layer of dependency strata; from the libraries and runtime engines we directly rely upon, which sit upon platform engines (like the Java Virtual Machine), which rest upon Operating System libraries, which communicate with lower-level device drivers onto the device/hardware, and eventually are pushed onto a network (if network based). See the figure below.

Typicaly Dependecy Hierarchy
Any one of these dependencies has a shelf-life, and may require upgrading (e.g. to support better performance, interoperability, security), or even replacement, during the application’s lifetime.
Fail to upgrade, and you (may) risk technical qualities such as Evolvability, Security, Productivity, and Scalability, as support dries up, leading to an inability to support the five business pillars I focus on in this book.
DOING NOTHING
At the start of this section I identified the “do nothing” scenario as another form of Entropy. To help contextualise this, I’ve drawn up the following analogy.
Imagine you are sitting before a grand piano. Upon the piano rests a musical piece for you to play. It’s a beautiful melody that, when played well, can take your audiences breath away.
You begin to play it, but something keeps distracting you, and now and again you strike a few wrong notes, or miss-time it. You hear a few polite coughs from the audience indicating some are aware of your error. The distractions continue, and it becomes increasingly difficult to keep time, to the point where the music suffers and the whole situation is unrecoverable. You stop, turn around, and watch the last member of the audience leave, shaking their head in muted disappointment.
Returning to the technology context, playing the musical score represents the product’s lifetime; whilst new technology, technology upgrades, or security patches, represent the key notes. The audience represents your customers. You’re the (supposed) maestro. See the figure below.

Doing Nothing
Note that these are examples of technologies/techniques that may represent significant events in your product's lifecycle; it doesn't mean they're appropriate to your context; that's for you to decide.
If you miss one note (or miss-time it), things seem askew, but only a highly knowledgeable audience (i.e. the informed customers) will notice it. However, miss (or miss-time) enough notes, and the music will sound so awful, that no-one wants to hear it (i.e. your customers will source an alternate service), and the situation is unrecoverable (at least for that product). There’s no way to catch up, Entropy has set in, and the product is visited by the Grim Reaper.
APPROACHES TO REDUCING ENTROPY
We may reduce software Entropy by:
- Refactoring (a technology term for regular servicing, as you might with a car).
- Following continuous practices (i.e. immediate feedback and pivots).
- Regular technology upgrades.
- Regular (re)assessments of current and future states.
- Sound Encapsulation techniques.
- Application of appropriate Granularity and Separation of Concerns practices.
FURTHER CONSIDERATIONS
- Manufacturing Purgatory.
- Refactoring.
- Assumptions.
- Change Friction.
- Domain Pollution.
- Antiquated Monolith.
- Stakeholder Confidence.
(the) MANY FORMS OF COUPLING
There are many forms of coupling. The one thing they all have in common is their ability to impede change.
Almost everything in our world depends upon others to perform responsibilities we cannot (or should not) undertake ourselves. This is particularly true within Complex Systems, which most software systems are. Coupling relates to how (and why) one entity makes use of (or is aware of) another.
A good understanding of the forms of Coupling supports engineers to make better integration decisions, increase ROI (e.g. by building longer-lasting systems), and protects Brand Reputation (e.g. increased reliability).
COUPLING & ASSUMPTIONS
Coupling comes in many forms (described later). At a more fundamental level, each form represents an (possibly incorrect) assumption (Assumptions) about the operating environment a system functions within. Coupling is a common cause of Change Friction.
In common parlance, Coupling is typically described as being either:
- Tight (coupling) - a strong relationship or bond, where impacting one party likely affects the other. This generally has negative connotations.
- Loose (coupling) - a weak(er) (or less permanent) relationship, where impacting one party doesn’t necessarily impact the other. This generally has positive connotations.
LOSS AVERSION
Tight coupling may occur implicitly or explicitly. The explicit form (where you assess risk and make a judgement call) has one advantage - the thinking described in Loss Aversion can invite discussions around loss, where we can suggest suitable forms (and levels) of Coupling under those circumstances, or deploy countermeasures; i.e. it’s proactive and extends Optionality, whilst the implicit form tends to be more reactive, and may limit Optionality. This Optionality can have considerable benefit when the sky is falling down and you must look to alternate survival tactics.
COUPLING CONSIDERATIONS
The figure below shows some considerations around Coupling.
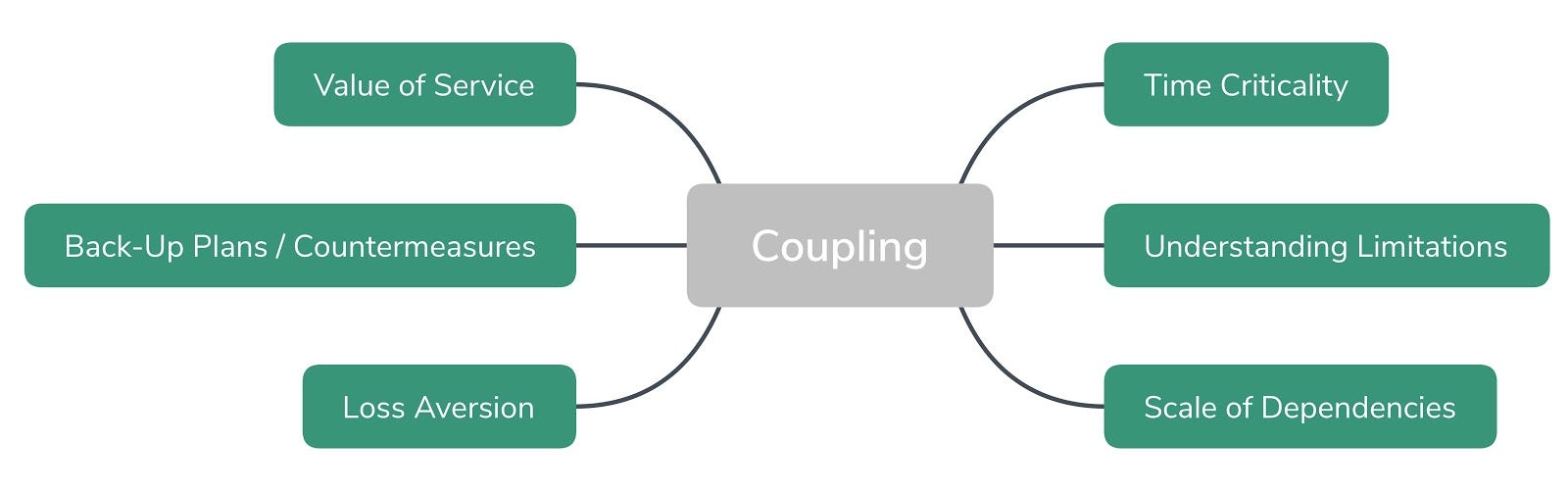
Note how several factors may affect any coupling decision, including:
- Service Criticality (or Value). If customers are unable to access any part of the service due to a downstream failure, what effect will it have on your customers, and business? Will customers notice, care, complain, and/or seek recompense? Where does it fit in the MoSCoW scale? For instance, Netflix has the ability to present static recommendation content if the personalised customer response isn’t reachable; therefore it has less criticality than some other functions, and falls within the MoSCoW camp.
- Time Criticality. Does your system depend upon the availability of another system during a critical period? Or is the service only offered ephemerally?
- Loss Aversion.
- Scale of Dependencies. Is the entity being used already heavily relied upon by many others? Change coordination across a single dependent can be very different to managing (say) ten.
- Understanding Limitations. By understanding a dependent’s limitations, you can (b) increase awareness, potentially provoking the means to resolve that limitation, even in solutions owned by another party, (b) counter those limitations by providing an alternative back-up plan/countermeasures (see next point).
- Back-Up Plans/Countermeasures. Once you understand limitations (see earlier point), you can anticipate the perceived impact of tight coupling on qualities such as Reliability. This allows you to deploy countermeasures to potentially harmful situations, and protect Reputation.
ACE UP YOUR SLEEVE
An ace up your sleeve, in times of trouble, is a great asset.
The ability to flip over (route) to an alternative system, or utilise a different approach (e.g. providing static content is better than no content personalisation at all) at the first sign of danger both increases Stakeholder Confidence and provides both you and your customers with a Safety Net.
I’ve witnessed several good demonstrations of the strength of this approach, and several examples where a potentially lucrative deal was soured by the lack of one.
A back-up system need not be polished, or feature-rich. That’s not it’s purpose. It’s there to provide Optionality, enabling a business to continue functioning whilst other parts of a system are crumbling.
We might use a back-up system in several circumstances, including:
- Inability to scale to high demand. Say your business is built to function from immediate feedback (i.e. the synchronous model). Reports, metrics, customer feedback etc all expect immediate feedback. That may be your default, all-things-are-going-well scenario, but your alternative plan may be to switch over to an asynchronous model in times of trouble (you might argue that’s how the business should always operate, but we might be dealing with established systems, processes, and cultures). Whilst this approach may not suit every business stakeholder, or customer, I suspect most would see its benefits when things really do go awry (and you can always switch back to immediate feedback once the spike is over).
- Insufficient testing. Cases where insufficient testing (particularly environment) can cause reputational harm (e.g. introducing a security flaw into a new system with no back-out plan).
- Replacement of a unreliable/unproven downstream partner system. If you depend upon a partner, but they are a cause for concern, then you may deploy a countermeasure and route traffic there if things don’t go well.
TYPICAL FORMS OF COUPLING
Typical forms of Coupling include:
- Technology.
- Static Parentage.
- Temporal.
- Internal Structure.
- Honeytrap Coupling (e.g. by feature or service).
- API Coupling.
- Coupling through Reuse.
- Version.
- Environmental.
- Legacy.
- Operating System and Hardware.
- Single Point of Human Failure.
- Working Style (e.g. Waterfall).
- Locational coupling.
Let’s look at some types of Coupling in more depth.
TECHNOLOGY COUPLING
Software that is tightly-coupled to a specific technology faces Entropy and Change Friction. This is problematic when new, improved technologies are released.
Technology Coupling has several subcategories.
FRAMEWORK/PLATFORM COUPLING
Some objects become inextricably tied to their overarching management framework. In some cases this places evolutionary challenges upon one of a business’ most important assets; their business logic (i.e. how the business runs, what makes it unique in the marketplace).
For instance, embedding both the business logic and the API-related (integration/transformation/routing) logic within the same software unit introduces a framework dependency (i.e. an Assumption) every time the business logic is needed, reducing its potential reuse, and (more importantly) hampering evolution to more modern (generally, better) frameworks.
DECOUPLING TECHNOLOGIES WITH DESIGN PATTERNS
Design Patterns such as Remote/Service/Session Facade and Business Delegate exist for good reason - they separate responsibilities or concerns (through layers/tiers, and Indirection), enabling the independent evolution of unrelated/competing concerns.
Tightly coupling objects to a specific technology increases the effort involved in replacing that technology, reducing technical flexibility (Evolvability).
COMPONENT/SERVICES COUPLING
Tightly-coupled software components cause similar issues to object coupling; i.e. it’s harder to change a component with many responsibilities/dependencies, due to Change Friction. Domain Pollution offers a good example, when components (domain concepts) become polluted by others, they suffer from tight-coupling, hampering change.
A similar strategy for decoupling objects can also be used to decouple higher-level components from one another; i.e. Single Responsibility Principle.
STATIC PARENTAGE COUPLING
This form of coupling is based upon static dependencies on a particular type in a hierarchy; i.e. inheritance in the Object-Oriented world (the child inherits all of its parent’s traits).
To my mind, compile-time coupling offers many benefits. Compilers identify syntactical correctness (using static type-checking), and warn developers of these problems in advance of program execution (a form of Fail Fast). However, it can also lead to inflexibility. For instance, Inheritance in strongly-typed languages (e.g. Java) creates a static dependency from child class to parent. Being a compile-time feature, we may find this tight-coupling hampers change, as we must force a single change through the entire software development life-cycle, even when there are alternative approaches (although we may find this less of a challenge with modern practices such as Continuous Delivery).
STATIC COUPLING & FLEXIBILITY
I can think of three levels of flexibility, typically around static, deploy-time, and runtime dependencies.
Static dependencies are less flexible (and reusable?) as they require full-lifecycle changes. Deploy-time dependencies are typically more flexible than the static counterpart because the source code remains inviolate in alternative contexts, only the configuration changes. Runtime dependencies offer the most flexibility/reuse, as environmental Assumptions are made late on.
The cost of increased Flexibility and Reuse is Maintainability. “Extreme configuration” can sometimes make code difficult to understand, or debug, and configuration that typically resides outwith the component using it may decentralise cohesive domain responsibilities.
Increased Flexibility is one reason to favour Composition over Inheritance.
TEMPORAL COUPLING
Systems and software units can be (and often are) tightly coupled by an assumption that the downstream dependent is immediately available and stable; i.e. there is a synchronisation expectation that both systems are online at exactly the same moment. This is temporal coupling; i.e. units are coupled by time.
Synchronous Communication is a well-trodden, and relatively simple integration style; yet it isn’t appropriate in every scenario (such as for long-running transactions, where asynchronous communication is favoured, or when the end user need not wait for a response; e.g. bidding on an item). Asynchronous integrations are a key mechanism to break temporal coupling.
BREAKING THE TEMPORAL BARRIER
Several key indirectional technologies/approaches are on hand to help break Temporal Coupling, including Queues & Streams (and even Shared Databases; although I don’t necessarily advocate that!).
Not only do these technologies promote Availability, Reliability and Scalability, they do so by decoupling one system from the imposition of a time constraint by another.
It’s also uncomfortably easy for a business to also couple themselves temporally. For instance, if the business offers its customers live events (e.g. streaming golf), they tightly couple their business model (and its success), to their ability to provide/service content to their customers within a short time window. Failure to do so risks Brand Reputation.
TEMPORAL COUPLING AT THE SYSTEM LEVEL
Imagine you’re building a software solution to - on a monthly basis - credit a customer account to allow them to redeem it on any item in the catalogue (e.g. a book, or DVD). Off the back of the original event, the system may perform a number of additional actions; e.g. if the item is of type stock, then mail it out. It’s entirely possible that each of these actions is coded to only complete after checking the validity of a date.
Let’s look at how we might wrap the logic in a code:
1. if(nextCreditDueDate after LocalDateTime.now()) { 2. creditAccount(accountId, 1); 3. }Line 1 is key. It compares a domain-specific date-time value (nextCreditDueDate) with the system’s current date-time (often representing the geographical region the machine is in). It is a form of Assumption; the code is coupled by Temporal Coupling to the present (e.g. LocalDateTime.now()), making testing extremely challenging.
Why? There’s no easy way to (system) test this path at runtime. For instance, what do you do if:
- You need to test what will happen to a specific customer’s account six months from now, when an offer expires?
- You must replicate a bug that occurred 78 days ago at 10.04 a.m? Accuracy with date/time may be critical to your business model; e.g. what happens to accounts with the 29th as the credit day, on Feb 29th of a leap year?
- You need to understand how the entire system should/will behave when the customer is due credit for three months (due to some other internal failure) and the logic above is executed? Will they get one credit, three credits, or will it fail with some peculiar error? Is that what should happen?
It’s unfair to expect a tester to set up test data to reflect the current date/time every time it’s needed.
Of course, it’s probably worse than that! A real system modelling a domain such as this, is probably strewn with logic of this sort. The impracticalities of building robust test data introduces the need for a time machine, enabling us to easily move time back and forwards to test out different scenarios. An alternative approach might be:
1. if(nextCreditDueDate after timeMachine.now()) { 2. creditAccount(accountId, 1); 3. }In this case, the date-time validation is managed by the timeMachine; a service that wraps identification of the current date/time, enabling it to be manipulated by a tester. This approach can then be reused across the system.
The end result is that we have removed our dependence on Temporal Coupling.
HONEYPOT COUPLING
The Venus Flytrap is a plant renowned for its ability to entice prey to it, before trapping and slowly digesting them. Whilst that’s a rather melodramatic example of my next form of coupling, Honeypot Coupling, maybe it serves its purpose.
HONEYPOTS IN INFORMATIONS SECURITY
A Honeypot is something seemingly of value that is presented in such a light as to entice the unwary (much like the Venus Flytrap). It’s used in the security industry to entice hackers, either to entrap them, or to learn from them (to harden internal services).
To me, vendor lock-in is a form of Honeypot Coupling. The concept is simple, yet very powerful, and has existed far longer than I’ve been in the industry. Draw your customers in by incentivising them with a service/solution/price they can’t get elsewhere, and then promote their tight-coupling to it. Once tightly-coupled, Loss Aversion (in this case, the pain of migrating to another) kicks in, so the customer must remain (whilst it’s possible that this approach increases technical Agility, it may hamper business Agility).
Some vendors are veterans of this approach. In the database arena, we might see an explosion of new features, or bespoke solutions, that (theoretically) simplify your life. From a consultancy perspective, you may find some consultants display a certain Bias towards their own products. There be dragons.
The danger comes not from a single tight-coupling, but from the repeated use of this pattern, in many places, over an extended period. For instance, embedding proprietary database mechanisms within a large (monolithic) codebase, limits Evolvability, due to an inability to migrate vendor (I’ve seen it). Injudicious, tactical, use may tie in the customer, and reduce their options (Optionality) to a binary outcome - continue using the technology/approach (cognisant that it further exacerbates things), or rewrite the entire stack (also unpalatable, particularly to the investors).
CAUTION, HIGH VOLTAGE
Whilst I may be being unfair to many vendors (customers can cause a self-inflicted Honeypot Coupling), I’ve seen sufficient examples to be cautious of some of their advice.
And now for something highly contentious; and I suspect many of you will disagree with me... but are we not witnessing a revival of Honeypot Coupling with the Cloud? As each provider vies for position, their offerings diverge, to the point that they truly become bespoke services that sacrifice Portability for ease-of-use etc. Even the same high-level service offerings (e.g. serverless, managed NoSQL databases) are sufficiently different to present problems.
Of course the services being offered have great merit (that’s why they’re so popular and hard to resist); for example, in their seamless integration with other vendor-supported cloud services, their relative cheapness, and a seemingly endless ability to scale etc.
But I return to my point on balance; with good, there’s also bad (and Tools Do Not Replace Thinking). My concern isn’t about whether the cloud is good or bad, but about the level of coupling some customers are (unintentionally) committing to. Going “all-in” is fine if you know what your getting. The simplicity with which new services can be provisioned/used/integrated may breed complacency - might we find the practice so effortless and convenient that we it spreads without really considering its ramifications?
They say that if you write for long enough you eventually contradict yourself... Whilst it seems like some Cloud providers desire a certain degree of coupling, the cause to a large extent lies elsewhere. Our industry is driven primarily by the forces of TTM, speed of change, and innovation. And the forces of Standardisation and Innovation often compete. Whilst Standardisation may protect you from Portability (and potentially Evolvability) concerns, achieving it is often protracted, hard-fought, requires significant cooperation, and is never guaranteed, which begets Innovation and fast turnaround.
As the saying goes, you can’t have your cake, and eat it.
HARDWARE & OPERATING SYSTEMS (OS) COUPLING
Whilst this book aims to look into the future, it’s important not to forget the past.
One of the first products I worked with when I entered the technology industry was a billing solution, built in C++, and supported across several operating systems (Windows, and several UNIX variants).
Each platform had its own linking requirements (C Headers), and a set of make files (a well-established build and dependency management), used to make a specific platform release (a set of executable code specifically for that Operating System). The lack of Operating System (OS) agnosticism added complexity (i.e. time and money) to the product’s development but was, in those days, a necessary, but Regretful Spend.
WRITE ONCE, RUN ANYWHERE
I still remember Java as a fledgling platform. One of its oft-touted key strengths was its (supposed) OS agnosticism (”write once, run anywhere”). Whilst, nowadays this is taken for granted, it was an important advancement.
Fact. Many established businesses still have (and support) legacy systems (Supporting the Legacy). Often, these legacy systems are tightly coupled, not only to a specific Operating System (and version), but sometimes to specific (antiquated) hardware - both may be discontinued and difficult to source/provision. This type of coupling may impede Evolvability, through technology stasis.
VERSION COUPLING
Becoming coupled to a specific version of a dependency is also a common problem. Examples include a specific technology (e.g. Java 6), an API version (e.g. v1.3 of the Customers API), and an Operating System (although this is less of a problem nowadays), application servers (e.g. JBoss). For instance, it’s common for Antiquated Monoliths to become tied to a specific version of an implementation technology, and due to Big-Bang Change Friction, it becomes impractical to undertake any form of technology migration, thus causing evolutionary challenges.
TYPE COUPLING
Poor assumptions about a type can also hamper change. For instance, consider the following example.
I was once involved in building a framework where someone had made the assumption that the return type for any resource identifier would always be a Long type (it fitted well with the primary key in the relational database world). For instance, a resource lookup might be:
https://services.acme.com/customers/23655This works (assuming you ignore the potential anti-pattern of leaking business intelligence data to the outside world; e.g. you now know how many customers the business has) if the underlying entity id is also a long. But this isn’t necessarily true in all databases; many NoSQL solutions, for instance, tend to use a UUID. It also hampers your ability to encrypt/decrypt this id as one form of securing data (around guessable values).
If we’d proceeded with the Long type, it would have hampered our ability to migrate to a NoSQL data storage, or use this type in the URL.
https://services.acme.com/customers/4995-3426-9085-5327However, by considering future evolutionary needs, we opted for a string type (which I still consider to be the right choice), allowing us to evolve when the time comes.
INTERNAL STRUCTURE COUPLING
Exposing internal structures creates a tight-coupling between the consumer and the internal structure, and may hamper Evolvability.
TABLE STRUCTURE COUPLING
As an increasing number of consumers become aware of an internal (table) structure, we find it increasingly difficult to make structural changes without affecting them. This may cause the following issues:
- Evolvability & Change Friction. You might want to modernise the database technology but you have tightly-coupled dependents.
- Performance & Scalability degradation. Direct coupling has limited our potential to introduce an intermediate caching facility. We might also serve to create overly-chatty consumers.
- Poor Reuse; workflow logic is duplicated in the consumers rather than encapsulated in some indirectional layer (e.g. facade), leading to rework, confusion around change, and additional coordination demands.
APIs can also become tightly coupled to internal structures (Consumer-Driven APIs).
INAPPROPRIATE STRUCTURE REUSE
This relates to using the same thing for multiple distinct responsibilities, and is a form of coupling through reuse. The Separation of Concerns section describes this in more depth.
COUPLING THROUGH REUSE
A pure Microservices architecture represents truly independent software units that aren’t affected by the lifecycle changes of other externalised units.
Quite a sweeping statement isn’t it? What it means is that - excepting any downstream dependencies on other services - a single change should not cause a large blast radius across a suite of microservices.
Unfortunately, reality and pragmatism also crowd these waters. Common/shared libraries represents the most obvious choice. For instance, most software units (such as a microservice) need other units to undertake a task, and often make heavy use of shared libraries.
The problem is that - like everything else - these libraries can change, thus (eventually) affecting all microservices reliant upon it (and breaking the microservice model of fierce independence); and your software may have a rogue dependency. Sometimes this rogue element can be alleviated through piecemeal deployments (one service at a time), but sometimes (e.g. when a critical security vulnerability is identified) it requires a Big-Bang/Atomic Release; i.e. we return to large, monolithic-style releases.
TO REUSE, OR NOT TO REUSE. THAT IS THE QUESTION
I’ve used the common library reuse approach to - for instance - hold a set of abstract software units (e.g. DTOs, uniform exception handling) that all microservices could use/extend. It enabled us to build Uniformity and consistency into a suite of microservices that (a) simplified integration, and (b) reduced TTM, due to the Low Representational Gap (LRG) stemming from a consistent approach.
However, I’ve also seen the impact of a breaking change (where every service needs updated very quickly). It isn’t some isolated development activity, but one that also involves testing, deployment and release, and all of the coordination typical of a Big-Bang Release cycle.
There are alternatives. For instance, you can duplicate the logic within each microservice, which tends to be the preferred stance for many; but this too seems impractical, breaks cohesion, and goes against (what I’ve always been taught as the best practice of) the Don’t Repeat Yourself (DRY) principle. You might also consider a shared service, which is consumed by multiple microservices, but that also raises concerns, particularly around latency and reliability. And it doesn’t always make sense depending upon what problem is being solved.
I’m not entirely sold on any approach here. They all have failings, and I suggest you apply common sense when choosing the reuse model.
NAMING/DATA/CONVENTION COUPLING
Consumers may also become tightly-coupled to a volatile variable name, key, or convention. For instance, consumers may make assumptions about:
- A global variable; e.g. it exists and contains certain values.
- A key stored in memory; e.g. a HTTP session variable.
- A convention; such as all input values being in lowercase, or all uploaded image files being of .png type.
The more consumers using that particular variable/convention, the more Change Friction occurs.
EXAMPLE - CONVENTION COUPLING
I once worked on a UI proof-of-concept that used JavaScript to display viewable assets to the end user.
The user could navigate through a catalogue, be presented with the name, description, image, and price of a selected asset, and then purchase it.
Deadlines were tight, so to allow us to focus on more business critical issues, the team embedded (what was considered) a harmless rule into the code, creating a coupling between the asset title and the image file name to look up (Assumptions). For example, an asset title of “Resilience is Futile” should always have a corresponding image named “resilienceisfutile.jpg” (note the other assumption mandating the file type to always be a jpeg?). The image would not be presented if either rule failed.
At one stage - immediately prior to a big demo in the next few days - all of the images were cropped, a new banner added, and then the files were renamed and converted to the .png image type. The work was undertaken by someone outwith the team, who was never informed of this assumptive “rule”, subsequently committed the files. Unfortunately, we were left with only two equally unsavoury options:
We chose the latter, and it cost us a few very long days of diverted effort. It just goes to show how a seemingly insignificant form of coupling can have a significant downstream impact.
- Rename and change the type of every single image file to marry up with the expected title, even though we now understood how damaging our assumption had been.
- Remove the (recently discovered) poor assumptive rule, and introduce some flexibility, enabling us to link an asset to an image in a more manageable way.
CONSUMER BUSINESS PROCESS COUPLING
In the section entitled Internal Structure Coupling I described how consumers can become coupled to the internal structures of a system, causing Change Friction.
However, it’s also worth describing that consumers may also become coupled to a specific business flow(s). For example, in an order-processing domain, consumers may build software that expects a specific flow and sequence to how it is processed; e.g. you must interact with X, before Y, but after Z. How sales tax is calculated within different countries offers us another example. Whilst UK citizens tend to get a more static form of goods tax applied, US citizens may have several tiers involved in a tax calculation, suggesting either that more information needs captured up-front, or that tax calculations must be performed Just-In-Time (immediately prior to the sale). This may well affect a customer on-boarding flow, and thus, we should consider how/what we couple to it.
The problem with this approach is in its potential brittleness. If you wish to change the sequence in which those actions are performed - possibly because you need to add some additional up-front validation - then you must coordinate change across every consumer. Not only might this be a significant coordination task, but not everyone will undertake the work.
FACADE
Facade is a good example of a Design Pattern that hides workflow complexity, and may aggregate and transform data into a form suitable for consumption, with a highly reusable mechanism that promotes the Don’t Repeat Yourself (DRY) principle.
When consumers (e.g. UI) become overly familiar with a business workflow, Evolution may suffer. This lack of flow Consolidation can lead to:
- Duplicated workflow across multiple clients, increasing the likelihood of bugs.
- Rework, when those bugs are found.
- Latency issues. We expect (remote) consumers to interrogate APIs to aggregate data, rather than executing that operation closer to the APIs/data source(s).
- Limited caching opportunities; e.g. we might use more caching techniques nearer the source, but we can’t.
- Data validation is promoted within the consumer, rather than in both consumer and the APIs; I’ve heard this argument numerous times but protecting against XSS and injection threats solely inside the consumer is not a secure practice.
- Reputational harm (if external parties have bound themselves to your flows and they must change).
LEGACY COUPLING
Legacy Coupling is a common problem for established businesses embarking on a major system replacement. A common problem is how you successfully manage existing customers on existing (legacy) systems, whilst also supporting the construction and use of its modern replacement in parallel? Obtaining functional parity in the new solution (i.e. replicating the same level of functionality in the new system as is currently supported in the legacy system) may take years. Thus, the temptation to couple from new to legacy, like so:

This coupling has some benefits (e.g. functional reuse), and many potential pitfalls, mainly by being constrained by the legacy system; e.g.:
- Scalability. Many modern systems require “web scale”; e.g. millions of requests per hour. Legacy systems don’t tend to offer this capability (it wasn’t needed in the pre-web days), so how can you satisfy that need whilst coupled to this legacy system?
- Availability, Resilience, and Reliability. Most legacy systems weren’t built on modern Cloud Native principles (the cattle, not pets mantra), so may not suit modern expectations.
- Security is only as good as the weakest link, and a legacy system’s security may be impeded by a lack of patching/support.
- Releasability. A legacy system often (but not always) equates to an Antiquated Monolith architecture, and that suggests Lengthy Release Cycles. Tying a modern system and practices to one with Lengthy Release Cycles suggests slower TTM and poorer ROI.
See the Working with the Legacy section for more on this subject.
SINGLE POINT OF HUMAN FAILURE
“If not controlled, work will flow to the competent man until he submerges.” Charles Boyle, Former U.S. Congressional Liaison for NASA.
The notion of coupling important skills and knowledge onto one individual (or even a single team, in some circumstances) is a dangerous practice. The Phoenix Project summed it up well with Brent - an individual with so thorough an understanding of the domain that it forced almost every significant change (alongside problems and decisions) through him; i.e. these individuals become the “constraint” within the system.
TEAM/PARTNER COUPLING
I’ve also witnessed team coupling; where one team(s) makes assumptions about the availability of a service or feature being built by another team (such as basing your own delivery dates upon another team’s delivery), only to later find that the dependent team’s focus has shifted, and the feature is either no longer available, or is significantly delayed.
The same situation can occur with partnerships - relying on a partner to deliver features on schedule may harm your own reputation in the eyes of others (Perception) if they fail to deliver.
Let’s say we have a small start-up organisation, consisting of Alice, Mo, Stacy, Etienne, and Patrick. I’ve used their avatars to demonstrate how the interaction might work. See the figure below.

Stacy is key here. She is by far the most knowledgeable and experienced, understanding the ins-and-outs of the system. She also makes all major decisions. Naturally, any significant work should be undertaken by her then? Not necessarily.
HUB-AND-SPOKE ARCHITECTURE
The Hub-and-Spoke integration architecture follows the same model that is described in this section (a centralised single entity) that all others interact with. It also suffers from the same problems; the hub becomes highly coupled and overloaded.
When one individual (Stacy in this case) is the sole communications and decisions hub that the entire business must pass through, to undertake any significant piece of work (e.g. domain expertise, technology expertise, decision-making on spend), then we subordinate, undermine, and enslave the entire system (the business system, not the technical system) to the capacity (and availability) of that individual, creating a tight-coupling from the business to that individual.
RELIANCE
Relying upon a small number of people can be very frustrating. If you need something done quickly (such as making a potential employee an offer), and there’s only one person who can sign it off, you are at the whims of that person. In the case of temporal criticality, such as making a candidate a timely offer before a competitor, this reliance is problematic.
Enslaving the entire business to a single domain expert may:
- Couple any further work in that domain to them (i.e. sacrifice parallel activities).
- Force the acceptance of far longer delivery timelines (i.e. we sacrifice TTM), as we await the availability of the individual.
If that individual becomes unavailable to work (e.g. stress through overwork), accepts another job offer, or they simply have no capacity (likely to cause Expediting), trouble is brewing. The less scrupulous may also capitalise on this tight-coupling (favouring the individual) by dictating their terms upon the business (e.g. dictate their new salary expectations).
Worse, because we now have a single (centralised) constraint, there’s a far greater likelihood of Expediting; where that individual is constantly pulled between pillar-and-post to meet the next most important work item (which constantly shifts), and is highly inefficient (due to Context Switching).
SINGLE HUMAN POINTS OF FAILURE IN FINANCE
Banks and other financial institutions mitigate Single Point of Human Failure, but for other reasons. Many mandate a practice of “forced” two week holidays on some individuals, to protect themselves against fraudulent activities.
During this holiday, those duties are taken on by another individual, who - by logical extension - must already be sufficiently versed to perform them; i.e. more than one individual can do the role.
The main techniques to counter this problem are all collaborative; e.g. Pair Programing, Mob Programming, and Cross-Functional Teams.
LOCATIONAL COUPLING
In 2017, Amazon Web Services (AWS) suffered an outage, in part, as a large number of S3 storage services (subsequently affecting some other AWS services) became inaccessible at their US-East-1 region. Downstream, it also affected a significant number of (some high profile) AWS customers; in some cases causing their own service disruptions.
In this context, whilst the initial cause is relevant (mistakenly re-claiming more servers than desired), it’s the downstream dependence which is far more interesting. Reports indicated that some of those who depended upon the services had failed to (successfully) embed sufficient regional redundancy into their practices/solutions, and were unprepared for the failure (thus, the wider consequences); i.e. some customers were tightly coupled to a specific region. Interestingly, Amazon's own retail website didn’t seem to be affected, indicating their agility to spread their own infrastructure across multiple regions.
This type of Locational Coupling can also occur at a more product-oriented level; e.g. products built to satisfy a specific geographical market, or zone, that struggle to support a more global, multi-tenant model typical of modern SAAS. Software won't miraculously support any of these concepts; typically, they need careful consideration, and are foundational aspects (i.e. neglecting them early on, makes them increasingly difficult to support).
From a non-functional geolocation perspective, Performance is a challenge (i.e. how you deal with the latency concerns where the infrastructure is global, but the master data store is centralised). But that's only the beginning. Consideration must also be made for (to name a handful):
- The textual presentation of different languages (e.g. US English, German, Cantonese).
- The regional date/times, particularly when customer accounts are driven by them (e.g. crediting an account in Denmark and Brazil occurs at a different point in the day, even when they are the same time).
- Currencies (decimal places, commas instead of periods etc).
- Sales tax. US sales tax is complex and can be multi-tiered, whereas UK sales tax is more static (and approachable). It's therefore feasible to present the entire cost (including up-front sales tax) to UK citizens, with less buyer information available.
- In a global organization, with multiple business units, a single-tenant model is highly inconvenient as business intelligence is strewn all over the place.
WORKING STYLE
Whilst much of this section relates to system coupling, it’s maybe obvious now that there are many other forms. For instance, a business can quickly become wedded to specific practices that can be extremely difficult to change, particularly when we consider that introducing cultural change is much harder than technology change.
Many of you may have already experienced this? For instance, have you ever worked in a business undertaking a transition from the Waterfall methodology to Agile? Painful, isn’t it? Inculcation Bias has polluted the entire business, and influencing sufficient (and key) persons takes significant cognitive strain. And in general, the larger the business, the more Change Friction.
An ever-increasing Circle of Influence is one solution to breaking down these barriers.
SUMMARY
Promoting a loosely-coupled software solution may seem an obvious choice, but there is (as always) a counter argument. Whilst a loosely-coupled, highly-distributed solution promotes Flexibility, Scalability, Resilience, and a few other qualities, it may also increase complexity in the management, development, and testing of the solution. Everything in moderation as they say...
The type of coupling you opt for (and that includes implicitly) can have significant ramifications. Tight coupling may prevent evolution, whilst loose coupling tends to increase complexity.
Given an easy or hard path, most humans will inevitably choose the easy path. This generally involves reducing layers (which are often viewed as an unnecessary complexity), overloading assumptions in software units, and thus, actually creating a tightly-coupled solution. When change must occur, or support multiple solutions, you may have a major refactoring on your hands.
When coupling, also consider scaling. Remember the Convention Coupling scenario I described earlier, causing several days of unnecessary rework? Whilst this form of coupling was satisfactory for a small number of cases, the problem spiralled with scale, to the point that it caused significant impact.
To finish off this section, I’ve included a few other coupling scenarios that might catch you out:
- Coupling Business Intelligence to a transactional database may cause Evolvability challenges (Real Time Reporting).
- Overloading environments with too many responsibilities, particularly when you mix fast and slow-paced change together (or unstable with stable). A good example is conflating product demo and dev/test concerns in the same environment.
FURTHER CONSIDERATIONS
- Queues & Streams
- Assumptions
- Inculcation Bias
- Cross-Functional Teams
- Context Switching
- Expediting
- Hub-and-Spoke
- Antiquated Monolith
- Lengthy Release Cycles
- Separation of Concerns
- Consumer-Driven APIs
- Change Friction
- Domain Pollution
- Indirection
- Complex Systems
- Regretful Spend
- Real Time Reporting
- https://www.theregister.co.uk/2017/03/01/aws_s3_outage
TECHNICAL DEBT
One of the primary technical inhibitors to business growth and evolution is Technical Debt. It is a collection of debts, at the technical level, accrued through both sound and unsound reasoning, that are never resolved (“paid back” in debtor parlance), causing longer-term business ramifications that may affect Sustainability, Agility, Reputation, and TTM.
BAND-AID DEVELOPMENT
Technical Debt causes us to employ a “band-aid development methodology”, where unnecessary, unproductive, and overly-complex work become the norm, often without people realizing its cause.
Technical Debt is a natural and everyday occurrence in all areas, and even the cleanest of solutions accrues debt. These debts may (for example) stem from:
- An unwillingness to undertake regular technology migrations/upgrades/patches.
- The poor selection of an inappropriate technology, framework, architecture, or design.
- Poor encapsulation practices (e.g. causing Domain Pollution).
- Inappropriate foundations or techniques; e.g. the software product is built upon a set of poorly grounded foundations or (sloppy, unsustainable) techniques.
- The tight coupling of many units to a flighty, changeable dependent.
TECHNICAL DEBT EXPERIENCES
My past interactions with many business executives towards Technical Debt have been far from positive.
Some execs hadn’t heard of it, or didn’t understand it (“Only if we understand, can we care. Only if we care, will we help.” - Jane Goodall); however, the ones that concerned me the most treated Technical Debt like it was a chimera, invented by technologists to excuse poor quality, or the inability to meet their TTM expectations. Whilst their businesses faced a deep, intractable Entropy, and the strangling of technical and cultural innovation, they remained stalwart in their unwillingness to entertain its existence.
Incidentally, whilst I believe that the main cause of business stagnation at a particular point in time may indeed be Technical Debt, it is not necessarily the root cause, which often occurs much much earlier but is repeated over a sustained period. In many of the scenarios I’ve encountered, the root cause is organisational and cultural, not technical - either through highly reactive business practices (Cycle of Discontent), or (occasionally) neglect. Both lead to Technical Debt, and subsequently to stagnation and an inability to satisfy demand.
Again and again I see this cycle at play, often with very serious ramifications. To me, an unwillingness to even entertain the possibility of Technical Debt is grounded in fallacy and smacks of Cognitive Dissonance.
Being (potentially) subjective (Quality is Subjective), it may seem like some quality-affecting decisions are unimportant and can be made with little consideration. For instance, removing layers from a system to deliver a UI more quickly by directly interacting with a database (a form of technical expediting), may seem relatively innocuous, but it can have more insidious long-term ramifications (it tightly couples the UI to the database, and hampers Evolvability, Scalability, and Reuse, to name a few).
TECHNICAL DEBT ANALOGY
To me, the best analogy to describe Technical Debt is represented by a ball-and-chain that is tied around your (and your business’) ankle.
“A ball and chain was a physical restraint device historically applied to prisoners, primarily in the British Empire and its former colonies, from the 17th century until as late as the mid-20th century. A type of shackle, the ball and chain is designed so that the weight of the iron ball at the end of the short chain restricts and limits the pace at which its wearer is able to move, making any attempt at escape much more difficult.” [wikipedia]
Initially, the ball is small and light; whilst annoying, it is still easy to move around with and you remain pretty nimble. However, as debts grow (without any sign of payback), so too does the ball's mass and weight (they represent the size, or significance, of the debt), constricting any movement you/your business makes. With sufficient inaction, the ball eventually becomes too weighty and bulky, representing you/your business inability to move (you are now a prisoner to Technical Debt). Business change and direction is now dictated to by technological practicalities (i.e. the Tail Wags the Dog), and the business faces some tough choices.
Technical Debt can be both hard to quantify, and can be a slow burner (i.e. typically, its effects are witnessed over a longer period), so finding objective, quantifiable evidence (the sort that might throw a dark shadow upon this practice) is hard to acquire. Yet, that’s not a good excuse to ignore it. It is everyone’s duty to understand Technical Debt, and not to simply dismiss it as a chimera.
FURTHER CONSIDERATIONS
- Domain Pollution
- Inappropriate Foundations
- Cognitive Dissonance
- Entropy
- Functional Myopicism
- Quality is Subjective
- Refactoring
SEPARATION OF CONCERNS
Whether at the method, or the system level, different software units have different responsibilities (or concerns). Separation of Concerns is a conflation of multiple distinct responsibilities, concerns, or duties that have no right to be so closely linked/grouped.
INAPPROPRIATE REUSE
Some forms of Reuse (there are several forms, some less appreciated than others) are enticing, and hard to argue against. These forms of reuse drive us towards solutions that seem to work, but may actually lower the software’s longer-term value.
One example I regularly see around inappropriate reuse is the overextension of an entity’s responsibilities. Entities are software units that (typically) represent a persistable domain concept (i.e. they model a domain concept), such as a customer, a consumable credit, or a purchasable asset. They are normally distinguishable in code by their ORM (Object Relational Mapper) annotations (ORMs manage the mapping between the relational database world and an object-oriented model).
Unfortunately, I regularly see entities used in inappropriate ways, typically to conflate two responsibilities of a persistable entity, but also to represent a transferable, externally consumable object within APIs. The figure below represents a typical flow of data from a consumer’s API request, into the database, and then the routing of a response back out.
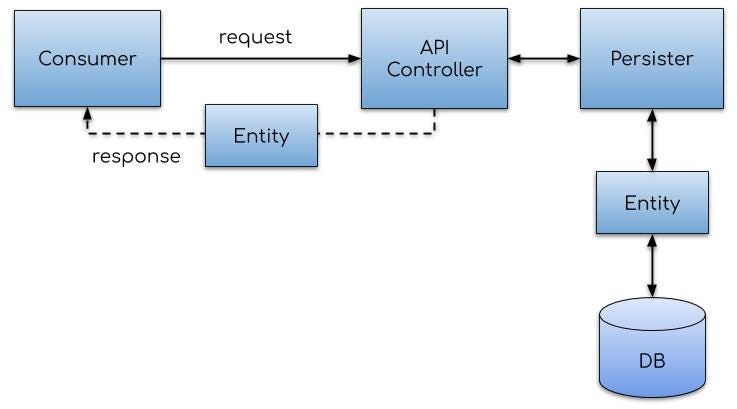
This Entity is overused, having dual purposes:
- To represent a data model concept in a relational database, and,
- To represent a response that external consumers can use.
This overextension of responsibilities may lead to the following issues:
- Domain Pollution and Evolvability challenges - one unit’s responsibilities bleeds into another’s, hampering change (Change Friction).
- Security concerns; e.g. we expose too much information, or information of the wrong type.
- Flexibility and Business Agility challenges; e.g. we can’t react to pressing business concerns.
Consider the following case.
Let’s say you’re building an API to manage customer information through your website. The website captures several key pieces of information about the customer during registration, including name, and (in some cases), a social security number (SSN). The SSN is highly sensitive, and is used to integrate with governmental services to (for instance) confirm entitlement to a state pension. Once captured, the system only needs this information to undertake internal irregular business-to-business (B2B) operations with that governmental body.
The Customers table might look like this.
| ID | FORENAME | SURNAME | SSN |
| 10010 | Bob | Hope | 4433-1992-4912-6859 |
| 10011 | Diane | Blazers | 6109-5182-0062-8719 |
| ... | ... | ... | ... |
The software entity representing the customers table might be:
@Entity(table="CUSTOMERS")
class Customer {
Long id;
String forename;
String surname;
String ssn;
}We reuse this entity for all persistence actions; i.e. read, create, update.
Let’s say we identify a new requirement, to present the customer with a user-friendly welcome message (e.g. “Welcome back Bob Hope”) when they successfully log in. The development work involves a change to the Customers API to retrieve the customer information for presentation.
The developer analyses the code for some representation of a customer, and finds it - the Customer entity, already built for persisting customer data. Some basic questions may be asked, such as:
- Does it fit the business requirement? Yes. It contains everything needed to satisfy the earlier requirement.
- Is it quick to deliver, thus meeting my manager’s TTM and ROI expectations? Yes. We're using what’s already there.
Sounds like a winner, doesn’t it? So, the developer opts to reuse the Customer entity for this solution. The figure below represents the solution design for customer lookup.
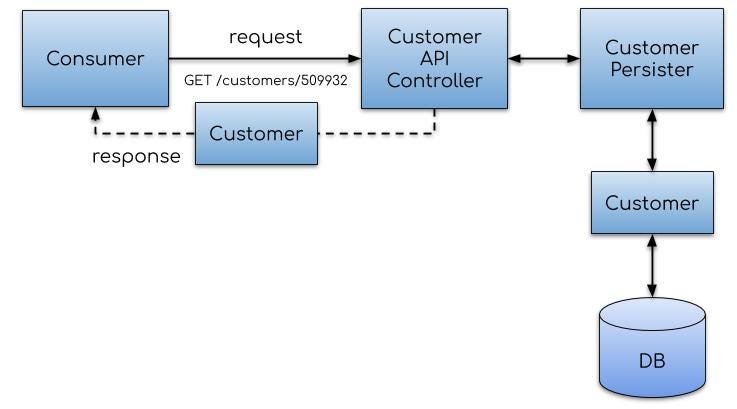
Next, we hook up a front-end UI, so that on a successful login (i.e. call of the Customer API), the following type of response is returned.
{
"forename": "Bob",
"surname": "Hope",
"ssn": "4433-1992-4912-6859"
}This solution functions, meets the business requirement, but does it satisfy all of our business needs? I say no. Let’s walk through why.
Firstly, let’s discuss the data returned. The forename and surname fields are suitable for this use case (and will be presented in the UI). The ssn field though, is less so. SSN is an internal system field, for internal B2B communications, and not meant for external consumption. Exposure of this field, for even a short time, could have undesirable consequences:
- It is bleeding potentially sensitive data, in an unencrypted form. Of course, if it must be returned, it should have been encrypted, but even still, it’s quite feasible that the database performs this task, decrypting it prior to the application tier, and still leaving us to expose it as unencrypted data.
- Being an optional field, it’s possible that testers miss the need to test this scenario, particularly if different UIs consume those fields for different purposes.
- It also allows (potentially many) consumers to couple themselves to this field. And once they’re coupled, then we’re resigned to the prospect of reduced Evolvability.
EXTERNAL EXPOSURE, EVOLUTIONARY CHALLENGES
I can’t stress this enough. Once information is exposed to API consumers, evolution becomes increasingly difficult - it's hard to know who’s using which fields, or who’s not.
And once consumers become tightly coupled to a field, we find change without a breaking change extremely difficult. The outcome... we tend to avoid the pain by not making the change. And the outcome of repeating this pattern leads to polluted APIs, and poor comprehension, to the point that external consumers find integration unpalatable. Thus, we’ve self-inflicted Entropy upon ourselves.
There’s another aspect of Don’t Expose Your Privates to consider here. Let’s say - for whatever reason - the business changes its mind, and decides that they do want to return the social security number. However, they dislike the name “ssn” for external API consumption, and instead suggest “socialSecurityNumber”. That's rather unfortunate. Putting aside any potential existing external coupling coordination issues, without undertaking a refactoring disproportionate to the simplicity of the requirement, and a retesting exercise, you can’t make this (seemingly) straightforward business change.
This problem also demonstrates the power of a top-down Consumer-Driven APIs model over its lesser substitute (top-down over bottom-up), which is the approach we started with in this chapter. Rather, if we had begun with the top-down, consumer-driven model, we would have (a) never exposed any version of a social security number, and (b) when the time came, provided the ability to name the socialSecurityNumber variable in any way the business desired.
SYSTEM 1, AFFECT HEURISTIC, & SEPARATION OF CONCERNS
Mindset is another important consideration here, as it may affect how we reason out Separation of Concerns.
Modern industry has inculcated into our fabric a desire (nay, a demand) for fast turnaround; i.e. there is a natural Bias towards TTM, often forsaking other qualities. From a development perspective, this bias may promote a “convenience through reuse” mindset over alternative strategies.
Humans will naturally favour the easier route if it seems to offer the same outcome or value. However, it’s only a half-truth to suggest that the “convenience through reuse” approach offers faster turnaround than the alternatives.
For instance, the base example I use throughout this chapter only satisfies an immediate TTM gratification (which often seems to influence a (unnecessarily) large proportion of businesses); i.e. longer-term sustainability may be sacrificed for short-term convenience. Consider, for instance, whether the other non-functional, business-impacting, qualities like Evolvability, Agility, Security, and Brand Reputation are truly represented here? Whilst it may seem unlinked - how can such a small change have such a large impact? - it’s the sustained practice of this approach that’s problematic. I regularly see the convenience of System 1 thinking (or Affect Heuristic) overriding the more strategic System 2 thinking, which might force the application of further logical reasoning to the assumptions which are answered through convenience. [1]
I’ve witnessed this same System 1 Thinking within product sales negotiations, where a deep desire to reuse an existing feature (for a dissimilar and inappropriately unrelated intent) to make a sale can have a lasting detrimental effect on a business. In this case, I suspect a mix of convenience and elation (to find a solution, any solution, to the customer’s needs, in a timely fashion, rather than finding the right solution), strongly influence our System 1 mindset; the notion of an Appropriate Fit resonates, even when there isn’t one. This mindset downplays due diligence (there’s no need to understand the consequences… is there?), and since Technical Debt can be both hard to quantify, and slow to realise (typically, its effects are noticeable over an extended period, not immediately), finding objective, quantifiable evidence (the sort that might cast light upon this dark practice) is hard to come by. Thus, technical stakeholders have a hard time influencing their corporate counterparts.
All-in-all, I think it a false economy.
All of this because we overburdened a single software unit with multiple competing responsibilities; i.e. we neglected Separation of Concerns.
SEPARATION OF DUTIES
Whilst I’ve used the Entity v DTOs scenario to present Separation of Concerns, the principle applies to all levels of a system (from low-level operation, to grand architectural scales), and even to a business.
Separation of Concerns at the personnel level is more commonly known as Separation of Duties. In the technology world, examples include the types of developers, testers, and operations who have very well defined duties, and rarely deviate from them. This approach has advantages and disadvantages; see Specialist v Generalist.
FURTHER CONSIDERATIONS
- Microservices
- Consumer-Driven APIs
- Specialists v Generalists
- [1] - Thinking, Fast and Slow: Daniel Kahneman
INDIRECTION
“All problems in computer science can be solved by another level of indirection.” [David Wheeler]
“Most performance problems in computer science can be solved by removing a layer of indirection” [unknown]
Indirection is one of the most useful (and simple) techniques in a software engineer’s arsenal. It is a powerful technique for decoupling software units by introducing a layer between two existing units/layers, enabling the introduction of new behaviour, without directly impairing the existing units. See the figure below.

Indirection removes direct coupling between units and promotes:
- Extensibility. Facilitates functional extension that belongs neither in the client or target. Logging, metrics, transaction management, and remote method invocations are examples of cross domain responsibilities, viewed as “plumbing” logic, that should not pollute (or be tightly-coupled to) business logic. Aspect oriented programming is a popular solution for this problem.
- Modifying a target interface to meet client interface needs. This is useful when the target’s interface cannot change, possibly because others are already tightly coupled to it, or the target is outwith your control (Control).
- Encapsulate technology specifics. Ensures client and target can successfully communicate without embedding a technological coupling within either party. This facilitates the use of different technologies that can be easily extended, and promotes Evolvability.
- Encapsulation of code or design complexity. You don’t always want clients/consumers to know of complex interactions, or design choices. By ensuring clients remain decoupled from the how (or even the order that tasks are undertaken) something is done, we promote evolution, increasing our Optionality.
INDIRECTION IN PRACTICE
Indirection is a fancy name for “wrapping”. Almost anything can be wrapped; for instance:
- SOA’s idea of reusing legacy systems by abstracting them away used Indirection. Ok, we probably now view “hiding the legacy” as an anti-pattern, but the sentiment was good, and it wasn’t the fault of Indirection.
- A Load Balancer acts as a layer of Indirection between consumer and web server and promotes (horizontal) Scalability and Availability/Resilience.
- The Java Virtual Machine (JVM) is a (well considered) platform agnostic “wrapper” above Operating System (OS) libraries, that abstracts away the complexities of the OS software the application is executing on.
- Queues are a form of Indirection (they are a Holding Pattern). They create a bulkhead between two systems, which is particularly useful if those systems work at different speeds.
- Gateways/Edge Services use Indirection between (external) consumers and a (internal) consumable resource, such as an API. They are often used to unobtrusively inject “plumbing” logic (like authorization or metrics) into a solution.
- Enterprise Service Buses (ESBs) introduce a layer of Indirection between consumer and target(s), and are often used to manage complex workflows and transactional logic in a request lifecycle.
- The Hub-and-Spoke Integration Architecture, where the Hub is the indirectional technique.
Indirection can, under the right circumstances improve Reuse, Flexibility, Maintainability, Extensibility, and Evolvability.
Indirection can be grouped into the following (discussed next):
- Behavioural Extension.
- Interface Modification.
- Technology Encapsulation.
- Complexity Encapsulation.
BEHAVIOURAL EXTENSION
Indirection is commonly used to add behaviours not necessarily belonging to the client or target. These behaviours are typically added without direct awareness of either party. This solution promotes Reuse and Flexibility by reducing coupling (e.g. Assumptions); making each unit available in more contexts, or switching behaviours with relative ease. See the figure below.
The Proxy and Decorator design patterns are canonical examples of the approach. Proxy uses indirection to add logic to determine whether to call a target. Whilst Decorator attaches behaviour(s) to the target behaviour, increasing its level of functionality without pollution.
INTERFACE MODIFICATION
Indirection is also useful for changing a target interface. This is often called “wrapping”. See below.

Wrapping enables the wrapped target to be utilised even when its interface does not match one expected of the client.
The Adapter and Mediator design patterns use Indirection to modify how an interface looks. Clients utilise a target service (by applying Adapter or Mediator), even if the target does not match what is expected. Whilst Adapter modifies the target interface to match one expected by the client, Mediator modifies both client and target interfaces, enabling a two-way, “mediated” communication between them (Hub-and-Spoke is a form of Mediator).
TECHNOLOGY ENCAPSULATION
Indirection is also useful for technology encapsulation. See below.

Flexibility is a key architectural concern for many enterprises (it can promote Sellability, for instance), and technology independence often drives it. Indirection promotes loose coupling; enabling technologies to be more easily interchanged. The end result? Better Evolvability, an extended product lifetime, and thus increased ROI.
The Business Delegate and Service Adapter design patterns are examples of Technology Indirection, encapsulating EJB and Web Service technologies respectively. And whilst I’m not a huge advocate of this approach, I’ve also seen solutions that wrap legacy SOAP APIs with a REST equivalent to satisfy external consumers, which is a form of Technology Indirection (I’ll let you figure out why wrapping SOAP with REST, devoid of any deep thinking, might not be a good practice).
Technology Indirection also promotes target reuse by reducing assumptions in the target; see below.
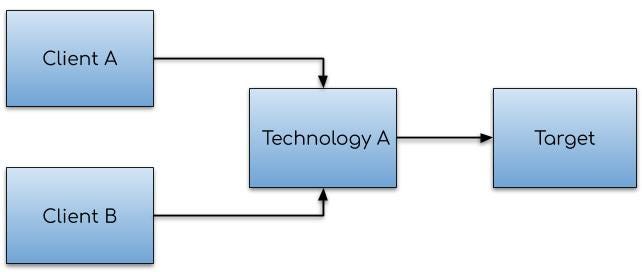
The target is currently only available to clients through Technology A. Yet the target remains technologically agnostic, enabling us to wrap it with other technologies, without pollution. See below.
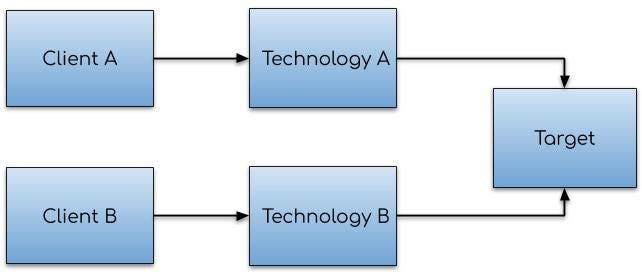
COMPLEXITY ENCAPSULATION
Some implementations may be so complex that understanding is almost impossible (e.g. it’s too complex to be read in isolation). Indirection can be useful here - by moving the complexity into another layer, we can reduce code complexity and promote Maintainability. See below.

There’s a secondary reason that you might consider this solution. It can also be used to hide embarrassing design decisions that would hurt your Reputation if they were exposed to external consumers.
The Facade and Session/Service Facade design patterns are archetypal solutions that hide the complexities of subsystem communication through a layer of indirection. They also promote Reuse, enabling different clients to utilise the same Facade functionality without polluting them by embedding the same complex logic in multiple places. I’ve also seen a Gateway/Edge Service solution used to abstract the complexities of different security models away from the consumer and underlying internal system, enabling greater choice (Optionality) in the security model, and protecting the Evolvability of the internal system.
VIRTUAL MACHINES AND INDIRECTION
Virtual Machines (e.g. the Java Virtual Machine) operate at a high-level of Indirection. The layer sits between the client (the executing application) and the target platform (the Operating System the application runs on); see below.

Note that the client never directly interacts with the OS/platform; it uses the standardised set of (JVM’s) libraries that are uniform across all operating systems. The VM hides OS complexities so the developer need not have a deep understanding of each and every OS library (which is impractical to most). This is key to Java’s platform independence (and its slogan “write once, run anywhere”); developers develop a single application that operates consistently across all platforms. The virtual machine is actually an enormous Adapter, adapting Java APIs to meet different OS libraries.
INDIRECTION AND PERFORMANCE
Introducing an indirectional layer between two software units/layers/systems will likely cause some performance degradation. In the Object-Oriented world, an indirectional layer causes (a) additional object creation and (b) extra processing to delegate to that object. At a higher level, it may involve some form of middleware (e.g. Queues) or Gateway/Edge Service to mediate between consumer and service. And there is still the need to scale these indirectional layers to satisfy desired SLAs.
Is it important? That depends upon the context. For example, adding further layers to a workflow management system may not cause performance concerns; yet it may do in a 3D games engine, where performance is key to delivering a stunning user experience.
SUMMARY
Indirection is a key design principle which is used heavily in design patterns. It introduces a layer between client and target to handle a specific responsibility that would be inappropriate if it were embedded in either party. By ensuring the client and target remain decoupled, Indirection promotes Flexibility, Reuse, Extensibility, Evolvability, and (to some extent) Maintainability.
Common Indirectional uses include:
- Adding new behaviours.
- Modifying interfaces.
- Technology encapsulation.
- Complexity encapsulation.
Several Design Patterns are indirectional by nature, including Proxy, Decorator, Adapter, Facade, and Mediator. It’s also heavily used in technologies such as Edge Services, Load Balancing, and PAAS.
Whilst Indirection is incredibly powerful, it comes at a price. As we add layers, we find performance degrades. Whether that is acceptable is context-specific and is often balanced out with improvements in other qualities.
FURTHER CONSIDERATIONS
REFACTORING
“Do it right the first time, and you don’t need to refactor,” is a notoriously common statement I tend to hear from non-technical people. And, on the face of it, I can relate to it. Yet, it fails to take one key thing into account - Entropy.
If you asked ten people who work within the software Industry in various capacities what the “right thing” looked like, what would the results be? Would they be identical, or might they display a wide variance? I suspect the latter.
Not only would there be a disparity from people of different specialisms (which is to be expected, due to Rational Ignorance), but there would even be a gap between those individuals who shared the same specialism. My point? “Doing the right thing” can be highly subjective, and involves (to name a few):
- (deep and broad) Knowledge in a particular subject. For instance, software “best practice” has established common tools for solving common problems (e.g. Design Patterns, Delivery Pipelines), yet the existence of these tools, and a knowledge of them are distinct ideas.
- Experience, or level of specialism in the subject; such as the 10,000 hour rule.
- Current mindset. Stress - for example - can be a powerful personal growth inhibitor.
- Team support. How much support does your team give you, and when is it offered?
- Constraints. Many constraints can influence decision making, including: system complexity, availability of automated tests (Safety Net), time pressures (very common), regular Circumvention etc.
Entropy affects everything, all the time. It’s inescapable. Our world and daily lives are replete with tools, technologies, and procedures aimed at reducing entropy. Consider it for a moment.
For example, every year I arrange for my car to be MOT’d (a rigorous UK standard to prove road-worthiness) and serviced (common items that deteriorate with wear-and-tear are checked and replaced). No vehicle is permitted on the UK roads without a MOT certificate of readiness. In a sense, the MOT represents one way to test for Entropy, whilst the “service” acts as a counterbalance to entropy. If it fails its MOT, I must not drive it, and must ensure the problems are fixed, and retested.
Other examples where Entropy may intersect with our daily lives include:
- House cleaning. We clean surfaces, windows, vacuum clean carpets, and mop floors in an attempt to counter entropy.
- Gardening. We attempt to obstruct Mother Nature from her duties by mowing our lawn, weeding, trimming hedges etc.
- Personal health and well-being. When I overindulge, or feel lethargic, I eat more healthily and exercise more regularly. This (hopefully) improves my health, and extends my lifetime. That’s a form of servicing, or refactoring.
- We stain wooden fences to protect it from the weather.
- Moisturiser is applied to the skin in the (vain?) hope of cheating time.
Entropy also affects software, which brings me onto Refactoring. At the most fundamental level, Refactoring is a way to counterbalance entropy in software to:
- Ensure the code remains manageable.
- Extend its lifetime.
Refactoring might occur at a very low level, or be something more fundamental. Some examples include:
- Rename variables to be more clear and identifiable.
- Restructure code, or move it.
- Make code more testable.
- Improve/rework a suboptimal design.
- Remove unused code.
- Increase test coverage.
- Introduce flexibility.
- Refine a software contract (e.g. API) to be more integrable.
- Increase capacity.
Note that none of these activities (should) affect the functional capability of the solution - they’re only structural changes.
SUMMARY
I know some of you may still be questioning the value of this (additional) work? So let me try another tack. Let’s say you’re in the business of building and selling software products. You likely have two large concerns:
- If, like many other tech companies, a large proportion of your operational costs are tied up in the salaries of the IT staff responsible for defining, building, and operating the software solutions, then you want to get the best possible value from the work they undertake.
- You don’t want to inadvertently shorten the lifetime of your product (to enable it to spend longer in the maturity/stabilisation phase [1]) - otherwise you may find yourself fending off some difficult questions from your shareholders/investors.
Let me try to address those concerns now. It’s commonly held that between 40-80% of all development time is spent not in developing new software, but in maintaining existing software (40-80% Maintenance). And software exhibiting poor maintainability has high manufacturing costs. This high maintenance not only impacts your bottom line (poor ROI), it may also affect Agility (e.g. you can’t easily pivot), TTM (e.g. you’ve missed the gap in the market), and Reputation (e.g. you’ve let your customers down with high prices or late deliveries). Yes, Refactoring is an additional expense, but (if executed correctly) will increase Productivity, business scale and flexibility (by reducing complexity, we expand the pool of talent able to undertake a job), and support staff retention (technologists don’t want to work with poor quality code; retention also reduces training costs).
Like a car service, Refactoring improves Maintainability, Flexibility, and Evolvability, and therefore increases the potential lifetime of a software product. This may increase ROI, and make any future investment in your business more appetising.
However, it’s not all good news. There’s always a catch as they say; in this case in the form of Gold Plating.
FURTHER CONSIDERATIONS
- [1] - Product Life Cycle - https://en.wikipedia.org/wiki/Product_life-cycle_management_(marketing)
- Entropy
- 40-80% Maintenance
- Gold Plating
FEATURE PARITY
Feature (or Functional) Parity relates to the commonality between two systems. Systems that have (near) Feature Parity fundamentally perform the same job(s), and so, can be treated similarly.
Why is this important? Feature Parity may determine your ability to migrate away from one system to another. This is particularly relevant when dealing with product upgrades or migrations, away from the legacy and on to something modern.
The difficulty with Feature Parity is typically one of time (TTM), and cost (slow ROI). Reaching parity can take a significant amount of time/effort if the system being mimicked is functionally comprehensive (years, decades, or never in some cases).
Failure to reach Feature Parity, sensibly, typically pushes many down the route of managing dual systems running in tandem (using techniques like The Strangler Design Pattern), to slowly strangle the old functionality, and direct traffic into the new (Working with the Legacy - Dual Systems).
FURTHER CONSIDERATIONS
TECHNOLOGY SPRAWL
Sometimes there can be too much of a good thing.
Consider the following story. Your business is building a new platform using the Microservices architecture. The business consists of ten product teams, spread over three geographic areas (e.g. the US, the UK, and India). The new platform has thirty domain services, managed by these ten teams; the key ones are shown in the table below.
Being a (supposed) Microservice best practice, each team is given a free-reign to choose their own implementation and storage technologies (Technology per Microservice, Polyglot Persistence). Quite naturally then, we find that each team (delineated by a colour) selects a different set of technologies and techniques to solve their problem, deciding it based upon a combination of their experience, knowledge, Bias (e.g. modernity), difficulty, and level of interest. We end up with a table of the form...
| Service | Team | Technology | O.S | Storage |
| Customers | Green | Java 12, Spring Boot, Docker | Linux | MySQL |
| Payments | Blue | C# | Windows | SQL Server |
| Maps | Magenta | Python 3 | Centos Linux | MySQL |
| Billing | Orange | Java 11, Spring Boot | RH Linux | Oracle |
| Receipts | Yellow | Node.js | Windows | MongoDB |
| Cash Register | Burgundy | Typescript | Linux | Postgres12 |
| Reports | Black | Stored Procedures | Windows | SQL Server |
| Discounts | White | Typescript on AWS Lambda | Linux | AWS DynamoDB |
| Accounts | Cyan | GO | RH Linux | MySQL |
| Stock | Blue | C# | Windows | SQL Server |
| Acquisition | Silver | Python 3 on AWS Lambda | Linux | AWS Aurora |
| ... | ... | ... | ... | ... |
I’ve left out a number of services, but assume that most teams manage more than one domain service (e.g. Blue manages Payments and Stock). Pay particular attention to the Technology, O.S., and Storage columns - note the Combination Explosion occurring in them.
There’s a reason why Technology per Microservice is touted. It provides a great degree of flexibility. However, it can have one very clear disadvantage - misuse causes us to create a Technology Sprawl, simply by giving everyone ultimate ownership and flexibility.
In the above case, this unit-level flexibility comes at a cost:
- We’ve created a Complex System. Not necessarily at the business domain level, but at the technological level. The system is hard to comprehend, depends upon many different skill-sets, and coordination activities may be hampered by this during an unanticipated event (e.g. catastrophic system failure).
- Favouring unit-level productivity over business-level scale (Unit-Level Productivity v Business-Level Scale); i.e. we lessen our business-level flexibility to gain unit-level productivity. Due to the considerable divergence in technologies, we’ve created a form of skills gap. We can’t (easily) move people between projects/teams to support one another. For instance, if Sudeep finishes his work in the Green team, how do we enable him to support (for instance) the Yellow or Burgundy team? This is mainly due to the technology sprawl.
- Operations lose a Uniformity and consistency they might need, or expect. In a detracting sense, we find the entire system can’t be managed without a coordinated effort from everyone (who are spread around the globe in different timezones). Yet the positive impact is that we may find greater ownership and accountability within each team.
- Possible Security concerns. Each vendor technology faces different vulnerabilities, at different times, and has a unique take on vulnerability resolution. By expanding our vendor solutions, we increase the likelihood of significant outliers, and may find our security model dependent upon the worst performing vendor. Of course, on the flip side, if you uniformly integrate into a vendor with a poor track record for vulnerability resolution, then you may find the entire system exposed.
- Lacking a Uniformity across the overarching solution. For instance, you must watch that different standards are not employed per service/team when it’s important to adhere to a common approach (e.g. security tokens).
SUMMARY
Technology Sprawl may also occur through a lack of consolidation. For instance, organisations that apply the Growth through Acquisition model may inflict a Frankenstein's Monster System upon themselves, and thus suffer a sprawl.
It’s worth reinforcing that there’s nothing wrong (and indeed, it’s beneficial) with having the flexibility to choose from multiple technologies. However, beware that overdoing it may create more problems than it solves.
FURTHER CONSIDERATIONS
- Microservices
- Technology per Microservice
- Bias
- Complex Systems
- Unit-Level Productivity v Business-Level Scale
- Growth through Acquisition
- Frankenstein’s Monster System
OBJECT-RELATIONAL MAPPERS (ORMS)
Object Relational Mappers (ORMs) are very convenient frameworks for managing the persistence and mapping of data. They map between the relational (tabular) world of many databases, and the object model preferred by most developers (Lower Representational Gap).
ORMs are - in the main - extremely powerful tools to aid development; however, I regularly see their convenience makes them good candidates for misuse and poor practices (Convenience Bias), thus affecting important non-functional qualities like Performance and Scalability.
Here’s a few ORM war stories to share with you.
1 - READ ALL, MINOR UPDATE
Consider the following case. You’re building an API logging facility (deployed on an Edge Service), to record all API traffic to and from your system. The utility will capture and record every incoming request and outgoing response in a relational database table (called API_LOGS), which can then be used for debugging, Non-Repudiation, and capturing SLA metrics. Being the entrypoint for all API requests, it’s a heavily used component, so Performance and Scalability are vital.
MODERN CLOUD SOLUTIONS
Modern Cloud solutions already support this facility, so you’ll see fewer and fewer instances of a home-grown solution. However, what I'm demonstrating here is the ORM management approach, not necessarily its functional intent.
The API_LOGS table might contain the following type of information.
| Name | Description | Example Data |
| ID | The unique row identifier. | 10000 |
| URL | The URL to the resource. | https://somedomain.com/carts/508245 |
| VERB | The HTTP Verb being used: {GET, POST, PUT, DELETE}. | POST |
| REQUEST | The body of the request, in JSON form. This can be quite large. | { ... } |
| RESPONSE | The body of the response, in JSON form. This can be quite large. | { ... } |
| CORRELATION_ID | A unique transaction-level identifier. | A UUID; e.g. 123e4567-e89b-12d3-a456-426655440000 |
| DURATION | The length (in milliseconds) it took to complete the request. We’ll use this field to measure SLAs. | 100 |
Let’s say the underlying system is an e-commerce solution, and the customer is adding items to their (browser-based) shopping cart. One customer sends through the following request.
POST https://somedomain.com/carts/508245
{
"items": {
"item": {
"id": "8711409",
"quantity": 1,
"title": "Striped Winter Scarf",
"offer" {
"id": "58jssa598",
}
},
"item": {
...
},
"item": {
...
}
}
}
The first thing the Edge Service does, prior to forwarding the transaction for processing, is to log the incoming request, then retain the generated id to this row for future needs. Whilst we don't yet know how the internal system will respond, it’s important that we persist this information now, and not wait for the response (e.g. we could miss a DoS attack for instance if we don’t). The table row might be:
| ID | URL | VERB | REQUEST | RESPONSE | CORRELATION_ID | DURATION |
| 10000 | https://somedomain.com/carts/508245 | POST | { "items": { "item": { "id": "8711409", "quantity": 1, "title": "Striped Winter Scarf", "offer" { "id": "58jssa598", } }, "item": { ... }, "item": { ... } } } | NULL | 123e4567-e89b-12d3-a456-426655440000 | NULL |
| ... | ... | ... | ... | ... | ... | ... |
The edge service then forwards the request onto the appropriate party (Carts in this case), waits for a response, updates the appropriate RESPONSE and DURATION fields for that row, and then returns the response to the browser (e.g. indicating cart total, any coupons applicable).
The code below is representative of the approach I’ve witnessed.
1. # store the request
2. id = dao.store(request)
3. start = now()
4.
5. # forward the request on to the internal system (e.g. Carts)
6. response = send_request(request)
7.
8. duration = now() - start
9.
10. # now handle the response
11. # get the entire record out of the database;
12. # this equates to: select * from api_logs where id = 10000
13. APILog api_log = dao.read(id)
14.
15. # set response data in the returned object
16. api_log.set_response(api_response)
17. api_log.set_duration(duration)
18.
19. # now update the row to save the response
20. dao.update(api_log)
Line 6 shows an ingress deeper into the system (Carts) for processing.
Note that line 13 pulls out the entire row from the database (using the primary key identifier). In this case we’ve:
- Requested everything in that row from the database (i.e. select *).
- Transferred all of it across a (busy) network.
- Unmarshalled it on the other side (Edge Service) into a more convenient object form to then manipulate it.
We make no use of any of the data we selected in line 13. In lines 16 and 17, we set two values (the response received, and the time taken for the internal system to process the request). Finally, on line 20 we ask for the updated data to be persisted, which involves:
- Marshalling data from object to serialisable form.
- Transferring the entire object (row) back across the network (what a waste of bandwidth).
- Updating that row in the database.
PLAYBACK
To reiterate, we've pulled the entire row out of the database, transferred it across the network, then marshalled it into an object form, solely to set two fields, and then send the entire thing back over the wire to persist it. It’s a unnecessary waste of computing and network resources (just to satisfy a more convenient approach), when all that’s actually required is:
update api_log set response = :response, duration = :duration where id = 10000;
2 - ITERATIVE DELETE
In this scenario (based loosely on one I’ve seen) we want to delete any “stale” cart items (items added over 48 hours ago). See the code below.
for cart_item in cart.items:
# was this cart item added over 48 hours ago?
if cart_item.date_added() < (now() - hours(48)):
dao.remove(cart_item)This is another example where we make unnecessary database round-trips. The convenience of the ORM model (and programming language constructs) is more pleasing to the eye, but it is a highly inefficient deletion algorithm (we delete each cart item one item at a time), and all that we really needed was a database delete statement:
delete from cart_items
where date_added < (now() - hours(48));INCREASED INCONSISTENCY RISK
This approach also carries more risk. Anything that relies upon multiple (notoriously unreliable) network interactions to complete a business transaction increases the risk of creating inconsistent business transactions (e.g. data inconsistencies, peculiar bugs, skewed business reports). It’s likely the developer never considered this when introducing the change.
3 - HIGHLY COMPLEX RELATIONSHIPS
I’ve also seen cases where ORMs were used to model/manage highly complex database relationships, attempting to persist a large quantity of data in a single transaction. This created Performance and Scalability challenges, as the ORM initiated a deluge of individual database calls.
Arguably, the problem had several causes:
- An overly complex database model.
- Too coarse a grain of API contract (Goldilocks Granularity), accepting too much data of varying responsibilities.
- An over-reliance on the power of the ORM.
SUMMARY
ORMs are tools that simplify development activities, and thus offer better TTM and ROI. However, their convenience can cause laziness, or make us too dependent upon its abilities (Thinking over Silver-Bullet Technologies).
In some cases, limiting the use of the ORM’s object-modelling facility, to force a more “direct” communication path is preferable. Why make five calls when one simple call may suffice?
FURTHER CONSIDERATIONS
- Non-Repudiation
- SLAs
- Lower Representational Gap
- Edge Service
- Goldilocks Granularity
- Thinking over Silver-Bullet Technologies
- DoS (Denial of Service)
SYSTEM TENANCY
The concept of system tenancy is a common theme, particularly in SAAS solutions, and the Cloud.
Dictionary.com defines a “tenant” as:
“a person or group that rents and occupies land, a house, an office, or the like,
from another for a period of time; lessee.
...
an occupant or inhabitant of any place.”
System tenancy therefore relates to the number of tenants that use a single solution, and/or environment. Tenancy comes in two flavours:
- Single-Tenant - a single “tenant” per environment.
- Multi-Tenant - multiple “tenants” coexist in the same environment.
“CUSTOMER” & “TENANT”
Please note that I may use the terms customer and tenant interchangeably within this section, generally to describe a corporate customer as a tenant, over an end-user customer.
The two approaches are discussed next.
SINGLE-TENANCY
A Single-Tenancy solution provides an entirely independent (non-shared) set of resources, or services, to another party (the tenant).
You might opt for single-tenancy when:
- You must retain independence between customers (such as governmental).
- When you only have a single customer.
- When the system is truly bespoke (I know of some businesses who use a branched codebase per client, and will never realistically merge those changes back to the main product). Under these circumstances mixing different products would make little sense.
- When the system must process highly sensitive, or volatile information (e.g. experiments that can't have external influences).
Examples of customers in this realm may include: independent (financial) trading, healthcare, military, or governmental.
Its benefits may include:
- No disturbances from noisy neighbours (tenants). Other tenants cannot impact the operational efficiency of that tenant’s solution, as they’re all independent.
- There’s a clear distinction of resource allocation. It’s clear which tenant is using which resources.
- You minimise Single-Points-of-Failure. A failure can only affect a single tenant.
- Security, particularly from a confidentiality and availability perspective. No other tenant(s) can pollute this tenant’s data-set, nor can a successful injection attack impact more than a single customer (this benefits the system owner, not necessarily the customer). However, note that this approach can have other security disadvantages - see Caveat A.
- A simple billing strategy for operational usage (at least in production). The billing of operational usage, in production, is easily identifiable and accurate (because only one customer uses it). However, be aware that it becomes much harder (and more like educated guess-work) to accurately bill if any form of environment sharing also occurs (see my later point on shared systems).
SINGLE-TENANT VULNERABILITY MANAGEMENT
The single-tenancy model may - at least from a vulnerability management perspective - improve the security for the most valuable customer, possibly at the expense of all other customers, who get left behind, receiving patches late, or possibly never.
Remember there are operational costs of patching each environment, which also includes coordination, and regression (test) costs. That’s potentially a very poor investment to the owning business, and may be a disincentive to progressively patching security vulnerabilities.
ANCIENT PROBLEMS
Grave-robbing in ancient Egypt could be very lucrative. And whilst it was a poor outcome for many of the pharaohs (mainly due to time being against them, and the high incentives on offer to the grave-robbers), viewed from one perspective, the approach was successful.
The single-tenant approach (one pharaoh per tomb) ensured that if, or when, the grave-robbers uncovered a tomb, they only gained the riches of that pharaoh, not all of the riches of all pharaohs. Whilst this was unfortunate for that one pharaoh, it had little impact upon the others. This is one of the key security benefits of single-tenancy.
Its drawbacks may include:
- Management expenses (money). It can be extremely expensive to operate multiple different environments
for multiple customers when using single-tenancy (even when the customer is paying for operational usage),
because:
- (of) Change management (and coordination). Managing software releases, deployments, and configuration for (basically) the same solution, but to support different customers, at different times, is extremely challenging. You may need to employ someone solely for this purpose.
- It’s inconvenient to manage a product solely for a single customer when you have multiple. Your entire business must keep track of each customer's current version, across every deployable environment (that’s devel, test, staging, and production), and also manage their upgrades.
- Other shared environments (see later).
- Slows innovation cycles for established businesses. Each customer receives upgrades at different speeds (sometimes never), so most learning can only be gleaned from customers on the latest releases. Promoting innovation across all customers is significantly harder.
- Attachment. Customers get attached to a (what they see as their) product, (even when it's not theirs). Some customers treat a single-tenancy model as a way to move at their pace, rather than the product owner’s pace. They may cling on to an unsupported product version for far longer than the product-owning business deems fair (or acceptable), thus creating Innovation Stasis, and Evolvability barriers to both parties.
- Other “shared” systems. Many businesses would see additional customer-specific environments that
lie outside of a production environment (such as test) as extraneous, since they’re rarely touched.
It’s tempting, therefore, to use a shared (test) environment for some aspects of the software lifecycle.
This is problematic because:
- The owning business must switch different software releases in and out to undertake testing (e.g. system, performance, penetration). Yet being a shared environment across multiple customers often causes tensions (and thus, Expediting), as the priority of one customer ousts another, with only partially complete test outcomes. This either leads to TTM, or quality issues.
- Accurately estimating the operational billing of these shared systems is harder (and why a subscription pricing model may be favourable). For instance, a single shared test system for all customers sees constant contention (Expediting), making accurate billing difficult.
- Each time you test for a different customer, you may need to recreate the shared environment on a different product version.
MULTI(PLE)-TENANCY
A Multi-Tenancy solution provides a set of shared resources (including a database), or services, to multiple parties (the tenants). Whilst it's common for each tenant's data to be held in a common data store, each tenant's data should remain invisible to the others.
The multi-tenancy model tends to be the more popular model nowadays, mainly due to the rise of internet-based products, services, and platforms. You may opt for multi-tenancy when building a product for multiple/many customers, particularly if your business model is SAAS.
SAAS
The SAAS (Software as a Service) is a common business model that tends to use multi-tenancy. In this model the customer pays a regular subscription (mainly monthly) fee for access to common services.
Its benefits may include:
- Cheaper (overall) operational running costs. The same resources can be shared across multiple customers; i.e. less waste. This is a common Cloud approach, and falls within the realms of Economies of Scale.
- A single production deployment makes functionality available to all customers (excepting Circle of Influence, Canary Releases, of course). That’s it, no further deployments. Whilst this is generally good, it can also have negative connotations (see the later point on House of Cards).
- Minimal management expenses. The effort to release software is low (little coordination), due to no disparity between customer versions.
- Ability to favour an OpEx pricing model over a CapEx model (CapEx & OpEx). We may employ a more convenient billing model for our customers. Billing becomes less about resource consumption (which can be tricky) and more about a simpler, more palatable subscription pricing model.
Its drawbacks may include:
- A House of Cards system. A single flaw can disrupt everyone (all tenants/customers). Whilst the focus of single-tenancy systems may tend toward Availability, we are more averse to flaws in the multi-tenancy model, so more onus goes into Resilience.
- Security may be more challenging, or the potential for loss may be greater. For instance, an injection attack on a single-tenant solution only exposes a single customer to damage (not ideal of course), whilst a flaw in a multi-tenancy solution potentially exposes the data of all tenants. See Caveat A.
WHICH MODEL?
Neither model is necessarily better - it depends upon your needs. The mind-map below offers some of the considerations discussed earlier. Note that these are guidelines, are not necessarily complete, and certainly don’t consider every aspect specific to your context. Caveat Emptor.
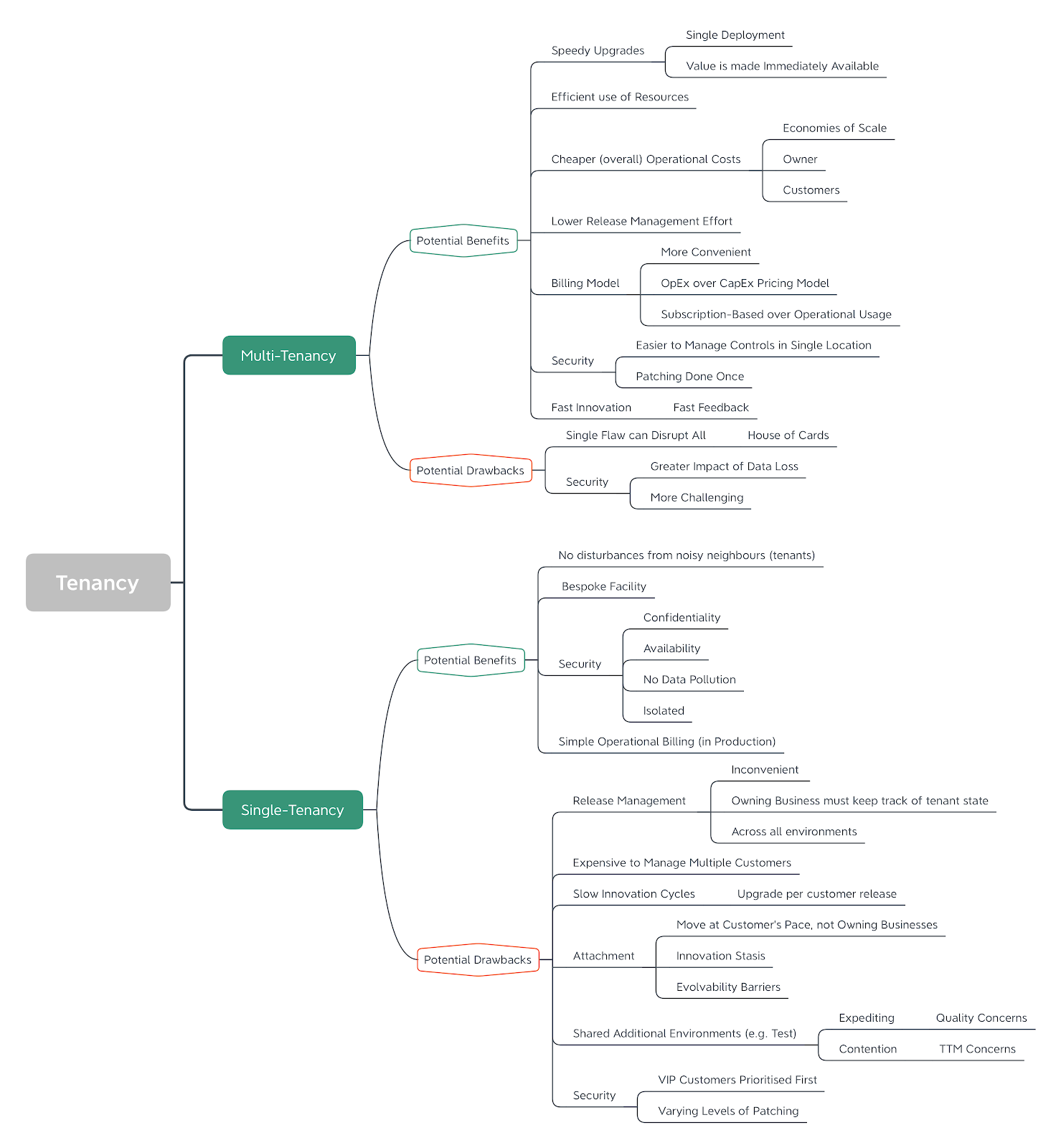
CAVEAT A - SECURITY MODEL
Some system owners may consider their entire estate is secure, solely because they’re using a single-tenancy model. However, this may in fact be counterintuitive. The single-tenancy model has the potential to create a vast estate of systems if many customers are supported. Additionally, each tenant may be coupled to its own release schedule (often outside of the owning businesses’ control). Thus, we may find that whilst some tenants receive preferential treatment (quick patching), many others may not, creating a “whack-a-mole” style of vulnerability patching across the entire estate.
If badly managed, the multi-tenancy model can increase the impact of a successful attack (in terms of injection/extraction attacks), yet it’s ability to be hardened with (relative) ease - by placing all of your focus, and controls, on a single set of resources - is powerful. Patching a single group of resources once is far less burdensome than executing it across disparate groups of resources. A key investment made by all major Cloud vendors has been to (quite successfully) tackle the security concerns over multi-tenancy.
SUMMARY
System Tenancy is an important consideration in system construction.
Single-Tenancy can be good in situations where each tenant must be independent, yet it creates operational burdens on the owning business that may (for instance) make them relax important constraints, or impact everyone’s ability to innovate. Multi-Tenancy reduces the operational overhead burden on the owning business, and supports fast innovation, but increases the risk of a House of Cards failure, so must be carefully managed.
Whilst I have no definitive evidence, I suspect the multi-tenant model also fits better into the “cattle, not pets” resilience mantra (kill-and-recreate rather than nurse back to health) than its single-tenancy sibling.
FURTHER CONSIDERATIONS
- The Cloud
- CapEx & OpEx
- Economies of Scale
- Circle of Influence
- Canary Releases
- SAAS (Software as a Service)
- Expediting
- Single-Points-of-Failure
CONTAINERS & ORCHESTRATION
4 engineers get into a car. The car won't start.
The Mechanical engineer: "It's a broken starter".
The Electrical engineer: "Dead battery".
The Chemical engineer: "Impurities in the gasoline".
The IT engineer says: "How about we all get out of the car and get back in?".
This joke is actually a good analogy for containers and orchestration technologies.
Containers are a modern, yet well-established means of encapsulating and running software, particularly suited to the Microservices architecture. Containers are lightweight units, and contain everything required to run an independent software service, from Operating System, to web server, to the application. Due to their lightweight nature, they are also quick to spawn (or destroy), and relatively easy to orchestrate. Docker is the best known containerisation technology.
CATTLE, NOT PETS
Historically, we’ve built systems that are large, monolithic (Monolith), and were released atomically (Atomic Releases). We created an aversion to their loss (Loss Aversion), and their continued health (through nursing) was our key concern.
Since then we have seen several key technology shifts, including Microservices, Containers, and the PAAS - all supporting lower-grained software services that may be linked together (through orchestration), and scaled independently.
In this new world, we don't nurse a sick container back to health (e.g. by trying to diagnose it, and attempt to reinstate it); we assume it lost, and hit the reset button (they are Cattle, not Pets). In a sense, we reverse the monolithic model (Availability above all); we hope for Availability, but plan for failure (with Resilience).
Containers bring consistency (and Stakeholder Confidence) to developers and testers, by providing like-for-like development, test, and production environments. The second-order outcome of this is to promote Shift Left and Fail Fast practices, and subsequently (third-order outcomes) to improve TTM and ROI (by enabling testers to run local copies of unfinished software, prior to any functional release, we catch problems much sooner).
The benefits of Containers include:
- Scalability. We can scale up (or out) simply by spawning new container instances.
- Uniformity across all environments (whether it's Devel, Test, or Production). This consistency reduces complexity, unknowns, and risk. It creates a form of Safety Net that also increases Stakeholder Confidence.
- Promotes Continuous practices. Containers integrate well into Deployment Pipelines, and also support Blue/Green Deployments and Canary Releases.
- Resilience. Containers handle (systems) fragility well, enabling swift recovery.
However, that still leaves us with the following problems:
- How do we handle load balancing? Although it’s easy to spawn new container instances, how do we organise them and manage traffic to them so that we don’t flood one particular instance?
- How do we handle failover? How do we know when a container has failed (or is failing), and automatically resolve it?
- How do we scale elastically? How do we increase the number of container instances in times of high demand, but reduce them when they're not required?
- How do we maximise the use of hardware resources (i.e. better ROI) without overloading them?
- Metrics. How do we capture and aggregate metrics in a consistent manner across an entire platform?
These problems are answered by orchestration technologies (like Kubernetes - an open-source container-orchestration technology that handles deployment, scaling, resilience, autonomy) and the Platform-as-a-Service (PAAS). Autonomy is typically achieved using the declarative model (Declarative v Imperitive).
FURTHER CONSIDERATIONS
- Kubernetes
- PAAS
- Atomic Releases
- Nursing Monoliths
- Deployment Pipelines
- Blue/Green Deployments
- Canary Releases
- Learn Fast
- Safety Net
- Microservices
- The Cloud
FEATURE FLAGS
How we manage change in software is an important consideration. There are two common approaches:
- Prevent change from entering the release stream until it's explicitly merged. We achieve this with carefully managed code branches, and policing (e.g. gates). Each feature is given a privileged status, and only merged when deemed appropriate.
- Steadily deliver change into the release stream, but prevent it from being accessed until it’s explicitly made available (a flag). No feature is given a privileged status, and they are immediately merged onto the release stream.
Both approaches are discussed in greater depth here (Branching v Continuous Practices).
PREVENTATIVE RELEASE
Historically, the common approach has been to manage change through code (feature) branches. In this model, change is distanced from the master branch (what’s released), and only merged at appropriate decision points (e.g. when a user story is complete). Each feature is given something of a privileged status, and is only released to production after a series of manual (and sometimes onerous) interventions, including code quality checks, (possible) isolated testing, and a physical merge of the branch back into the master.
STEADY STREAM OF CHANGE
In this model we push through a steady stream of change to production (although you can use gates), with the aim of minimising interruptions to its flow. This is typically achieved through “continuous” practices (Continuous Integration, and Continuous Delivery), and implies that we work exclusively on the master branch.
If done right, this model promotes TTM, ROI, and Agility, but also causes the following problem. If all change occurs in one steady stream, how can you tailor (user) access to a feature, to occur at the right time and to the right people? Enter Feature Flags.
WHAT ARE FEATURE FLAGS?
Feature Flags (also known as Feature Toggles) provide a mechanism to enable or disable a feature (thus altering a system’s behaviour), without introducing the risk and overhead of managing it through code changes.
STATIC CODE SWITCHES
Generally, we should avoid managing switches through static code to:
- Mitigate risk. Each change risks us unwittingly disturbing another area of code - don’t change the code, don’t risk a corruption.
- Additional regression testing costs. Each code change needs some regression testing - an avoidable investment.
- Lack of dynamism. Each code change must follow a specific route to production, which can be laborious when you just want to enable a feature.
RISK MITIGATION
Feature Flags provide a form of risk mitigation by protecting users from the (unintended) consequences of accessing an incomplete (or unready) feature.
Feature Flags are particularly useful when we wish to manage a continuous stream of change, allowing us to either:
- Disable an entire feature. We might use this when preparing to release a new feature on a certain date (and don’t want users accessing it prior to then), or when a feature is incomplete and should not (yet) be made available to users.
- Only enable a feature (or behaviour) to certain users, or groups of users
(i.e. the Canary Release model). This is useful for:
- Testing. We can test in a live environment (assuming we’re careful).
- Tiered pricing models. We can use Feature Flags to determine who gets access to what; e.g. Silver subscribers get access to features A, B, C, whilst Gold subscribers get access to features A, B, C, X, Y, Z.
- Testing our Assumptions. Learning how a certain group of users behave, and using these metrics to shape the future direction of that feature.
Note that one approach is highly dynamic (per user, or group of users), whilst the other approach is quite static and binary (e.g. “this feature will remain off until the 1st June, once we’ve successfully marketed the new feature.”).
The downside to the flexibility offered by Feature Flags is the additional complexity and Manageability costs. It can create a combination explosion of different, switchable, behaviours. Developers, testers, and product representatives must be cognisant of which flags are in their area of work, as each encapsulates an alternative execution path that may behave unexpectedly if disabled in development but enabled in production. The longer living these flags are, the more that accumulate, and the more complexity to manage. Thus, they create a form of Technical Debt and should be retired when practical.
SUMMARY
Feature Flags offer a way to deliver rapid change to customers, yet minimise the risk (mainly to the product owning business). In combination with “continuous practices” they offer ways to increase Business Agility and TTM, by offering Fast Feedback.
Feature Flags support different levels of dynamism, from release-level feature availability, down to Canary-level flags tailored to certain groups or individual users.
FURTHER CONSIDERATIONS
- Continuous Integration
- Assumptions
- Continuous Delivery
- Branching v Continuous Practices
- Canary Releases
- Technical Debt
- Learn Fast
GATEWAYS
Much of my career has been shaped by Tiered Architectures. In this model, each tier encapsulates a specific responsibility that can be slotted into place between other tiers to build something more advanced. It’s an extremely flexible model, ensuring responsibilities remain cohesive (unpolluted) and comprehensible.
Consider the OSI networking reference model. Individually, each network layer doesn't provide much value, but when combined, form something extremely powerful. The Three-Tiered architecture (and Model-View-Controller (MVC) pattern) offers another example of distinct tiers - it splits an application into distinct tiers (presentation, business, and database) - and has been widely adopted.
TERMINOLOGY
I’ve opted to use the umbrella term “gateway” here to define both API Gateways and Edge Services. Both are used to funnel requests through, prior to a deeper interaction with an internal system.
Gateways play a key role in a tiered architecture (tiered architectures never really died - even with the advent of Microservices or Cloud services such as Serverless - they just became less prominent). They have some distinct advantages, including:
- (Logically) There’s only one of them. Common responsibilities are encapsulated in one place, rather than strewn liberally across an internal system (although Microservices purists might disagree on the shared responsibility point).
- High Reusability and Flexibility, due to low Assumptions and its decoupled nature.
- Protects sensitive parts of an internal system from pollution. For instance, internal integrations between services can be more challenging if the security model becomes a hindrance. Encapsulating that responsibility elsewhere can simplify that integration.
- High comprehensibility. It’s easy to identify where certain responsibilities lie.
OVERLOADING RESPONSIBILITIES
Collecting disparate responsibilities in a confined area of a system can create a range of problems, including tight-coupling, complexity, Assumptions, alongside Extensibility, Reuse, and Evolvability challenges. Breaking them out allows them to be better managed.
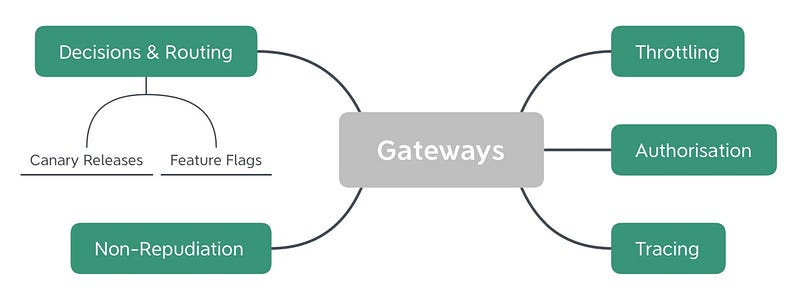
Gateways are commonly used to:
- Authorise (or deny) incoming requests, such as by verifying a JWT (JSON Web Token), or comparing hashes (e.g. HMAC).
- Capture all interactions with the internal system for Non-Repudiation.
- Inject system-level tracing for debugging and metrics capture.
- Rate limiting (throttling). We can protect a system from being flooded by limiting how many users access it. Whilst this may seem counterintuitive, it’s preferable to allow some users in, than being forced to reject them all.
- Decisions and routing for Canary Releases and Feature Flags.
The diagram below presents some typical actions of a Gateway.

TAILORED UTILITIES
Gateways can also be a good place to hold “utility” features that require tailoring for different customers.
Consider the following case. Let’s say you offer services through APIs to a range of corporate customers. Those corporate customers often have differing security expectations and therefore may dictate their preferred security model to you. Sounds unlikely, yet many smaller businesses don’t hold sway over their large corporate counterparts, who can often dictate the terms of the contract. In these cases, reasoned arguments about technical purity and consistency will fall on deaf ears as the drum beats to dollars. You're forced to support multiple security models to satisfy all customer needs.
These types of bespoke behaviours fit poorly into an internal system - ensuring it remains agnostic to these behaviours is vital to reduce complexity and Assumptions, thus increasing its Flexibility, Reuse, and Evolvability - but you still need to support those behaviours somewhere. One solution is to encapsulate these behaviours within a Gateway, using (canary) Feature Flags to route traffic to the appropriate tailored security model before pushing it deeper into the internal system.
Gateways can - of course - have some disadvantages:
- Scalability. The Gateway should be just as capable (or more so) as the internal system it protects. You don’t want the embarrassment (or worse) of talking up your highly scalable (internal) system, if the only way to access it is through a poorly performing gateway.
- It could be a potential Single Point of Failure. If the Gateway fails (either due to a miscreant release or a runtime error) then we may find our entire system is unavailable.
- Availability of the whole system is measured by both the internal system, and the Gateway’s availability. This is Availability in Series. As such, we measure the overall availability by GAIA (where GA is the gateway’s availability and IA is the internal system’s availability). A sobering thought but we find that the overall availability is lowered than if we were to solely expose the internal system.
- The overloading of responsibilities. It’s important that we limit the smarts held within the Gateway and keep it agnostic to domain-specific internal system needs. We're not trying to build a monolithic Gateway or ESB. Gateways should be lightweight and cohesive, and built for common (reusable) responsibilities.
- Atomic Releases. All or nothing. There may be cases where you want the flexibility to choose when you upgrade parts of your internal system (e.g. you may have an impending delivery date and any unnecessary regression testing will put it at risk). As all internal functionality first comes through a centralised Gateway, we may find the scope of change undesirable. The secondary effects of this may cause Change Friction and hinder Evolvability.
REAL-WORLD EXAMPLE
Let’s now turn to look at an example where a Gateway could have been quite useful.
Consider a system consisting mainly of a suite of Microservices. Embedded within each microservice lives an assumption about its security mechanism - JWT should be used by all callers. Doesn’t seem too bad, but let’s say that this security model is only accessible through a UI authentication mechanism and not to service-to-service interactions. That’s ok whilst the UI is the only consumer, but not when we find other services want to talk to one another.
The Assumption (JWT) embedded within these services limits its reuse potential - it isn’t built to function with alternative security mechanisms. (Service) Consumers would either have to change their model to use JWT, or we’d need to embed another security model into each microservice; not only increasing complexity but also introducing a significant development and regression cost. Additionally, we’d be reworking each microservice again whenever a further security mechanism needed to be supported.
This scenario provides ideal stomping ground for an indirectional layer (Indirection) such as a Gateway. If a gateway handles all security needs, we can manage that behaviour centrally, allowing quicker change and extension, and minimising pollution in the internal system.
SUMMARY
Gateways are extremely versatile and offer the following benefits:
- Flexibility, Extensibility, and Reusability. We can easily change a behaviour or add new ones and have it take effect across the entirety of our solution.
- Change once semantics, since there’s (logically) only one of them.
- They protect sensitive parts of an internal system from (unnecessary) pollution. This can also increase reuse.
- High comprehensibility. It’s easy to find these behaviours and to articulate where they are executed.
However, you should also be aware of some of their disadvantages, including the Availability ramifications (Availability in Series), and (due to its intent) that it can become a Single Point of Failure.
Whilst it’s tempting to circumvent the Gateway when two internal services wish to interact, be careful that you’re not circumventing an important behaviour (in the gateway) that will catch you later on (such as when you need to publicly expose one of those services and find that external consumers get a different experience to internal consumers - Eat Your Own Dog Food).
Most Cloud providers offer their own (API) Gateways. Amazon AWS has one (aptly named API Gateway), as do Microsoft and Google. These gateway services often have extremely good integration with other Cloud services (at least with their own) with a focus on Integrability and TTM.
FURTHER CONSIDERATIONS
- Availability in Series
- Eat Your Own Dog Food
- Assumptions
- Microservices
- The Cloud
- Single Point of Failure
- Non-Repudiation
- Canary Releases & A/B Testing
- Feature Flags
- Indirection
- Change Friction
- Serverless
PAAS (PLATFORM-AS-A-SERVICE)
Building and managing software can be a tricky affair. It’s challenging enough to build robust, maintainable, secure, and high-performing solutions, without also having to consider their operational management, or how to integrate it as part of a complete solution. Managing your own software raises the following concerns:
- Networking and hosting. Where should we host the services, and how do you configure the network to support them?
- Linking up services. How do we group the same services together and route traffic to a specific instance in the cluster?
- Scaling the solution. How do we scale up (or down) dynamically and quickly (even elastically)?
- Patching, hardening and securing infrastructure, operating systems, middleware etc.
- Adding telemetry. How do we centralise logging and alerts?
Some of these concerns aren’t necessarily skills that software engineers are familiar with, fitting more snugly into the infrastructure domain. For example, provisioning and correctly configuring a database is quite a specialised skill that few developers likely have (realms of a DBA).
THE ROAD TO PAAS
The Cloud was a game-changer. It turned the concept of self-managed infrastructure on its head, offering us:Whilst IAAS was a significant leap, it wasn’t enough for many. Business customers (building their own software) desired an even quicker route to market.
- IAAS (Infrastructure-As-A-Service) - on-demand resources that reduced business risk by transferring the (CapEx) burden onto cloud providers.
- Managed cloud services (e.g. S3).
PAAS is an obvious progression of (and often delivered upon) IAAS, offering a software platform to manage and execute software that:
- Lowers complexity and the learning curve. Some infrastructure and operational complexity is transferred from the application developers to the PAAS provider. Businesses manage software applications and data, that’s it.
- Provides a consistent approach to problem solving and operations (Uniformity).
- Increases Productivity and TTM. Hiding some of the platform complexity enables developers to focus more on value-adding activities (building new features). Platforms and infrastructure can also be provisioned quickly, even if that solution is on-prem.
- Business Agility. Businesses can be more nimble to the needs of their customers, who (in the main) don’t care who manages your infrastructure. In some cases the business can also migrate from one cloud vendor to another; for example if one vendor’s cost model becomes more attractive.
- Focus on Innovation. See my point on focusing on the right thing.
- Ability to scale. Dynamic scaling is a difficult problem (e.g. elasticity), particularly when workloads are spikey (have many peaks and troughs). A PAAS can manage these aspects for us.
- Portability. Some PAAS solutions support a range of migration and Evolvability options - from on-prem to public Cloud, or even swapping cloud providers (for increased Business Agility). An on-prem solution is still extremely appealing to some organisations (e.g. government, finance) who manage extremely sensitive data they need ultimate control over (Control), or simply aren’t yet sure of the public cloud. In these cases, the PAAS is deployed to that organisation’s data centers, the organisation still benefits from faster TTM, yet it still retains a level of Control.
- Frees up operational teams to do more innovation.
Sounds too good to be true? There are some potential pitfalls, mainly around some loss of Control and Flexibility, directed at choice. There’s also some tie-in considerations. Even if the vendor offers sufficient choice now, will they continue to for future innovation?
VALUE-ADDING ACTIVITIES
Whilst there are many value-adding activities linked to software creation and delivery, to my mind, the single most valuable output is from development activities (which is - of course - a collaboration of many other roles and activities, including customer, business analysis, product development, testing, operations, security etc).
Developers are amongst the highest paid in the IT industry. And development activities are often (quite sensibly) the lengthiest. Thus, does it make sense for those developers to regularly context-switch (between development and non-development activities), such as provisioning infrastructure, or manual deployment? Whilst I’m all for T-shaped Personnel, it shouldn’t create a constant drain on development activities if that’s where the main value is delivered.
PARADOX OF CHOICE
A sometimes crippling problem of which we are all susceptible to relates to an abundance of choice (Paradox of Choice).
In this case we’re talking about solving problems. There are many ways to solve a problem - some better, some worse - but deciding upon one often takes significant cognitive effort, and time.
A PAAS is “opinionated”; it makes certain Assumptions (or limitations) about what you can and can’t do. This approach benefits the vendors - they don’t need to offer every conceivable service; and it benefits the customer by not overloading them with choice (creating a Paradox of Choice).
Common examples of a PAAS use Containers & Orchestration techniques to manage workloads, and provide (at least) the following facilities:
- Continuous (CI/CD) (e.g. pipelines) and DevOps facilities.
- Container management.
- Declarative over Imperative management.
- Resilience and autonomicity. Failing containers are killed and automatically restarted. They’re Cattle, not Pets.
- Centrally managed logging and alerts.
- A marketplace. Most offer third-party services through some form of marketplace.
FURTHER CONSIDERATIONS
- IAAS (Infrastructure-As-A-Service)
- SAAS
- Declarative over Imperative
- Containers & Orchestration
- Assumptions
- Paradox of Choice
- T-shaped Personnel
- Control
- The Cloud
- Innovation
TEST GRANULARITY
Numerous types of testing (Types of Testing) are available. Individually, each is suited to solving a particular problem. For instance, penetration testing tests software for certain weaknesses, whilst integration testing proves independent components can communicate together successfully. They’re very specific tools to solve very specific problems, and don’t attempt to instill every desirable characteristic needed for business success.
Combining testing types though, forms a powerful tool that both protects quality (and thus Reputation), and may also promote Innovation and Productivity. However, good ROI is rarely achieved through blanket coverage, but through the careful application of the correct testing type(s), applied in the right quantity, nothing more. To do so, we should understand Test Granularity.
Much has been written about the Testing Pyramid [1] (credited to Mike Cohn), and rightly so. It is a useful guide, or heuristic, not only to understand how and what to test, but also in considering where best to invest testing effort. I’ve taken the original concept and given it a more explicit slant towards granularity.

This pyramid has three tiers:
- Top tier. The coarsest grain of testing occurs here, and typically includes End-to-End (E2E) or UI testing (the interface between the user and the software). We can achieve high business (product) coverage here (quality through confidence) if we also link up with the lower tiers.
- Middle tier. Medium-grained tests - such as acceptance and integration tests - typically occur here; they test a useful feature that binds together some of the smaller “units” (tested below).
- Bottom tier. The finest grain of testing (e.g. unit tests) occurs here. You’ll (probably) get very low business coverage here but Fast Feedback of the area being changed.
DOWNWARD TREND
There’s no golden rule about how great an investment should be made in each tier (e.g. 20%, 30%, 50%) - that depends upon the solution - but there should be a general trend of increased coverage as we travel down the pyramid.
WHY TEST?
Before we continue, let’s revisit some of the key benefits of testing (Why Test?). Testing promotes:
- Confidence, both in ourselves and from others (i.e. customers). This confidence is achieved through quality verification, and can be seen either:
- By demonstrating a certain degree of test coverage, of the correct testing type(s), and in the appropriate place(s).
- By prospective customers witnessing the success of your solution in a LIVE setting (the ultimate form of testing), and wanting a piece of that pie.
- Fast Feedback. This is not to promote external, but internal, confidence (although the outcome of this internal confidence will also shape external perception and confidence). However, it's mainly to provide some form of haptic feedback, enabling staff to test hypotheses and change direction quickly and safely, thus promoting Innovation.
How we manage Test Granularity has some important considerations:
- Generally, there should be fewer coarse-grained tests than fine-grained tests.
- Tests should exist at each tier, thereby promoting “defence with depth” (similar to the “defence in depth” concept in security, except in this case we’re defending quality, Agility, and TTM). Confidence (a Safety Net) is gained by building upon the tests of preceding tiers.
- Tests at the same granularity of the behaviour being tested should (generally) be tested by the corresponding testing tier; bottom-tier-tests test units, top-tier-tests test the highest-grained flows. Prefer not to test finer-grained units solely with higher-level tests (see my rationale in the section below entitled “Testing at the Right Grain”).
- Business systems coverage. You’ll note that the more granular testing provides Fast Feedback but low business coverage, whilst more coarse-grained testing provides slow(er) feedback, but (assuming support from the lower layers) provides high business coverage. High business systems coverage leads to high overall confidence by all stakeholders, and why we should promote a tiered approach to testing.
- As we progress up the pyramid, we find more moving parts (dependencies), increasing brittleness and (potentially) reducing test run reliability. This is particularly true when we introduce remote dependencies (i.e. unreliable networks).
- Execution time. Time is money, as they say. More moving parts increases setup effort, which increases execution time, and thus affects our ability to Learn Fast. Not only do tests help to safeguard quality, they also provide a Safety Net (particularly useful for Innovation). Yet we lose that advantage when we embed tests that are so sluggish they’re either ignored or disabled.
- An imbalanced (top-heavy) pyramid may cause a diminishing return on investment (ROI), as unnecessary effort is spent managing slow or brittle tests that should be pushed down the pyramid.
- Where sensible, we should demote tests from higher to lower levels. See earlier points on Fast Feedback and diminishing ROI.
- Duplication of tests. It’s common for the same behaviour to be tested again in successive tiers. This isn’t always necessary, adds complexity and maintenance challenges, and also increases execution time. Undertake sufficient testing at each layer to gain the necessary confidence, but no more.
TESTING AT THE RIGHT GRANULARITY
I’ve seen occasions where the promoted testing type (and its granularity) didn’t fit well with the software under test. For instance, I’ve seen Microservices barren of unit tests, but replete with acceptance and integration tests.
Certainly it was better than having no tests, but it created challenges with on-boarding as:
- Developers were expected to have a local environment (e.g. a local database) installed, configured, and ready to use.
- The APIs were authenticated, requiring an API key to be available, even with local development.
- Test runs were slower. Whilst not deeply significant, it caused frustration when fast feedback was desirable.
- Testing was more complex and required a greater understanding of the higher-level context, just to test a lower-level unit.
- Data cleanup issues when the tests failed to complete successfully.
FURTHER CONSIDERATIONS
- [1] - Testing Pyramid - Mike Cohn - Succeeding with Agile
- Types of Testing
- Learn Fast
- Safety Net
- Innovation
GRANULARITY & AGGREGATION
Understanding how the constituent parts of a software solution relate can also help us to contextualise other aspects, such as how software is tested or released. The following diagram shows those elements.
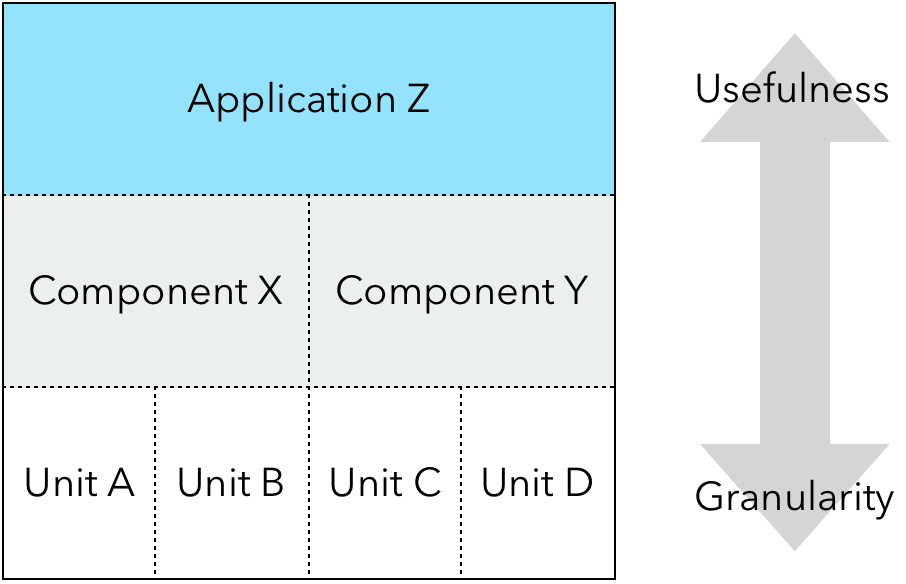
There are three types (or grains) of software elements:
- Application - the highest-level element, and one that users can interact with.
- Component (or service) - a more specialised unit, typically representing a (business) domain (e.g. the carts domain). Whilst some users may interact with a component directly, it’s more likely done through an application’s user interface (UI).
- Unit - the lowest-level unit, typically representing a fine-grained concept (e.g. a zip code validator) that may be grouped with others to form something useful. Users rarely interact directly with units; they therefore offer the least direct usefulness to users.
To reiterate, a component (or service) is composed of one or more units, whilst an application consists of one or more components.
GRANULARITY & USER VALUE
Note that I’m not suggesting that units have zero value (they’re critical aspects of a software system); I’m simply stating that their usefulness depends upon their user accessibility, and that's typically determined by the coarser-grained abstractions.
APPLICATION ARCHITECTURES
The type of application architecture also plays a part in how software (value) is tested or released. For instance, a Monolith (or a historically Tiered-Architecture), may limit how accessible units and components are (or “when” they become accessible), whereas a Microservices (or Serverless) style better leverages an early access approach.
FURTHER CONSIDERATIONS
WHEN TO TEST?
“Common sense is not so common.” - Voltaire.
Sometimes we are so busy considering what and how to test, that we forget to ask a more fundamental question. Should I test?
Whilst that may sound contentious, it's meant to raise more fundamental questions around both the value of testing, and the importance of timing.
Writing tests for something that’s highly fluid and evolving, chaotic, or untested within the market, may be too soon, especially if it's only going to change into another form, or be discarded. Every test written (and undertaken) has both a financial and a time cost. You'll get zero return on a suite of tests if the overarching solution is discarded due to low value to the customer, poor market reception, or that it simply doesn’t work!
IMPEDING INNOVATION
Some tests can actually impede change. For instance, if we embed implementation Assumptions into our tests, yet find that implementation requires a major overhaul, then those tests must either be discarded or rewritten, causing a reduction in velocity.
To my mind, structured testing should occur after a progression from Innovation towards a more established path, thus enabling us to provide a good return, and not impede innovation. If it's truly an unknown, and the way is murky and far from obvious, with radical change likely, then adding structured testing too early is nonsensical, and may inhibit, rather than propel you.
Before introducing structured tests, we might consider:
- Will the tests help to increase product quality?
- Will the tests provide Fast Feedback?
- What is the lifetime, and change cycle, of the solution? Is it short, with limited change (make a low investment), or long, with significant change (make a larger investment)?
- Is there some regulatory aspect that requires us to undertake formal testing?
- How critical is an immediate product release to the business? You might do this if you see a gap in the market, or to show something at a trade show, and opt (initially) not to introduce extensive testing.
- Are you interested in the quality of the solution, or the quality of the outcome? For example, if you’re migrating data from a legacy system to a new system, and it's only done once, then it's probably the outcome that matters, not the solution. There’s no need to invest heavily into the unit, acceptance, or integration testing of the solution’s internals, when you only care about the data quality at the other end.
FURTHER CONSIDERATIONS
TYPES OF TESTING
Testing comes in many guises, including: Unit, Acceptance, Integration, UI, Load, Volume, Regression, Penetration, Smoke, Endurance, Stress, Exploratory, Contract, and End-to-End (E2E). Each form of testing solves a specific problem, or furthers a cause (Why Test?).
FURTHER READING
Before continuing, it may be worthwhile reading the Granularity & Aggregation section. Also, note that this section is merely an overview of the various testing types.
The following diagram shows where each testing type is normally applied.
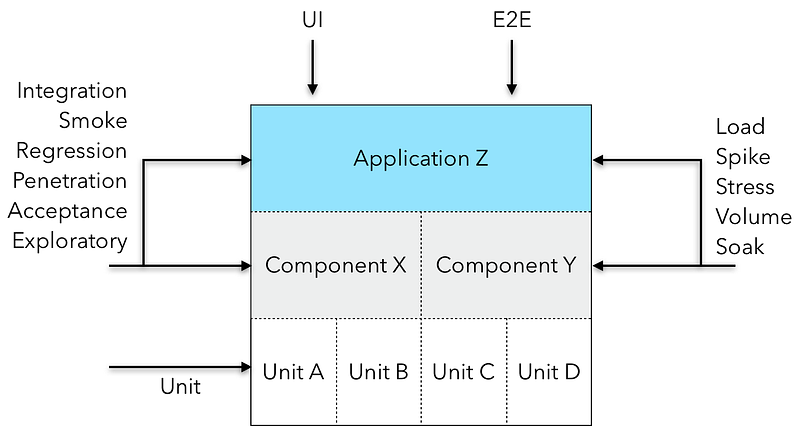
Naturally, since value is most obvious at the user interaction level, we find that most testing occurs at either the component or application layer. However it’s also worth noting that some types of testing may be deployed across multiple layers (or grains); e.g. Integration Testing may be undertaken at application or component level.
The mind map below acts as a visual cue to the various forms of testing.

Broadly speaking, they can be classified into one of two camps:
- Test the functionality behaves as expected.
- Test the system behaves as expected.
I’ll briefly describe them below:
- Unit Testing. A fine-grained, developer-led test that tests the lowest level units function as expected. See Unit Testing.
- Integration. Proves that all of the parts making up a solution can successfully communicate (not necessarily that they function correctly). See Integration Testing.
- Acceptance Testing. Proves that the feature behaves as expected and can be delivered to customers/end-users. See Acceptance Testing.
- End-to-End (E2E) Testing. Tests the entirety of the solution, from the interface nearest the user (UI) all the way down to backend services and the data. See End-to-End (E2E) Testing.
- Regression Testing. Ensures that the existing components or features continue to function as expected, remaining stable typically after some type of change or enhancement. See Regression Testing.
- Smoke Testing. A coarse-grained form of regression testing that checks key functions work. Smoke testing is meant to execute quickly. See Smoke Testing.
- Load Testing. Ensures the system caters to an agreed load (the maximum number of expected concurrent users), and thus meets its Service Level Agreements (SLAs). See Load Testing.
- Stress Testing. A form of performance testing aimed at finding a system’s breaking point. Stress testing is useful to understand how well your systems (and thus business) can support an increase in growth (scale up). See Stress Testing.
- Spike Testing. A form of Stress Testing, specialising in testing how well a system responds to extreme scale, over a very short timeframe. See Spike Testing.
- Volume Testing. The practice of adding (large) volume to a data store to view its behaviour. It more accurately answers how a system responds to large data volumes. See Volume Testing.
- Endurance Testing (also known as soak testing). Simulates a (peak) load, for an extended period, to identify potential weaknesses affecting system stability, and visible behaviour. See Endurance Testing.
- Contract Testing. Typically used with APIs to ensure that a dependent service doesn’t break when the contract it depends upon changes.
- Exploratory Testing. A less formal (but important) form of test that attempts to find flaws in software that more formal avenues may not. See Exploratory Testing.
- Penetration Testing. Tests software to assess both its strengths, and its weaknesses. See Penetration Testing.
FURTHER CONSIDERATIONS
REGRESSION TESTING
Suggested Read: Case Study A
Consider the scene. The team at Mass Synergy has spent months creating their first iteration of their product. It's been a hard slog, but well worth the effort, with customers clambering for more features.
The team is asked to build new features to meet demand. Unfortunately, the second iteration doesn’t go so well. The team is so intent upon delivering the new features that they neglect some aspects of the release, and find that it doesn’t integrate well in production with their existing product features, causing the catalog component to not present certain products to a subset of customers. It's embarrassing, frustrating to users, and the bad publicity - seen through social media - may even affect Mass Synergy’s hard-won reputation.
“How could this have happened?” asks Daphne, perturbed, at the wash-up meeting. The team answers - rather sheepishly - that they didn’t anticipate the new changes would affect any of the existing product features, so they never undertook a full regression test. The bug is quickly fixed in production, but unfortunately some damage has been done. It will take some time to regain customer trust, and the plan to on-board other retailers onto their SAAS product is suspended. Internal relationships between shareholders and the product team have also deteriorated, creating friction due to more micromanagement.
That, in a nutshell, is what regression testing offers - a way to ensure that any existing components or features remain stable after a change (as change causes Entropy). We do this to protect our reputation, improve longer-term TTM, and for our own sanity.
REGRESSION COSTS
A full regression test provides great confidence; but at a cost. You must either invest in manual testing (which is onerous, costly, and error-prone), or invest in automating a suite of regression tests (which doesn’t happen overnight, and is also costly). The advantage of automation is that staff who aren’t spending time (money) manually regression testing can reinvest it back into the business in other ways - such as increasing quality, improving flow, or adding new features.
FURTHER CONSIDERATIONS
FLOODING THE SYSTEM

Flooding occurs when a system is exposed to a load beyond its capacity and it is unable to meet demand. It's a problem that (many) businesses have been affected by (consider the failings of some retailers during Black Friday deals, news websites during a significant event, or Pay-Per-View sporting events that couldn’t meet demand).
Flooding the System may - in some cases - be catastrophic to a business for the following reasons:
- It may leave the system - and its data - in a (strange) inconsistent state that is hard to understand, or rectify.
- The system may stop accepting valid customer requests, or purge existing requests already in it.
- It may cause reputational damage (Reputation), and reduce confidence (due to the above issues), potentially at a critical point in the business plan.
- Internal stakeholder confidence may be shaken, creating a void that others may fill.
Flooding is generally caused when a larger than anticipated number of users (which may be physical users, or other systems) access the system concurrently. It may occur unintentionally (e.g. a bug in the software, or an unplanned-for activity), or through some form of malicious activity (e.g. an external party performing a DoS attack). The diagram below visualises the problem.

Ok, it’s somewhat fabricated, but it should demonstrate the general principle. In this case, we have four water tanks, connected together in series (sequentially) through ingoing and outgoing pipes. The purpose of these water tanks is irrelevant in this case, only that they exist. The pipes can handle up to 10 gallons of water each minute. Each tank has a maximum fill and pressure capacity (between 3-8 gallons). Water enters from the left and is fed all the way through the system, before cycling back out (see the direction of the arrows).
Let’s start by pumping 1 gallon of water through the system every minute. No issues here. Doubling it to 2 gallons a minute - likewise - has little effect. The diagram below shows what happens when we reach 3 gallons a minute.
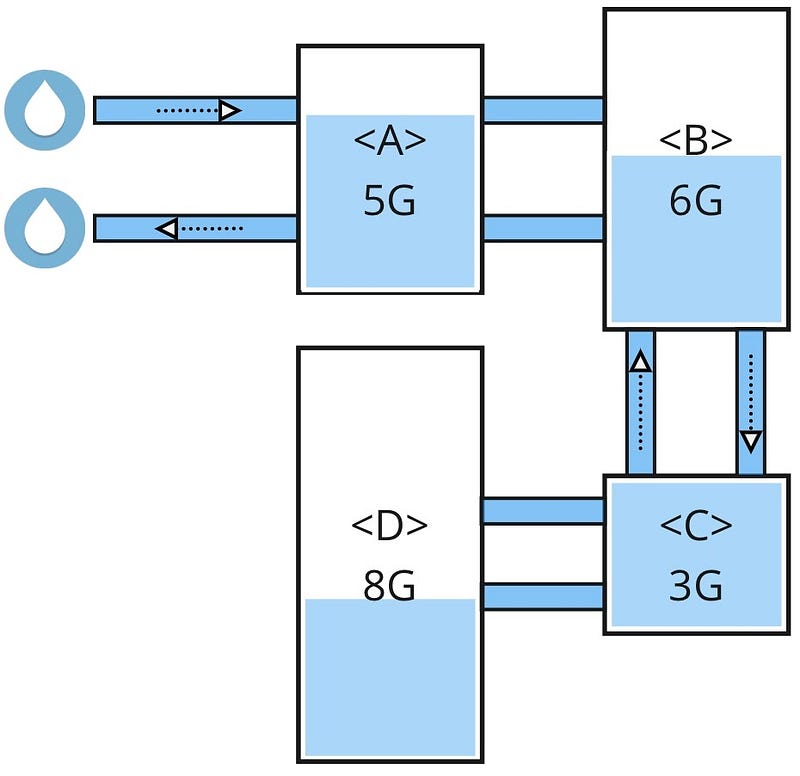
Whilst there’s no external issues (the water is still entering the system), anyone inspecting the system’s internals would find Tank C cause for concern - now being at its maximum capacity. Let’s not stop there though. At 4 gallons a minute, we begin to see noticeable problems.
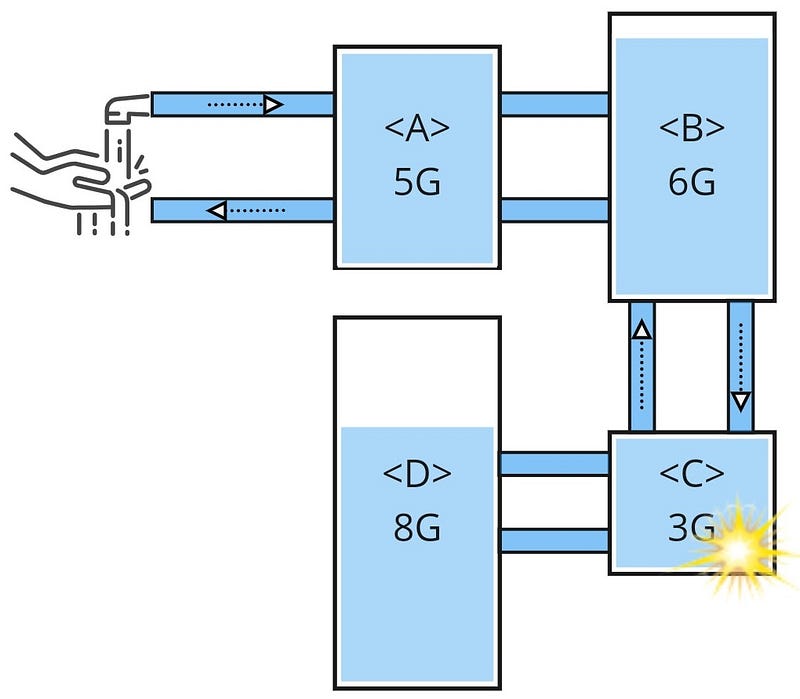
COMPLEXITY
It's worth pointing out that how it actually fails (i.e. which parts of the system fail, the order in which they fail, and how disastrous the outcome is) is very hard to predetermine (an attribute typical of a Complex System). Supplying the same stimulus again may not produce the same outcome. I’ve presented some possible outcomes below.
The system begins to fail in one (or all) of the following ways:
- Constraint Pollution from tank C. The other tanks in the system are affected and must deal with C’s capacity issues (they are polluted by C). The water entering the system must go somewhere, but it can’t get to C (or to D), so it starts to fill the upstream tanks (A and B). Tank D may also fill, being unable to return water back to tank C. Note, however, that all tanks aren’t necessarily full (D is fuller, but still has some available capacity) when the system completely fails. The state of the system may not be observable to external parties yet.
- There is an (eventual) “chain reaction” (a cascading failure), causing a noticeable external effect. The water is still entering the system (at a rate of 4G per minute), but is no longer being received by the system, instead it’s being forced back out and lost. This might occur if the upstream tanks are also swamped.
- At some stage, Tank C’s structural integrity fails, rupturing due to sustained pressure. It can cope with 3G of pressure, but not 4G. When this occurs, everything currently within the system is (probably) lost, alongside anything new entering it. Additionally, anything downstream of tank C (i.e. tank D) can no longer push water back out that way, and anything upstream of it (tanks A and B) either cannot push their reserves down (or can, but all that water is lost through the ruptured tank).
- Tank C is now useless and needs replaced. Yet a like-for-like replacement isn’t viable when the same volume of water is still being pumped through - that same tank will fail again and again.
- We have no way of knowing how much water successfully completed its circuit (reaching tank D), as the feedback loop is broken. This point may not seem important within this context, but it will when we discuss software systems and users (next).
THE WEAKEST LINK
With the series model, you're only as strong as the weakest link in the chain; i.e. the entire system is only as strong as the worst performing part. In this case, that’s only 3 gallons of water per minute; not 8 gallons, nor the 10 gallons capacity of the pipes.
SYSTEMS CONTEXT
The water flow analogy described previously closely mirrors the flooding problem in software systems. In the software sense, the pipework linking the tanks together is a software workflow, and each tank represents an individual software component called by that workflow. See a (simplified) example below (taken from Case Study A) for an online retailer’s cart checkout pipeline.

We’ve replaced the concept of moving water around a system with one where we move user requests (or paying customers, if you prefer) through the system. There are four components in this workflow (to keep things simple, but it could be as many as needed). Users make requests upon the system, entering the system from the left and (often) expect an almost instantaneous response. Flooding - in this sense - occurs when a large number of concurrent user requests enter the system in close proximity.
Again, let’s assume the penultimate component (Orders.createOrder) has the least capacity, and begins to fail. See below.

And now let’s revisit the issues identified from earlier, but in the context of our software system. Firstly, note that we're still dealing with very similar problems:
- The first two components (Catalogs, Discounter), and last component (Fulfilment) begin to fill up with user requests that the Orders component cannot process. Other than some internal dashboarding and alerts - indicating longer request latency or high system resource usage - this issue may not necessarily be observable to external parties yet. We must also beware of other components in the workflow also reaching full capacity due to the Orders component.
- A cascading failure occurs, leading to a noticeable external effect. Whilst user requests are still pouring into the system, the entire system is no longer receiving them, forcing out new user requests, where they are lost.
- The structural integrity of the Orders component eventually fails, rupturing due to the sustained pressure. When this occurs, we’ve basically lost everything currently in the system, and potentially anything new that's entering it. Communication between the Catalogs/Discounter and Orders components ceases (as it does between Fulfilment and Orders), and all requests are lost. The existing instance(s) of the Orders component is now useless and needs replaced. Yet a like-for-like replacement is insufficient if the same volume of user requests is pushed through - all instances of Orders will fail again.
- We have no (easy) way to identify how many user requests completed (fulfilment), as the feedback loop is broken. If the penultimate component (Orders) fails, yet the final stage (Fulfilment) successfully completes the transaction, the user is never informed, yet they may now have a service entitlement. Alternatively, the retailer might fulfil a service without having a record of it in their system (this falls under the guise of Perceived v Actual Consistency - what is believed differs from reality).
What this means is that we have three significant problems to resolve:
- Customers who want the service but can’t get it because the system is flooded.
- Customers who've received the service, but don’t know it, thinking their transaction failed.
- Inconsistent business records. Some transactions are fulfilled, but don’t have a corresponding business record (order) in the system.
ALSO CONSIDER THE PIPELINE
The workflow (pipework) also needs consideration. There’s little point in proving that the underlying components can hold sufficient capacity if the workflow (pipes) linking them all together cannot. The entire workflow capacity needs tested.
SUMMARY
So how can we tackle this problem? Firstly, you might ask if there is a problem? Do you have any important workflows that run sequentially (in series)? Does your business support a user base that could flood the system? Maybe you’ll never run into this problem? But can you be sure if you have no metrics to back up your claims?
The safest thing to do is to undertake some Performance Testing (e.g. Load Testing). If you discover a weakness, there’s a few proven techniques:
- Use Horizontal or Vertical Scalability. This is probably the simplest option - either increase the resources to existing instances, or increase the number of available instances - and certainly a sensible starting position, but it's not always possible or sensible (e.g. high-cost licensing).
- Retain the sequential flow, identify the weakest component (the bottleneck), and improve it beyond the worst case. Testing at different grains works well here - you can test and improve each component individually (gaining Fast Feedback), then link it up to the other components in the pipeline (which have also been tested), before undertaking a final performance test of the entire workflow. This approach may be repeated with every bottleneck until the SLA is met. However, bear in mind that a change to any depended-upon component could break that SLA, so it's worthwhile to regularly performance test that solution.
- Isolate the components (with Bulkheads, or an event-driven architecture). If components are truly isolated, then a failure in one need not pollute/affect any of the others. Bulkheads are a well-established pattern for dealing with potential flooding by placing bulkheads (typically queues) between each component. Each component processes messages at their own speed, without others dictating their velocity. Yet, there’s no such thing as a free lunch. What you gain in Scalability (for instance), you may lose in the additional complexity, and eventual consistency models they require. It may also require your business to change how it interacts with its customers (and how reports are run on them) as the eventual delivery model (of a service, to a customer) takes centre-stage.
FURTHER CONSIDERATIONS
EXPLORATORY TESTING
“No plan survives contact with the enemy.” - Helmuth von Molkte.
No, I’m not really suggesting that the user is the enemy! But they do have a habit of finding flaws in a system that more structured testing approaches sometimes overlook. Thus, there’s something to be said for a less predictable testing approach, such as Exploratory Testing.
Exploratory Testing is typically undertaken after the structured testing is complete. By following a less predictable path (unscripted) it can uncover flaws in software that are difficult to preconceive through structured testing. Being unscripted, it's typically undertaken manually.
VALUE
Exploratory Testing may be less structured or formulaic than some other forms of testing, but that doesn’t mean it's without merit. It can find peculiar bugs or user experience issues that would be difficult to find using other tests.
Whilst a tester performing exploratory testing likely has no formal test plan, they may have decided beforehand where to focus. And whilst their actions during the test may seem arbitrary (clicking selectable items in a random order, manually refreshing the page to see if it behaves unexpectedly etc etc), they may indeed more closely reflect how some legitimate users behave. Exploratory Testing need not be undertaken by someone with the formal title of “tester”, but by anyone with some experience of a software product (e.g. product owner) looking to improve its quality.
SMOKE TESTING
Suggested read: Case Study A
The term Smoke Testing is thought to originate from the electronics world (although it may actually have originated much earlier, from plumbing), where sometimes the only way to test a new circuit board is to switch on the power and wait to see (or smell) what it does. I’ve done this a few times myself. If it smokes, or one of the chips blows, then something is wrong, and we must stop and fix the problem. It’s not ready for use, or for any further (or detailed) testing.
This is also true of smoke testing in software. If we deploy a new system or service to an environment (switch it on), a smoke test should determine whether we invest more time on it. If it passes, we may progress to more substantial testing, otherwise, we send it back. It's designed to catch conspicuous, but fundamental system failures, and prevent further investment in a flawed release. To be useful, smoke testing needs to be one of the first tests executed after deployment.
THAT SOUNDS LIKE REGRESSION TESTING?
Indeed it does. Smoke Testing is just an extremely swift form of regression test. Whilst with regression testing, we might test many aspects of a system for flaws, Smoke Testing only tests that the main arteries of the system - the key ones - are still in good working order.
Why undertake smoke testing? Let’s return to Mass Synergy. Imagine that Joe is given a new product release to test. He’s told that a change has been made in the Fulfilment component to incorporate a new delivery service provider. Joe immediately sets out to test the solution. He spends a few days testing it, and finds it to be good, mentioning it to Ralph as he passes. Subsequently, Joe decides to quickly regression test (Regression Testing) some other parts of the system, starting with the (critical) Carts component.
Very soon though, Joe finds a serious problem, and after further investigation tracks it down to the change in the Fulfilment component he’d just tested (and passed). Joe is fuming - having wasted a lot of time for nothing. So too is Ralph, his manager - having already told the executive team that the release will be deployed as planned - and must now backtrack.
IT'S THE SYSTEM, NOT THE PERSON
The source of the problem here is not the person, but the system (to paraphrase Deming [1], who suggested that 94% of all problems stemmed from the system, not the person). The business has wasted valuable time, money, and (team) morale verifying the quality of a release of questionable quality, when they could have tested its worth much sooner.
APPLYING SMOKE TESTING
What areas of your system should you apply this technique to? Consider the main arteries of your system - the ones so critical to the business that any flaw should cause the immediate rejection of a release.
At Mass Synergy, the catalog and cart management rule supreme. Without them, the customer is stranded, a predicament both costly and harmful to business brand and reputation. So, they should be smoke tested. They won’t catch all regression issues, but they’ll identify the major ones, and allow us to decide if further testing is sensible.
Smoke testing follows the “mile wide, inch deep” mantra, offering:
- Fast Feedback (i.e. better TTM and ROI).
- A relatively easy way to gain confidence in the stability of a software release.
FURTHER CONSIDERATIONS
VOLUME TESTING
Suggested read: Case Study A
The database (or datastore) is often the nexus for an entire system or component; yet it can fail spectacularly in many ways. Overlooking the growth demands of a product, business, or set of customers is one such example. Volume Testing is the practice of adding (large) volume to a data store to see its behaviour.
TERMINOLOGY
I’ve used the term “datastore” here (rather than database) to indicate that any form of data storage (from in-memory caches, to disk storage, to databases) can fail, due to large data volume. In many cases it probably is a database, but it need not be.
Datastores have finite capacity (even the Cloud-based ones). Underprovisioning storage starves the system of the resources it needs to do its job, whilst overprovisioned storage ensures it meets excess capacity, but may incur unnecessary licensing and operational costs. There's a happy medium to be had (Goldilocks Provisioning), but how do you decide what that is?
CALCULATING STORAGE REQUIREMENTS
Pre-calculating the number of entities created per user transaction, and their storage space, may not be as simple as it sounds. It's one reason why testing the outcome is important.
Let’s consider two customers who sign up for Mass Synergy’s service:
- Mr John Doe.
- Captain Jeremiah Haversnooky.
We'll start just by capturing their names in a “customer” table. Notice that there’s (probably) three distinct fields (title, forename, surname) used to represent each customer name. The length (and therefore storage size) of each field is quite different (e.g. the surname of “Doe” is 3 characters, while “Haversnooky” is 11 characters long, almost four times the size). Also note that this data is very fluid/dynamic - they’re attributes of an individual, which can vary widely per person. If we were to look at other dynamic fields, we’d find this pattern repeated across the system.
Addresses - for instance - differ not only between streets, but between regions, and even countries (some countries don't have post-codes). User choice also creates fluidity, and therefore unknowns. John Doe may only purchase a single cart item, but Jeremiah Haversnooky might purchase twelve and then receive several discounts for his loyalty.
My point is that systems regularly capture this type of data (a system might capture hundreds of these dynamic fields per transaction), and it’s (almost) non-deterministic. Storage needs may be shaped by:
- Who the customer is - e.g. cultural influences.
- Where the customer is - e.g. geographical location.
- The customer’s motivations - i.e. a choice selected by the customer, such as the items being purchased.
- How the system interprets this information. For instance, the system may use a machine learning algorithm that only runs for certain customer criteria (e.g. any US resident, under twenty, that purchases books about technology).
We’ve the beginnings of a Combination Explosion, hampering our ability to predetermine how our Complex System will behave.
In the diagram below, you can see the two customers (Haversnooky in Green, and Doe in Red) accessing different services, or doing so a different number of times. The numbers within the red and green circles represent the number of times something is stored for that transaction (note that Haversnooky creates 12 cart items and receives 2 discounts). I’ve assumed 1KB of data being stored per interaction to keep things simple.
The end result (for this scenario) is that Jeremiah Haversnooky stores 17KB of data for a single business transaction, to John Doe’s 3KB.
Ok, so now we know all this, should we have a go at precalculating how many gigabytes of storage we need to capture 100,000 customers? I’ll let you go first.
Give up? Me too! Whilst we could attempt to calculate an average, it’s still just an estimate. A better option might be to try it.
Unexpected volume can come from other sources too. If your users start using your solution in a different way, or for a different intent, then we may find they store more data than the system designers originally intended.
VOLUME TESTING MICROSERVICES
If you follow the Technology per Microservice mantra, then you may have one datastore per microservice (not one per instance of course). In this case Volume Testing may occur at both the microservice and system level. Volume Testing at the microservice level will provide fast feedback, and allow you to tweak storage settings at a finer grain.
Resolving a data storage issue can be an involved investigation. It’s not something you want to be doing just prior to a key event in your business’ corporate calendar. By capturing metrics - through a Volume Test - we can better understand how (or if) a system will cope if thrown a large quantity of data for storage. At its most basic level, we pump data into the datastore until it reaches a threshold. See below.
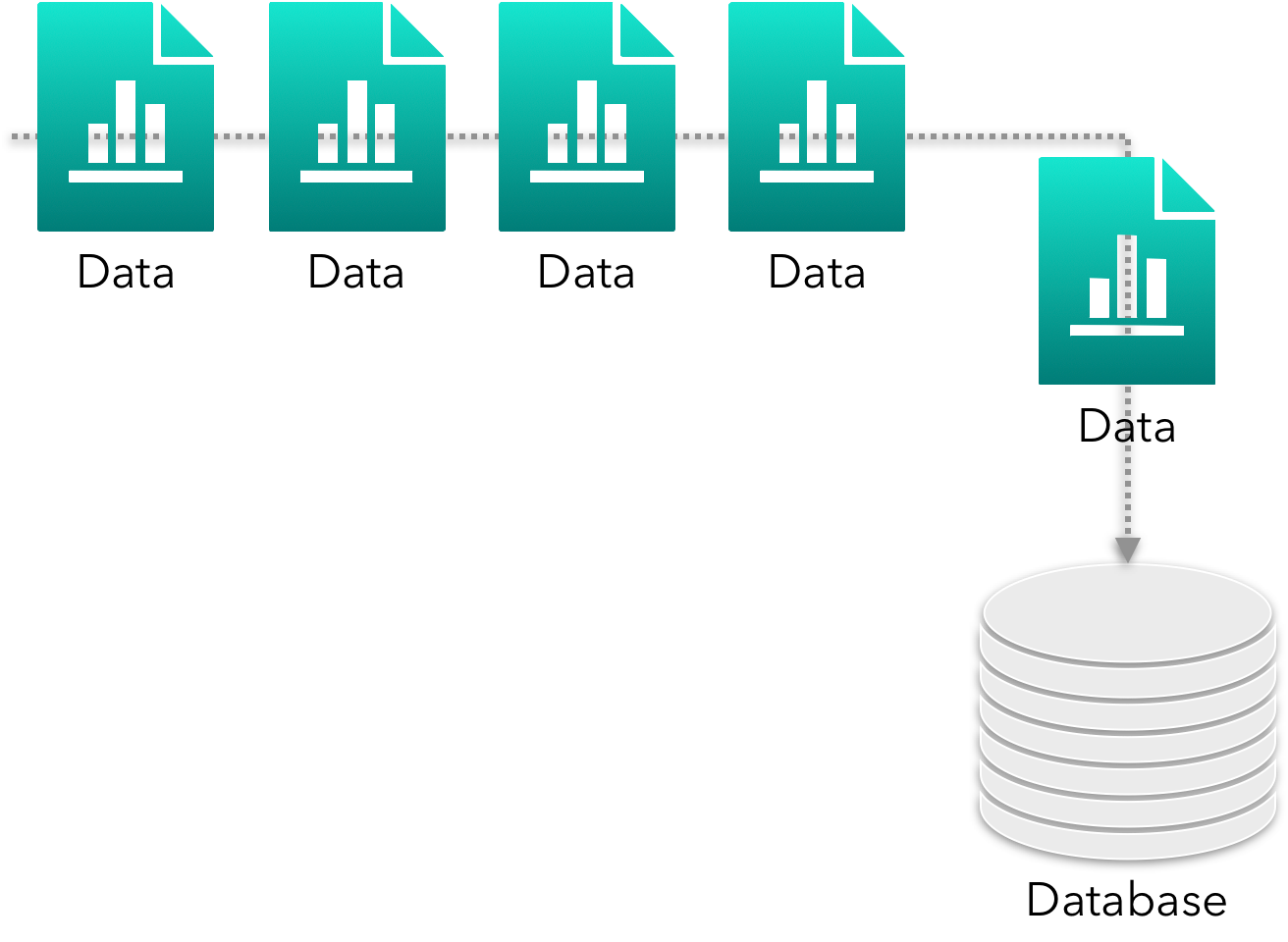
As described in the Flooding the System section, attempting to force five gallons of water into a water tank made for three will likely end in disaster. It either breaks the system for all, or (at the very least), causes some water to “escape”. This analogy is also a useful way to describe how to manage data volumes. Flooding a datastore to capacity may cause:
- The escape of valuable data (and therefore of new custom).
- The failing of the datastore for all users (potentially affecting all custom).
Neither case is desirable.
VOLUME AND LOAD TESTING
Volume is an important consideration in other forms of performance testing too. A system empty (or sparse) of data behaves quite differently to one managing hundreds of thousands of rows.
I’ve seen Load Testing undertaken for a client on an empty test datastore (i.e. zero volume), suggesting that it accurately reflected a LIVE system containing hundreds of thousands of records. This simply wasn’t true and created an unfounded confidence in both the solution, and the accuracy of the load testing.
An accurate test should mirror a LIVE environment as closely as possible, and include:
- Comparable infrastructure; i.e. identical instances, running on the same Operating Systems, and using the same underlying hardware.
- A comparable LIVE-like dataset. Regulatory rules (e.g. GDPR) may prevent the duplication of LIVE datasets, but it’s possible to closely mimic them.
- The accurate mimicking of user traffic, in terms of quantities, timings, and actions.
SUMMARY
The theory about how a system should handle large data volumes isn’t always grounded in the reality of Complex Systems. Myriad things could affect storage capabilities, yet my experience indicates that many stakeholders have an Oversimplification Bias towards its calculation. This can create friction - get it wrong and people will question how you could get something so “simple” wrong, creating a second-order outcome where engineers play it safe by overprovisioning, thus creating unnecessary operational costs (e.g. licensing).
Volume Testing allows us to work more objectively, using metrics captured through system usage patterns, rather than based upon subjective theory. And whilst we can’t completely remove subjectivity, even in the tests, the practice of volume testing more accurately answers how a system responds to large data volumes.
FURTHER CONSIDERATIONS
LOAD TESTING
Suggested read: Case Study A
Load Testing is used to help us understand how a system responds if the maximum number of expected users were all to access the system concurrently. It helps to confirm an expectation that the system meets an agreed Service Level Agreement (SLA).
TERMINOLOGY
The term “load testing” is often overloaded as a catch-all term for any load-based testing activity; such as stress testing, or soak testing. This isn’t entirely accurate, since the activity of load testing is distinct and serves a specific purpose.
Let’s return to Mass Synergy. If you remember, the team agreed the following SLA for the customer purchase flow:
- 100,000 concurrent users.
- <= 2 second response times.
- At the 99th percentile (Percentiles).
This equates to up to 2s response times for 99% of requests of up to 100,000 concurrent users. Joe has been tasked with implementing a test plan to prove the system meets this capacity. The major steps in the customer purchase flow are shown below.

Note that some of the flow repeats (e.g. you can view the catalog, add an item, then return to view more of the catalog). I’ve marked each stage with a green circle to indicate how many times that stage can be called (1 = once, N = multiple times).
Joe plans to undertake a Load Test, ramping up the number of concurrent users till it reaches the anticipated maximum (100,000) at around the 1 hour mark, and regularly measuring its performance. However, before doing that Joe must first decide how he’ll simulate the desired load.
FALSE ECONOMY
Whilst we could ignore this test, doing so may create a false economy in which we think our system is in a better state than it actually is, discovering (the hard way) when it affects real customers in the production environment. This is not “customer-focused”, nor is it proactive.
Simulate? Yes, simulate. Firstly, there isn’t a large group of customers standing by to test Mass Synergy’s software, so they’ll need to be mimicked, using machines and software. Secondly, we should not undertake this test in the production environment, lest we break it, so we need an equivalent environment to mirror that production environment and simulate load on it. Joe needs to simulate how those users will behave, and that involves a discussion on Assumptions.
UNDERSTANDING & MIMICKING CUSTOMERS
‘Just make the test do what our real customers do,’ suggests Daphne.
‘Unfortunately it's not that simple,’ replies Joe. ‘Simulating such a vast number of different users, each with individual (or distinct) characteristics is very difficult. Whilst we can base some of the dataset on real users, we’ll still need to make some assumptions to undertake the testing in any sensible timeframe.’
‘Sorry, I still don’t follow Joe. What individual characteristics do you mean, and how does that affect testing?’
‘Well, each customer has distinguishing features and behaviours that affect how they interact with our system. For example:
- Who they are. Things specific to them, like their name or age.
- Where they are. We sell products to customers all over the globe. Each customer lives in a different area and has - for instance - a different address.
- Their interests or motivations. Each customer may want a product - or products - unique to them.
- What they have. A user-selected payment method is one such example.
- How they use our services. This may involve personal traits, risk-averseness, and even technical competency (using our website). This all plays into the sequence of activities they undertake, and even the length of time between each user action.’
‘You’re suggesting that they behave differently depending upon their personalities or what they purchase? Why is that relevant?’ asks Daphne.
Understanding every nuance of every customer who could enter your system during this period (who they are, where they are, their motivations, their viewing habits and behaviour, their payment selection) is extremely challenging and probably not something you want to delve into down to the n-th degree (else you’ll spend all your time analysing their habits and not testing anything). And once you understand your users, you’ve then got to figure out how to reconstruct them and mimic their actions in a load test!
‘Yes, they do. It may become relevant as we consider the timings between each user interaction. It’s too difficult to assess each user session individually, so we’ll need to make some assumptions about how quickly - or slowly - we simulate each successive user interaction.’
‘Wow, I never thought of that! It's a lot more involved than I thought.’
Joe analyses the metrics, discusses the options with the team, and they agree to the following assumptions:
- Limit the number of unique customer details to 1000. There will still be 100,000 customers, but there’s only 1000 distinct customers, repeated throughout the test.
- Customer requests can originate from ten different countries, and from five different cities per country. This will provide sufficiently unique addresses.
- The number of items in the cart will vary between 1 and 5, and will include a catalog navigation per interaction.
- The “interaction time” will be defaulted for all customers to two minutes. This is mainly to remove complexity; once Joe has confidence in the test results, he’ll refine the test to support more dynamic interaction times.
POOR ASSUMPTIONS
These assumptions are important. Misdiagnosis may affect the accuracy of the testing, yet you can’t easily simulate such voluminous and varied user demand (which would be our ideal state). Using averages is the most obvious way to mirror some aspects, even if it's not 100% reflective of real user journeys.
THE RESULTS ARE IN
Joe runs the load test and views the outcome. Unfortunately, the news is bad. The system managed 75,000 concurrent users - with sub two seconds response times - before things worsened and Joe was forced to stop the test. While this outcome is far from ideal, it's better to learn this now, whilst something can still be done, than later, when it’s in use.
We now know that the solution doesn’t meet the required SLA, and must be rectified. On a positive note, the team now has good metrics and have identified a likely bottleneck. The team makes those adjustments, undertakes some localised load testing on that component (with Joe’s help), and then releases it again to rerun the system load test. The second load test is successful, indicating that they (just) made it, with 105,000 concurrent users.
SUMMARY
The example I used was slightly contrived, but I wanted to show both what a load test does, and the value it can bring. It can bring confidence if it succeeds, or Fast(er) Feedback if it doesn’t.
One thing to note is that load testing shouldn’t be taken lightly. There’s little point in testing that a solution handles a certain capacity if the test is seriously flawed, or the system under test isn’t correctly configured to mirror the production environment. Data volume is another important consideration. You can have a sound test, with a correctly configured environment, but still fail to accurately test if there’s no data currently in the database, whilst the production environment contains millions of records - it’s not comparable.
Also, be aware that load testing is not a one-off activity, yet neither (in most cases) need it be run continuously. In a sense, load testing also offers a form of non-functional regression testing, testing the system remains compliant with its SLA after the introduction of a new feature.
Of course, you could argue that the architecture and design should have considered this from the start. But designing a system for a specific load and proving it is capable are different things. Fast Feedback can help here, by load testing (and other non-functional tests) at lower grains throughout the development lifecycle, then progressing up to the system level when appropriate, we gain incremental confidence in our overall solution.
FURTHER CONSIDERATIONS
STRESS TESTING
Suggested read: Case Study A
Stress Testing is a form of performance testing aimed at finding a system’s breaking point.
STRESS TESTING V LOAD TESTING
Stress Testing differs from Load Testing in that it tests extreme load, to the point of breaking a system (or making it unusable), rather than stopping at the maximum number of expected concurrent users the product was built for.
Why do this? Isn’t load testing sufficient? The information gained by stress testing can be very useful, for example in supporting Agility and Stakeholder Confidence, by proving that a system can:
- Handle additional capacity should an unexpected event occur.
There are often cases where the expected> use of a system differs from its actual use.
The problem is commonly found in the following sectors:
- The retail sector, such as during Black Friday deals, or the celebrity-factor (when a high-status celebrity endorses a product).
- News websites, during a significant news event (e.g. celebrity wedding or death, or historic political event).
- Ticketing systems, when the demand for tickets outstrips the ability to supply that demand (e.g. legendary rock band reforms for a world tour). [1]
- Streaming Pay-Per-View (PPV) events that couldn’t meet consumer demand.
- Support an increase in business growth (scale up) by safely bringing in more custom.
In either case we may breach the capacity the system was intended for, so we should understand its capabilities.
Let’s expand the Mass Synergy scenario described in the Load Testing section. In that scenario, we discovered that the customer purchase flow needed tweaking to meet the SLA. Let’s assume that that work is now complete and Joe is happy with the results (the system accepts 105,000 concurrent users, delivering sub 2s response times for 99% of users). The team’s been busy further improving performance, and although they don’t yet have exact figures, they’re confident they’ve made significant gains. We're not done yet though.
Daphne visits Joe in the office. She’s been in talks with some new retail clients about on-boarding them onto Mass Synergy’s SAAS product. It's great news, providing another valuable source of income. However, she did identify one potential issue around on-boarding those client’s customer bases. Client A needs the support for 20,000 concurrent customers online at the same time. She’s also in talks with two other clients, bringing in a further 60,000 concurrent users. ‘Can our systems cope with 180,000 concurrent users?’ she asks Joe. ‘I’d like to sign a contract with them this week. When can I say yes?’
Joe feels pressured to give an immediate answer. But he has no evidence one way or the other. The proverbial goalposts have moved, and the SLA of 100,000 concurrent users is no longer the target. The goal is to understand the system’s maximum capabilities. He gathers some pertinent information about the prospective clients, reaffirms the new target, and then gets to work, promising Daphne he’ll have the results by Thursday.
Joe uses the original load test script as a foundation, extending it for the new load expectation. Rather than stopping at 100,000 concurrent users though (which he knows works), this test will ramp up concurrent user sessions until the system fails. Joe continues to use the response time to indicate the system's health. The tests will ramp up users every thirty minutes, like so.
| Duration (mins) | Concurrent Users | Response Time (99%) |
|---|---|---|
| 30 | 80,000 | <2s |
| 60 | 100,000 | <2s |
| 90 | 150,000 | ? |
| 120 | 200,000 | ? |
| 150 | 300,000 | ? |
| 180 | 400,000 | ? |
Note that I’ve added question marks for the remainder of the test.
THE RESULTS ARE IN
Of course we might not reach the heady heights of 400,000 concurrent users, but as they say, go big or go home! Joe runs the test and is pleasantly surprised with the results.
| Duration (mins) | Concurrent Users | State | Response Time (99%) |
|---|---|---|---|
| 30 | 80,000 | Stable | <2s |
| 60 | 100,000 | Stable | <2s |
| 90 | 150,000 | Stable | <2s |
| 120 | 200,000 | Stable | <2s |
| 125 | 211,500 | Stable | <2s |
| 126 | 212,000 | Stable, but unacceptable response times. | <4s |
| 150 | 300,000 | System Fails | |
| 180 | 400,000 | Not Attempted |
The system remains stable up until around 212,000 concurrent users, where the response times quickly become unacceptable. The system fails at around ~300,000 concurrent users, at which point Joe stops the test.
WHEN?
Because this test can be quite intrusive, destructive, and expensive (to a test environment) you might choose not to continually run this test; however, it should be undertaken regularly enough to allow a business to make sound decisions about their direction.
Daphne is ecstatic. Not only can she agree contracts with three new clients, but she also knows how many additional clients can be on-boarded without impediment. This is an excellent metric for a business, providing them the Agility to decide how - or when - they wish to grow. Mass Synergy may decide to do nothing for a while longer, yet still on-board some new clients, or they may further improve the product and target larger clients, or more of them.
FURTHER CONSIDERATIONS
- Case Study A
- [1] - Example of a Ticketing system issue. https://www.bbc.co.uk/news/entertainment-arts-34571070
- Load Testing
- SLAs
SPIKE TESTING
Suggested read: Case Study A
Spike Testing is a form of Stress Testing, specialising in extreme scale over a very short timeframe. Whilst it is very similar to stress testing, it’s not the same - stress testing aims to find a system’s breaking point based upon the number of concurrent users a system can handle; Spike Testing focuses on testing how well a system responds to scaling needs over a much shorter time frame.
I suspect there’s still some room for interpretation, so let’s try another tack. Many software systems have the concept of a warm-up period (even in a Serverless world there’s a concept of pre-provisioning functions to avoid cold starts). Examples include spinning up new instances in the Cloud using a machine image (I’ve seen this take 15 mins), or loading a cache into memory before that service can be used (I’ve also seen this take 15 mins), or starting up an application server (several minutes). Whilst this warm-up occurs, the software within these services remains unavailable. See below.
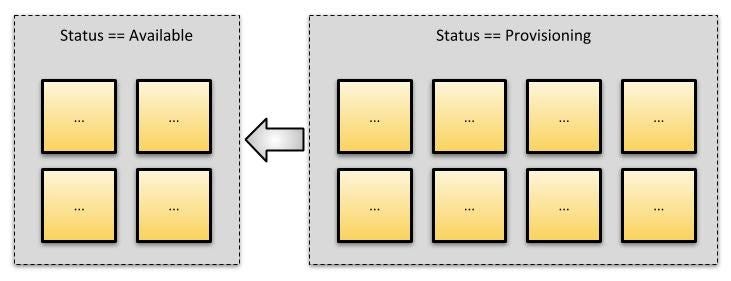
In this case there are four instances currently available, whilst another eight are in the provisioning state (i.e. initialising, but not available). This state may occur when a demand for more services has been recognised (either by the system, or by its operator). At some stage there will be twelve (4 + 8) instances ready to serve requests, but not yet! If the time taken to load these new instances is greater than it is for a large number of users to consume, at its current state, then those users may swamp those four instances before the cavalry arrives.
COMMON SCENARIOS
Spikes are common in time-sensitive, or big event, services. If you’re offering something popular, and it’s time-sensitive, then you probably want to do spike testing.
Let's return now to Mass Synergy. It's the run up to Christmas. The business lands the latest new craze (a toy that every kid wants, but is out of stock everywhere else). It’s marketed everywhere and goes on sale at 9am on Monday. The team are confident they can handle the projected load (maximum expectation of 150,000 concurrent users), having proved it can handle ~200k concurrent users as part of their Stress Test. Everyone goes home for the weekend, comfortable that Monday will go well.
9am Monday morning arrives. 110,000 customers log into the system in the first five minutes, search for the toy, and begin the purchase flow. Within 2 minutes, the system has crashed; there’s ~110,000 angry customers, and lots of bad press. So what went wrong?
The system could certainly handle these numbers, being stress tested up to 211,500 concurrent users (Stress Testing). But this strategy made certain Assumptions, specifically around the scaling strategy. Like many systems, Mass Synergy contains a number of components requiring a warm-up period. The Catalog component - for instance - uses a large cache for product storage which takes around 15 minutes to fully populate. There's also a slightly cumbersome dependency that checks every 5 minutes for additional capacity needs, before adding five new hosts, then waiting another five minutes to check again.
The problem here isn't one of capability but one of time. The system needs time to reach capacity demands. Time to determine if it needs further resources, and time for those resources to become useful (provisioning to available). Unfortunately, the spike in demand has already flooded the system (Flooding the System), before those additional resources can be utilised, and there’s now lots of angry customers denigrating Mass Synergy’s good name on social media.
WORKING TOGETHER
This problem isn’t solely a technical one. The content acquisition and marketing teams also have an important part to play, ensuring the numbers that they forecast are accurate and sufficiently detailed for the technology team to proactively provision systems for such use cases. In this case the team didn’t have sufficient detail to see a potential problem.
GO SERVERLESS?
You may think that Serverless is the solution here, allowing it to scale without limitation. But that too has concerns. Allowing a system to scale unimpeded is a bit like the Magic Porridge Pot [1], with your credit card at the receiving end (e.g. DoW attacks). These decisions require serious thought - “more haste less speed” - before deciding upon the right approach.
SUMMARY
If a business fails to anticipate a major spike in traffic, and pre-provision sufficient resources, then they must resort to dynamic provisioning. This is not an issue assuming:
- Those new resources can be spun up quickly.
- The load on the current services doesn't overwhelm them whilst additional instances are spun up.
The alternative - where the load outstrips available capacity - is not a desirable position to be in, and may lead to reputational harm. Spike Testing tests how capable a system is to meet a significant increase in demand over a very short timeframe. It can be used to shape a provisioning strategy.
FURTHER CONSIDERATIONS
- [1] - The Magic Porridge Pot - https://en.m.wikipedia.org/wiki/Sweet_Porridge
- Case Study A
- Stress Testing
- Assumptions
- Serverless
- Cloud
- Flooding the System
ENDURANCE (SOAK) TESTING
Suggested read: Case Study A
A system tested with a peak load for a short duration may not exhibit (or be sufficiently pressured to create) issues that may be seen over a longer duration. Sustained pressure can sometimes cause unexpected issues, such as system memory issues, that eventually lead to deeper system problems. Catching them during testing can increase system Resilience, and protect important aspects of your business, like Reputation.
Endurance Testing (also known as soak testing) simulates a (peak) load, for an extended period, to identify potential weaknesses affecting system stability, and visible behaviour. It is very similar to Load Testing, albeit it's undertaken for much longer, and may uncover different problems.
LET'S TALK GARBAGE
Consider how software garbage collectors (an integral part of many modern programming platforms) work. They are automated jobs that typically wait for an opportune time to undertake a system “clean-up”, thus reclaiming unused memory and sending it back to an available memory pool.
However, a system under continual pressure may not get sufficient opportunity to undertake this cleansing. Under these circumstances, the finite pool of available memory reduces - until nothing remains - at which point the system may behave unpredictably, or fail. And, as we know with cascading failures, a failure in a single area may bring an entire system crashing down.
The table below shows a possible scenario comparing load and endurance testing.
| Hour | Load Test | Soak Test |
| 1h | Peak Load | Peak Load |
| 3h | Test Finishes Successfully | Peak Load |
| 10h | N/A | Peak Load |
| 40 hrs | N/A | Memory issues begin - last successful garbage collection was six hours ago |
| 48 hrs | N/A | System Failure |
In this case we stopped the load test (successfully) after a few hours, having done its job. However, we left the endurance test running for several days, measuring system and business metrics regularly. If we identify a potential issue, we can investigate, otherwise we have increased our confidence (Stakeholder Confidence) in the reliability of our system.
FURTHER CONSIDERATIONS
PERFORMANCE TESTING
Ok, so you know whether your system functions as you would expect, but how do you know if it operates well under pressure?
Performance Testing is a catch-all term for a variety of non-functional tests, including:
Fundamentally, they all test how a system performs (behaves), with (sometimes varying) load, or large data volumes, over a period of time. The results either indicate the system is in a good state, or that there's an issue that needs further investigation.
TERMINOLOGY
Note that there are some discrepancies in the naming conventions used around the industry. Some use the terms performance and load testing interchangeably, others might use the term load testing when they actually mean a more specific form of load testing (e.g. spike).
FURTHER CONSIDERATIONS
CYBERCRIME [SYSTEMS]
Cybercrime is a growing industry. Whilst the 1980s saw a burgeoning internet connecting thousands of devices, today there are trillions, and it’s still growing.
The influence of Ravenous Consumption has moved technology forward at a great pace (and vice-versa, as technology has driven increased consumption), improving our lives in many ways. Yet it also comes at a cost. The vast increase in devices, data access points, orientation around data-driven metrics and decision-making, and the peddling of a convenience-first and always-on attitude (where we seem increasingly comfortable to publish more and more data about ourselves) undoubtedly increases the risk of us being affected by cyber-related crimes (including data theft, impersonation, fraud), something far less likely two decades ago. This isn’t a problem that’s going away judging by the pace at which new devices (e.g. Internet-of-Things devices) are created, and businesses (both new and existing) enable online services. The pace of evolution is both exciting and, at times, frightening.
NEON SIGNS
To meet this growing consumer and business demand, systems have shifted from closed and insular (e.g. 1980s) to more open and widely available (thus the increase in security controls in an attempt to offset it).
Whilst this offers the consumer greater options, flexibility, and convenience, and many more revenue possibilities to businesses, it's also a big neon sign ($$$) which creatures of the night are drawn to.
Read the technology section of any mainstream news-site and you’ll likely stumble upon very recent articles describing a major security breach. Not only are these breaches occurring with frightening rapidity, but they are often far broader and have a greater impact than anything seen before, sometimes affecting millions of customers, and costing millions (or sometimes billions) of dollars. Possibly, an outcome of centralising services (Growth through Acquisition, and Economies of Scale) as they’re seen as higher-value targets?
For the individual, this can - for instance - cause anxiety, depression, and financial loss. For a business, this can create branding and reputational problems, (serious) financial penalties, or even regulator intervention. None of these prospects are appealing.
Yet the benefits far outweigh the risks (otherwise, why do it?). Businesses with no online presence are often at a serious disadvantage over their competitors who have. Consumers who don’t use online services may be missing out in greater choice (globally), and in cheaper deals they could get from shopping around.
So, what can be done to help? There’s a number of options, including risk profiling, education, introducing security controls, and Pen-Testing (I discuss this next).
FURTHER CONSIDERATIONS
PENETRATION (“PEN”) TESTING
Suggested read: Cybercrime
Everything in our world has both strengths and weaknesses, including software.
If software is built by humans, and humans have flaws (e.g. Rational Ignorance), then this suggests that the software those humans build will also contain flaws. If this is true, and if other humans (the users) use this flawed system - or become associated with it in some way - they then may be affected by said flaw, particularly if leveraged for nefarious purposes.
ASSUMPTIONS
We readily make Assumptions about how software will be used, where it will be deployed, how (many) people will access it, who will access it, why they access it, and when it will be accessed. These assumptions aren’t always grounded in reality. We can’t assume that every user is legitimate and has good intentions, or that they will use the system in the way it was intended.
Indeed, the term “hacking” describes the action of changing something, to behave differently to what it was intended for. Wikipedia defines a hacker as: “A computer hacker is a computer expert who uses their technical knowledge to achieve a goal or overcome an obstacle, within a computerized system by non-standard means.” [1]. A “hacker” may or may not be nefarious.
WEB-SCALE
As I’ve already described (Cybercrime), modern web-scale solutions are able (and meant) to be accessed by many (the internet is, after all, the most scalable information sharing platform we have). This inherent accessibility suggests the need for “controls”, to ensure that only legitimate users gain access to a service; however, we sometimes find these controls insufficient, redundant, antiquated, or incorrectly implemented.
To protect both its customers and itself (Reputation), a business should test the software it builds (or uses from others), both for its strengths, and its weaknesses; the purpose of a Penetration Test (Pen-Test). A Pen-tester stages an attack on a system(s) to assess its strengths and weaknesses, gathering information the business can use to decide whether (and how) to invest effort in shoring up weaknesses. The output is typically a pen-test report (see later).
At an abstract level, we might ask these types of questions with a pen-test:
- Is it possible for an external attacker to gain access to our thirty year old legacy invoicing system written in COBOL?
- Which parts of our system are vulnerable to external attack?
- Which parts of our system are critical to our success and contain weaknesses?
- Can User A access User B’s information?
STYLES
Pen-Testing may be undertaken either internally or externally (e.g. by an independent third-party). There are three styles (or types) of pen-testing:
- Black Box. In this case very little is known about the system before-hand, so it must all be discovered. This approach most closely correlates with external attacks, where the attacker starts with very little information and builds up a detailed picture of the target system over time.
- Grey Box. Whilst some information is already known about the target system, the attacker doesn’t necessarily have detailed information about its internals.
- White Box. The system - and much of its internals - is already well understood. This approach most closely correlates with an inside attack (e.g. a disgruntled member of staff), and the pen-tester has likely worked with the system for some time (such as an existing employee). It typically takes the least amount of time to undertake (as much of the reconnaissance and scanning phases can be minimised).
THE PHASES
The style of pen-test (e.g. white-box) undertaken may affect the duration of some phases, but it typically contains the following phases:
- Reconnaissance. Reconnoitre the target system to gain information needed for the next phases.
- Scanning. Now you have information about the system, you can scan it to identify potential vulnerabilities. This may involve a degree of interpretation.
- Exploiting. Exploit identified vulnerabilities to gain access to the system, and (potentially) use privilege escalation to get root access.
- Maintaining control. Repeating the intricacies of an entire exploit every time you want to gain access is onerous and unnecessary. In this phase you may install something (e.g. a back-door) to maintain control and return whenever you like, enabling an attack to be sustained over a longer duration.
- Report. The pen-tester reports back to the customer the pen-test results.
Note that other sources may use different names for these phases but they all have a similar intent.
OUTPUT
The result of a pen-test is recorded in a report, and typically contains the following information:
- Executive Summary. Summarises what was done, what was found, and possible next steps.
- Detailed findings. Detailed information on any vulnerabilities (or risks) that were found. This information can be used by the development team to recreate/resolve the issues.
- Recommendations. Any recommendations (including possible mitigations) from the pen-tester based upon the findings.
CASE STUDY
Let's return to Mass Synergy, this time with an eye on discovering weaknesses. We could invest time in the Fulfilment component, but that’s mainly an internal service, and not really critical to their success. Instead, let’s focus on the customer purchase flow. Let’s assume that Joe is going to undertake a pen-test on the system after agreeing it with the team. There’s a number of areas he could look at, but with his inside system knowledge (white-box testing) he’s opted to investigate how cart items are stored.
It interests Joe in the follow ways:
- There is no limit placed on the number of cart items a cart can have.
- There is no mechanism to prevent the same item being added multiple times; i.e. we’re not using a quantity field.
- It doesn’t require a user to be logged in to add cart items ( Mass Synergy wants to remove obstacles that would hamper purchases). Although this seems to be standard practice in retail sites.
This flaw - if it is one - is twofold, both in the implementation, and in a missing requirement(s). Joe believes he can leverage this potential vulnerability to create a never-ending (infinity) cart (“Cook little pot, cook” - Magic Porridge Pot [2]). It’s a very basic attack. In the test environment, Joe creates a few hundred carts, and fills each of them with thousands of the same item. He thinks that by causing many long-running transactions to run concurrently, he can simulate a Denial-of-Service (DoS) attack.
UNDERLYING EFFECT
Each cart change (add) not only adds a new entry into the datastore for that item, but also causes a refresh of the entire cart and all of its items. So adding a single item to a cart that already contains 1000 items actually causes a lookup of 1001 items (the 1000 existing + 1 new item).
Joe executes the pen-test. Sure enough, he finds that each cart request takes increasingly long (increased latency) and system resources fill up. He also sees legitimate traffic being rejected by the system. Downstream services (catalog) also take a beating, creating a performance bottleneck for legitimate calls into the catalog.
This simple attack terminated all three cart instances on the test environment. Whilst the good news is that the system is declarative and autonomic (self-healing), the bad news is that (a) legitimate users were affected during this period, and (b) there’s nothing in place to stop the attacker repeating this attack again, once the system recovers.
DENIAL OF WALLET
Whilst in this case this attack created a Denial-of-Service (DoS) on Mass Synergy’s services, it could also have created a Denial-of-Wallet (DoW). Let’s say that Mass Synergy’s solution is deployed on the Cloud, and uses Serverless technologies with a high scalability threshold.
Serverless is typically charged by processing time (and memory) - the longer it takes to process a transaction, the more it costs. It’s therefore advisable to minimise how much time is spent processing. However, our attacker has just spawned lots of (relatively) long-running processes that will be repeated over and over, and now there’s a massive bill to contend with.
TESTING D.O.S ON THE CLOUD
Some cloud vendors don’t permit the pen-testing simulation of a DoS attack - at least without their pre-agreement. You might think this sounds unfair, but they’re quite within their rights to do so - it's both the cloud vendor’s infrastructure that you’re using, not yours, and they’ve also got other tenants that could be affected by your “noise” to consider too.
Joe writes up a report and then discusses the results with the team. They opt to:
- Limit the number of items to twenty - more than enough for most customers.
- Add a quantity field to allow the same item to be purchased in bulk rather than duplicating items in the cart.
- Investigate tools (e.g. Intrusion Detection System - IDS, Web Application Firewall - WAF) to identify and mitigate DoS attacks (nearer to the Gateway) prior to entering the system.
SUMMARY
Whilst pen-testing provides a way to understand the strengths and weaknesses of a system (and action them), it can also be used to build up Stakeholder Confidence. It's easier to have confidence in a system that has been thoroughly pen-tested and given the green light than one that hasn’t. However, be aware that the inability to find a weakness doesn’t preclude its existence. As the phrase goes:
“Software testing proves the existence of bugs not their absence” - Anonymous.
Pen-testing then, provides a tool in our arsenal, both to protect customers, and also to help protect business Reputation. Of course, there are many other facets to a pen-test. Not only can software applications contain flaws, but so too can hardware, routers, operating systems, databases etc. There’s also many attack vectors for each (see OWASP for common forms of application attacks [3]).
Pen-Testing can be a very specialised skill (the toolset is vast, and the problems can vary greatly, from high-level down to the minutiae). I certainly couldn’t do it. It’s not necessarily a skill your typical developer or tester has either, or has much training in. This has led to DevOps, and the DevOpsSec movements, where we embrace security earlier on in the life cycle (Shift-Left) to increase quality and feedback (Learn Fast).
Finally, before undertaking a pen-test, first decide who the results are for. Are they for internal consumption, and could be undertaken internally, or something a client requires as part of a due-diligence, so requires an independent third-party?
FURTHER CONSIDERATIONS
- [1] - What is a Hacker?
- [2] - Magic Porridge Pot
- [3] - OWASP
- Ravenous Consumption
- Shift-Left
- Learn Fast
END-TO-END TESTING
Suggested read: Case Study A
As the name suggests, End-to-End (E2E) Testing tests the entirety of a solution, from one end of the spectrum (UI) to the other (back-end). It's typically used to test user journeys - the journey(s) a user takes through a software product to achieve their goal. As E2E testing tests the entire solution, it uses the broadest level of functional testing (as opposed to non-functional testing, such as Performance Testing). In addition, it most closely represents the actions of the (typical) end user, so is the truest test of what they will experience. E2E testing is - and generally should be - automated.
There are a few well-established processes/frameworks for testing E2E journeys:
- Cucumber/Gherkin (within BDD). BDD is a process that also supports the capturing of scenarios in a highly readable (given-when-then) natural language, using domain-specific (business context) concepts. It's a good medium to describe E2E user journeys, that - unlike programming languages - is understood by a diverse range of stakeholders. However, it still requires translation (or interpretation, if you prefer) effort to turn the specifications (e.g. Gherkin) into executable automated test code.
- Selenium. An established E2E testing tool typically used to interact with a UI in different modes.
- The Cypress framework. This web test automation framework seems to be gaining traction. Cypress executes tests within the browser.
The team at Mass Synergy want to ensure the quality of their entire solution; from the user interface (UI), through the Gateway (and WAF), down into the Microservices, and finally into their datastores. I’ve included the high-level architecture below, and indicate what’s under test (all of it).

Whilst some of the finer-grained functional testing (Unit Testing, Acceptance Testing, Integration Testing) the team has already undertaken has provided Stakeholder Confidence and Fast Feedback, they still want to ensure the entire solution functions as intended. Their user journeys include:
- Customer registration.
- Catalog actions (search, view).
- Cart operations.
- Discounting.
- Fulfilment requests (using third-party’s delivery service test system).
- Notifications (e.g. emails and text messages).
- Customer returns and complaints.
After some investigation, the team opt to write the E2E tests using the Cypress framework because:
- It creates a consistency and Uniformity in the technologies used to write both the UI (written in JavaScript, using the React framework) and the E2E tests (also written in JavaScript). Additionally, this also creates a Lower Representational Gap (LRG) - for the technical staff at least - and reduces complexity.
- The tests are embedded in the application repository alongside the UI source code, making them easy to find and change.
- Cypress isn’t tied to a specific UI implementation framework (e.g. Angular, React), only the HTML that is rendered. This Flexibility enables the team to switch UI technologies at a future date, yet still retain all of their E2E tests (and use them as a Safety Net).
- It supports a TDD style development approach, where E2E tests are introduced before/alongside the UI changes. This also enables Fast Feedback.
- The tests can be executed as part of a Deployment Pipeline, run as part of any major change to the application.
SUBCUTANEOUS != E2E
Is E2E testing the same as Subcutaneous Testing? No, not quite. Whilst subcutaneous testing operates at a higher level than acceptance or integration testing, it doesn’t typically involve the user interface (UI). So, whilst Subcutaneous Testing probably tests much of the system, it may not test it all - for instance if some business logic resides in the UI.
SUMMARY
One concern over E2E tests is ownership and accountability. In a world of finer grained responsibilities (e.g. Microservices), who has ownership of the overall E2E tests? Is it a centralised testing team, thus creating silos between the Cross-Functional Teams building the software (and finer-grained tests), and a single team managing these E2E tests? Silos often create business scaling, ownership, and communication challenges.
Secondly, where do these E2E tests reside? It makes little sense to embed them with each Microservice - since they operate at a much higher level - so they probably need their own source control repository. And how does one evolve a microservice and the E2E tests associated with that change? Can that microservice developer (in a cross-functional team) modify the E2E tests in conjunction with that microservice, or must they coordinate with another centralised team (also contending with the demands from other teams)?
OWNERSHIP CHALLENGES
This ownership problem is also true of other higher-level testing - such as Performance Testing at the system level - or some aspects of UI testing. Who owns and evolves it?
The team at Mass Synergy opted to embed the E2E tests alongside the UI code. Thus, any change affecting the UI is uncovered by those E2E tests. Being a small team, they also agreed to preempt any back-end (microservice) change with a short conversation (Three Amigos) with the UI team, where they would agree how (and who) that E2E test would be implemented.
FURTHER CONSIDERATIONS
- Cypress - https://www.cypress.io
- Case Study A
- BDD
- Performance Testing
- Microservices
- Cross-Functional Teams
- Fast Feedback
- Safety Net
UNIT TESTING
Suggested read: Case Study A
Unit Testing is the lowest level of testing we're likely to perform in the software engineering lifecycle. It focuses on testing the small-grained constituent “units”, which are typically:
- A method, or function.
- A class, containing methods or functions.
Unit tests are typically written and run by developers during the course of development (or run directly after, as part of a Continuous Integration/Delivery pipeline). They test the unit's navigable paths, and verify that the unit produces the desired outcome, under various different conditions. It's common to create unit tests in parallel, or immediately prior (in the case of TDD), to the feature’s code.
Let’s return to Mass Synergy. The business has one key desire - to enable the customer to purchase. As such, they’re willing to offer customers in that purchase flow certain incentives (in the form of discounts), should they qualify. Obtaining the right business outcome is very important to them. Unsatisfactory outcomes include handing out too many discounts (affecting the business’ bottom-line), or failing to offer discounts to customers who should receive them (affecting the business’ reputation).
With this in mind, consider the following code, used to derive a discount amount to apply to items in a virtual shopping cart. It's called by a higher-grained service that is exposed to users through a REST endpoint. Please note that you don’t necessarily need to follow all of this code; the key takeaway is that it produces some testable outcome, based upon an external stimulus. Lines 2, 4, and 8 (bolded) represent decisions (navigable paths) that may affect the visible outcome seen by a user.
1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. |
BigDecimal deriveDiscountTotal(DiscountEntitlement discount, BigDecimal cartTotal) {
BigDecimal discountAmount = BigDecimal.ZERO;
if(discount.isPercentDiscount()) {
discountAmount = new BigDecimal(discount.getAmount().doubleValue() * 100 /
cartTotal.doubleValue());
}
else if(discount.isMonetaryDiscount()) {
discountAmount = cartTotal.subtract(discount.getAmount());
}
return discountAmount.setScale(cartTotal.scale(), RoundingMode.HALF_EVEN);
}
|
The outcome of this method may be:
- No discount to apply (zero amount); e.g. the cart is empty, or the customer is not due a discount.
- A percent discount is applicable; e.g. 15% off (lines 4, 5, and 6).
- A monetary discount is applicable; e.g. $10 off (lines 8 and 9).
PART OF THE WHOLE
Bear in mind that this method is only a small part of the overall cart service codebase. For example, this method is called by the CartsService.addItem() method, which in turn, also contains logic to (a) check if the item is in the catalog, and (b) whether the cart is free. All of this logic should also be unit tested.
Looks good doesn’t it? But we shouldn’t necessarily trust the correctness of this implementation; we should prove its accuracy. To do so, we should (unit) test it. Typically, this would involve writing a reasonably large number of tests, so I’ll just offer a taster of some of them.
Again, don’t be alarmed by the code. The key takeaway is that we're passing different configurations into the CartsService.deriveDiscountTotal() method, and then asserting that the outcome is correct.
@Test
public void testDiscounts() {
List discountValues = new ArrayList(Arrays.asList(
new DiscountValues("PERCENTAGE", 10d, 100d, 10d),
new DiscountValues("PERCENTAGE", 50d, 100d, 50d),
new DiscountValues("PERCENTAGE", 75d, 100d, 75d),
new DiscountValues("PERCENTAGE", 99d, 100d, 99d),
new DiscountValues("PERCENTAGE", 110d, 100d, 110d),
new DiscountValues("MONETARY", 10d, 100d, 90.00),
new DiscountValues("MONETARY", 9.45d, 100d, 90.55d),
new DiscountValues("MONETARY", 50d, 100d, 50d),
new DiscountValues("MONETARY", 75d, 100d, 25d),
new DiscountValues("MONETARY", 100d, 100d, 0d),
new DiscountValues("Boz", 100d, 50d, 0d),
new DiscountValues("", 100d, 50d, 0d)
));
for (DiscountValues dv : discountValues) {
testDiscount(dv);
}
}
public void testDiscount(DiscountValues dv) {
DiscountEntitlement discount = new DiscountEntitlement(dv.type, dv.amount);
BigDecimal discountTotal = cartsService.deriveDiscountTotal(discount, dv.total);
assertEquals(dv.expected, discountTotal);
} At a basic level, we’re building up a list of test data (named discountValues), then iterating over each and testing it produces the correct output. If any unit test(s) fails, it is flagged, and either resolved as part of the developer lifecycle (ideally), or within the carts service pipeline (Deployment Pipeline).
A SUITE OF UNIT TESTS
Note that a unit test only tests a small area of the overall codebase (in our case, a specific scenario in the deriveDiscountTotal method). In this context, you’d be forgiven for questioning its value; however, harnessing a suite of unit tests can provide a good amount of (system) coverage.
Unit tests provide Fast Feedback, so they should be quick to execute, and typically make very few assumptions (Assumptions) about the overarching system (e.g. no database integration). However, they are also critical for those stakeholders nearest the proverbial coal-face (Stakeholder Confidence), being a form of Safety Net, and enabling them to innovate with some impunity.
Whilst unit tests are very useful, they have some limitations:
- Brittle tests (ones that break easily, when only a small section of the implementation being tested changes) can hamper larger refactorings (Refactoring), and may be one reason to prefer many modest (incremental) refactorings to a global one. It's easier said than done of course, but try to avoid coupling tests to how something works (e.g. the sequence of calls), and look to test the final outcome. This approach allows the tests to track well against varying implementations, without receiving constant “noise”.
- Granularity. Unit tests don’t test how an overarching system behaves in reality, where network errors, poor latency, bad data, intermediate layers, software frameworks/platforms, and unconventional workflows can create instability in an otherwise stable system.
UNIT TESTING APIS
It’s worth noting that we may also unit test at a slightly higher grain of (user) usefulness - such as API endpoints. Below is an example of testing the GET carts REST API, when the cart has zero items.
1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. |
@Test
public void testGetSuccessKnownCartZeroItems() throws Exception {
Cart cart = new Cart();
cart.setId(CART_ID);
Mockito.when(cartsService.get(CART_ID)).thenReturn(cart);
RequestBuilder requestBuilder = MockMvcRequestBuilders.get("/v1/carts/{id}", CART_ID)
.accept(MediaType.APPLICATION_JSON)
.contentType(MediaType.APPLICATION_JSON);
MvcResult result = mockMvc.perform(requestBuilder).andDo(print()).andReturn();
MockHttpServletResponse response = result.getResponse();
assertEquals(HttpStatus.OK.value(), response.getStatus());
JSONObject responseBody = new JSONObject(response.getContentAsString());
assertEquals(CART_ID, responseBody.getString("id"));
assertTrue(0 == responseBody.getJSONArray("items").length());
... further assertions
}
|
By mocking the result of the cartsService.get() on line 6, we can successfully unit test the API endpoint to ensure it responds correctly (0 item array, $0 total amount). Whilst this is indeed a unit test, it is progressing towards an (technology-oriented) Acceptance Test.
FURTHER CONSIDERATIONS
- Case Study A
- Assumptions
- Continuous Delivery
- Fast Feedback
- Refactoring
- Stakeholder Confidence
- Safety Net
- TDD
- Acceptance Testing
INTEGRATION TESTING
Suggested read: Case Study A
Integration Testing tests the integration of part of a system with its external dependencies. These external dependencies could - for instance - be another (internal or external) service or application, a database or file system, an external SAAS solution, queues and streams, or even an email server. Thus, to test an integration, you must also ensure the availability of these external services.
Integration testing proves that a solution can successfully talk to others (outside of its process context), and not be affected by, for instance:
- A Firewall/Network complexity - e.g. port blocking, or a whitelisting setting required to talk to Service X.
- Misconfigurations - e.g. configuring the wrong database hostname or environment variable.
- A versioning conflict - e.g. making an incorrect assumption about the database version used.
- An incorrect API key - e.g. the wrong API key is used to authenticate access to an API.
Integration Testing is - by its nature - more brittle than its Unit Testing counterpart. It functions at both a coarser level, and involves bringing together (often remote) services through unreliable mediums. So why do it? Well, it’s less about protecting functional quality, and more about promoting confidence. Few things are more frustrating in software engineering than spending weeks building a great new software feature, only for it to fail to integrate with its counterparts. By ensuring that all constituent parts of the software under inspection can successfully communicate, we gain confidence that they will all function as desired (much like a well-performing orchestra) in a production environment.
INTENT
Unlike Acceptance Testing, the purpose of Integration Testing isn’t to fully test the functional accuracy of a component, rather it’s there to prove disparate components can successfully communicate with one another.
Let’s briefly return to Mass Synergy. Being security-conscious, the teams decide to introduce a security control onto their APIs. This is a service-to-service level (or B2B) interaction - no end users are in direct communication, so they opt for a shared key model (using HMAC [1]), where each communication path gets its own shared key. See below.
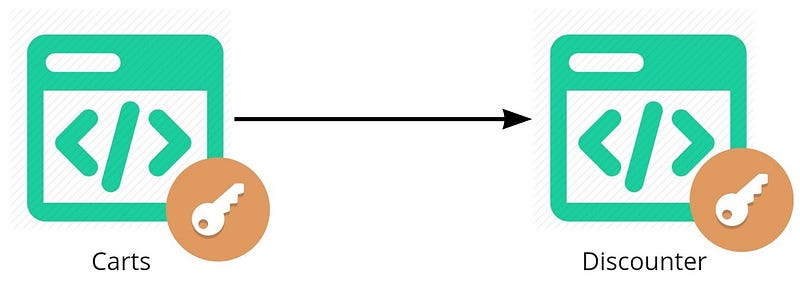
Now, let’s assume that the team managing the Discounter service becomes concerned that their key has been compromised. Erring on the side of caution, they generate new keys (for all environments), and then securely distribute them to the dependent teams (e.g. the Carts team). Unfortunately, the Carts team is so busy with a new feature that they don’t immediately action it and it's soon forgotten about. However, when the Carts team finally releases their new feature they find many of their Acceptance Tests fail. Initially, they think that their new functionality has broken the Carts component, but further diagnosis shows that all communication with the Discounter service fails. See below.
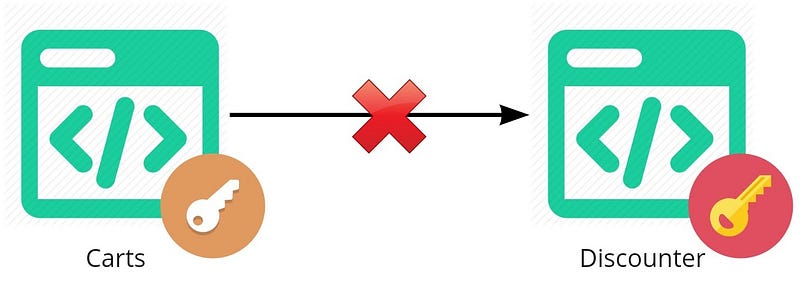
The team now remembers about the new key distribution. They quickly update the Cart component to use the new key, check it works, and then follow it up with a wash-up meeting to discuss process improvements. In this case they agree that a quick, non-intrusive, integration test is the answer, using the Discounter’s secured health check endpoint to test the integration path. Finally, they introduce the new integration test(s) as a new stage in their Deployment Pipeline - prior to any acceptance tests.
DIFFERENT TOOLS FOR DIFFERENT JOBS
Whilst the team could have left their acceptance tests to uncover this problem, it adds confusion. The intent of acceptance tests is (mainly) to test functionality, not the technical integration of communication paths. They’re different tools for different jobs and should be treated as such.
Integration Testing may operate at either the component or application level (see Testing Granularity). Whilst component-level integration testing provides faster feedback than its application-level counterpart, it only proves (confidence) that that component works as expected, not the overarching system.
LOCAL INTEGRATION TESTING
Local (development) integration testing can also be fiddly. Your software must still access those external (to the process) services to prove the integration, but it may be difficult to download and run those external services locally. See Twelve Factor Applications (Dev/Prod Parity section).
FURTHER CONSIDERATIONS
- [1] - HMAC (Hash-based Message Authentication Code) - https://en.wikipedia.org/wiki/HMAC
- Case Study A
- Testing Granularity
- Acceptance Testing
- Twelve Factor Apps
ACCEPTANCE TESTING
Suggested read: Case Study A
How do we know that the software we build meets our customer’s expectations? Well, before we can test it, we must first understand it. This typically occurs during some form of discovery phase, where user stories are created and refined, and an acceptance criteria is captured. We then write Acceptance Tests to prove it functions as expected.
TRACKING FEATURES
Whilst Unit Testing ensures that the low-level “units” function as expected, it’s rare that those units directly correlate to a useful, interactable user feature. Rather, users typically interact with more abstract software concepts (e.g. a component, service, or application), responsible for aggregating many smaller units into something meaningful (see Granularity & Aggregation). Therefore we should ensure we also test our components.
Acceptance tests focus on testing useful functionality, based on an acceptance criteria, typically that a user interacts with. They help to promote confidence in an overall solution. Does it behave as our users expect it to? Does producing an invalid stimulus create an acceptable response? Etc etc.
Let’s return to Mass Synergy’s purchase flow, specifically for deriving a discount when an item is added to a cart. Mass Synergy has numerous discounting rules, determined by the cart and customer combination. The table below shows some example rules.
| Cart | Customer | Result |
| Purchases >= 5 items; Purchase total > $50 |
Resides in the USA | 10% Discount |
| Purchase Window during “Black Friday” | Anyone | 15% Discount |
| Purchase item entitled: “Happy in Seattle” | Anyone | $5 off |
| ... | ... | ... |
SOLVE PROBLEMS AT THE SOURCE
Whilst we should certainly test the Carts.addItem() outcome, we should first check that the downstream Discounter service functions, then progress back up the dependency tree to the coarser-grained Carts component. This approach ensures that we solve problems at the source; it also promotes confidence ahead of the Carts integration.
There’s several ways to tackle discovery and testing. In this case, the team opt to use aspects of BDD by undertaking an Example Mapping session, writing feature specifications for the discounting feature (in Gherkin), then writing the tests (step definitions) using Java/Cucumber. An example Gherkin feature file for the discounting feature is provided below.
Feature: Derive Discount
Derives a discount applicable to the supplied cart and customer combination.
Scenario: David lives in country and meets purchase criteria to receive percent discount
Given David is a Mass Synergy member
And resides in USA
When he places the following order:
| Item | Quantity |
| lordOfSea | 1 |
| danceMania | 1 |
| lostInTheMountains | 1 |
| balancingAct | 1 |
| mrMrMr | 1 |
Then he receives a 10% discount
Scenario: David lives in country but fails to meet purchase criteria,
and receives no discount
Given David is a Mass Synergy member
And resides in USA
When he places the following order:
| Item | Quantity |
| lordOfSea | 1 |
| danceMania | 1 |
Then he receives no discount
# further scenarios...
Of course the entire ruleset is far more detailed (and not covered here). The team then maps the specifications to step functions and write tests, using cucumber to glue things together (not shown here - see the BDD section for more on this).
These tests are written to accept the functionality that’s been delivered. If the tests fail, then the team should address the issues to ensure the functionality is indeed fit for consumption.
FURTHER CONSIDERATIONS
- https://en.wikipedia.org/wiki/Cucumber_(software)
- Suggested read: Case Study A
- Granularity & Aggregation
- Unit Testing
- BDD
SLAS
A SLA (Service Level Agreement) is - as the name suggests - a (contractual) agreement between two parties about the level of service that they can expect. It's important because:
- It clearly states - in unambiguous terms - the responsibilities of each party.
- It helps both parties understand and agree what those service levels are, ensuring there can be no misinterpretation.
- It's measurable and empirical.
- Resolution (if there are any problems) is quicker, and involves less disputes and finger-pointing.
- Failure can have legally enforced penalties (Loss Aversion). Whilst this sounds negative, it’s often the threat of financial penalty that ensures both parties take the service levels seriously.
AGREEING QUALITY METRICS
In many ways a SLA is an explicit agreement about an acceptable level of quality.
An SLA might include the following types of information:
- Availability:
- E.g. A 99.99% uptime, equating to up to ~52 minutes of downtime per year.
- Performance:
- E.g. Serve 1 million requests in an hour,
- At a peak load of 100k concurrent requests,
- With a maximum latency of 2 seconds for the 99th percentile.
- Defect rates, or turnaround time:
- E.g. Any critical defect will be resolved within 6 hours, and any major defect within 16 hours.
- Security patching:
- E.g. An infrastructure vulnerability is patched within 2 days of its identification.
GETTING IT RIGHT
It’s critical to correctly define and agree an SLA before undertaking an important partnership as it can be difficult to modify once contractually ratified.
I've seen several examples where partnerships were drawn up with no (or an inappropriate) SLA, often leading to unsatisfactory outcomes that were entirely avoidable. I’ve also seen cases where a poorly drafted (and considered) SLA needed renegotiation, paving the way for the other party to request further financial incentive (a response akin to: “we've already agreed to the SLA, so it's your problem if you never fully considered the ramifications. If you want changes, it’ll cost you...”).
FURTHER CONSIDERATIONS
SYNCHRONOUS V ASYNCHRONOUS INTERACTIONS
Software systems typically have two modes of communication:
- Synchronous. Each task is linked, and executed in series.
- Asynchronous. Tasks are independent and need not be executed in series.
The key point relates to independence (or lack of). Given two tasks, can they execute independently, or does one task require the other to be completed first?
SYNCHRONOUS COMMUNICATION
Synchronous communication is a well-travelled path, and one that most developers are familiar with. Of the two, it’s both the simplest to build, and to understand.
Synchronous communication executes as a series of interdependent actions, where the subsequent step has a dependence upon something in one of the previous steps; i.e. the steps are connected, or linked together, and cannot be tackled independently. At a systems level, tasks have their start and end points synchronised, creating a chain of calls. See below.
|——[A]——||————[B]————||—[C]—|In this example we have a synchronous flow of three tasks (A -> B -> C). A starts, and runs to completion. B (which is dependent upon A) must wait on A before starting. B now also runs to completion. C is dependent upon B, and so must wait on both A and B to complete before it starts, and then runs to completion. At this point the entire workflow is complete. The key takeaway here is that the caller blocks - awaiting a response and unable to undertake other tasks (ignoring concurrency and threading) - until they receive a response and can move on.
If we revisited our retail scenario (Case Study A), we would find a set of actions that are undertaken synchronously, such as:
- Verify the customer address.
- Taking a payment.
- Fulfilling the order.
In this instance, we chose not to fulfil an order unless the customer address is verified, and there has been a successful payment confirmation.
ASYNCHRONOUS COMMUNICATION
Tasks that use asynchronous communication have no dependence upon the result of a preceding step, therefore creating the potential for entirely independent, parallel, and non-blocking activities to be executed. At a systems level, the start and end points of tasks are not synchronised; they are independent. See the example below.
|——[A]——|
|————[B]————|
|—[C]—|
The key takeaway here is that the caller is non-blocking - it doesn’t wait for a response from A before starting tasks B or C.
Returning to our retail scenario (Case Study A), let’s say that we find the checkout process is overly long for customers, inefficient, and is seen as a barrier to sales. The whole pipeline can sometimes take minutes due to a number of external dependency calls. The original - synchronous - pipeline is show below.
| Check Stock Levels | Verify Customer Address | Check Delivery Schedule | ... | Process Payment | Decrease Stock Levels | Save Order | Fulfil Order |
We realise that the checkout pipeline can actually be split into two. Some aspects can be done whilst the customer is still present, but others can be taken offline, thus providing a better user experience. Further analysis also shows that some steps of the existing pipeline are synchronous when they need not be. For instance, we can process a payment, save the order, and decrease stock levels asynchronously, and only fulfil the order once all of these steps are complete. The new pipeline is shown below.
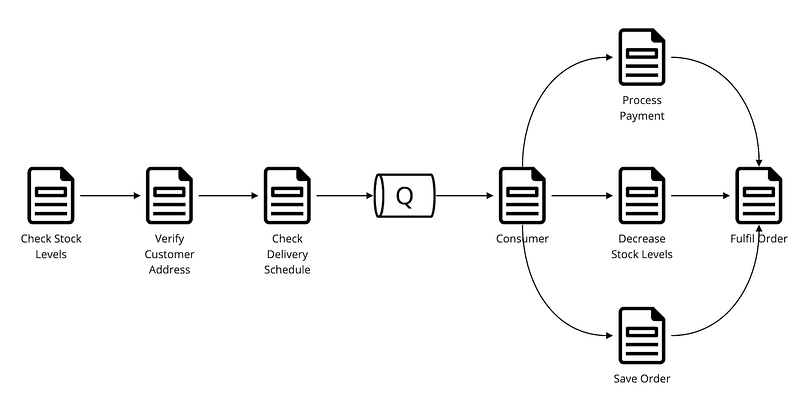
We placed a queue (Bulkhead) between the two checkout stages, creating some asynchronicity, and enhancing the user experience (no long waits for the customer). We then extended the asynchronous nature of the second stage, by undertaking some of that work in parallel. Note that it’s not entirely asynchronous - the Fulfil Order step depends upon the outcome of processing a payment, decreasing stock levels, and saving the order, and shouldn’t occur before them.
From a processing perspective, the second stage of the pipeline moved from a fully synchronous solution, shown below (PP - Process Payment, RS - Reduce Stock, SO - Save Order, FL - Fulfilment)...
|——[PP]——||———[RS]———||—[SO]—||———[FL]———|To one that allows parallel activities, enabling us to fulfil orders sooner; see below.
|——[PP]——|
|———[RS]———|
|—[SO]—|
|———[FL]———|ASYNCHRONOUS DEVELOPMENT
Asynchronous communication can be more complex to develop, debug, and test than its synchronous counterpart, simply because of its temporal, decoupled nature. Splitting is easy, but aggregating split tasks is tougher. Whatever the challenges, asynchronous communication promotes technical qualities such as Resilience, Availability, and Scalability.
FURTHER CONSIDERATIONS
THE CLOUD
There are many books and articles on this subject so I won’t delve too deeply. What I will say though, is that the Cloud is a game-changer. In short, it is a secure, convenient, and accessible platform that offers a wide range of services (including compute, storage, artificial intelligence, authentication, notifications, workflows, and networking) for businesses to build and deliver digital solutions.
Some of its key benefits include:
- OpEx over CapEx (CapEx v OpEx). The cloud enables businesses to use an operational expenditure model rather than a capital expenditure model. A simpler consumption and maintenance model. Businesses can consume services rather than providing them.
- It lowers the gap to Innovation.
- It offers key technical benefits, like massive Scalability, Integrability, Availability and Resilience.
- It can lower operating costs (although not necessarily in every case).
- The support of a global infrastructure.
- Great Flexibility and solution optionality.
- Supports Lift-and-Shift.
OPEX OVER CAPEX
The cloud allows businesses to shift away from a purely capital expenditure (CapEx) model, where they must purchase assets, to an operational expenditure (OpEx) model, where they can rent them. This is important because:
- There is little up-front cost for a business. This is particularly relevant for startups, who don't wish to make a long-term capital investment on (what is, as yet, an) untested solutions.
- From the consumer’s perspective, those assets don’t depreciate in value.
PAY-AS-YOU-GO CONSUMPTION MODEL
The cloud uses a pay-as-you-go consumption model, which is great for most businesses. There is no 24 by 7 cost, typical of the CapEx model - where charges include premises, heating / cooling, electricity, host purchase and maintenance, and software costs - only one based on actual usage.
Fundamentally, this is possible because customers rent the vendor’s cloud services for a unit of time.
LOWERS THE INNOVATION GAP
One of the biggest challenges of the pre-cloud world was the effort required to quickly access (provision hardware and software) services. It was very long-winded, often taking months, and involved a game of chase to get your purchase order signed off. And if that trial was successful, you’ve now got another round of discussions, signatures, and purchase orders (more months) to get a production-ready environment (i.e. one that supports resilience, availability, and scalability). It also created a learning friction - there were fewer options to choose from (as were your integration options), so trials were limited to what you could lay your hands on. All of this was an impediment to TTM and Innovation.
That’s far less true of the cloud. The provisioning of services is typically measured in minutes, not months. If it doesn’t work, the technology isn’t a good fit, you want to pursue other integration patterns, or you want to hedge your bets by investigating alternatives, then the cloud can help. You simply destroy that environment, and spin something else up in minutes. The innovation potential (and business TTM) here is vast. But we’re not quite done. Finally, once you find the right solution, you can prove it’s production-capable (not necessarily production-ready) by reconfiguring the environment and then testing its runtime characteristics (e.g. scalability, availability and resilience).
It's not always described in articles, but there’s also an incredibly important point about the (breathtaking) speed at which cloud vendors are innovating, and their sustained focus on streamlining integrations across their services. This should not be underestimated. The cost of integrating (time and money) is often more than the cost of building a feature. By creating pluggable building blocks, cloud vendors are lowering the entry point (learning), reducing effort, and increasing innovation, by enabling engineers to focus more on business functionality. This all feeds into better TTM, ROI, Agility, and Reputation.
LOWERS OPERATING COSTS
This one comes with some caveats…
Operating software can be an expensive business. Not only must you purchase hosts, software licensing, maintain your existing infrastructure (e.g. patching), and the underutilisation of capacity (a big problem), but there’s also the physical costs (site rental, staffing, electricity, cooling), redundancy (i.e. two data centres in case of disaster), high availability, and scalability. Each aspect has an associated cost to the business, not including the general toil and cognitive overhead.
Conversely, cloud vendors can offer a rather attractive alternative, stemming from the two key principles of shared resources and Economies of Scale.
The Economies of Scale model gives vendors better spending power, enabling them to purchase vaster quantities of compute at a lower unit rate, and thus, pass those savings on to their customers. This creates a cycle of incentivising greater custom, and thereby further establishing the vendor’s buying power.
Shared resources (typically realised through virtualisation) are another key aspect used to lower costs. Historically, it’s been very difficult to accurately provision capacity against actual needs, thus forcing many businesses to over-purchase (increased CapEx) to mitigate potential scalability and availability challenges they may face. This leads to under-utilised assets (typically hardware) - a form of (profitability) waste. Virtualisation - the ability to place a layer of software abstraction over physical hardware, both to mimic it and to share those resources - has changed this, enabling greater sharing potential (Single Tenancy v Multi Tenancy), reduced waste, and therefore a financial saving.
Finally, whilst the cloud generally offers customers an enticing deal, it’s not necessarily always the case. For example, the use of a Lift-and-Shift approach, or Serverless technologies doesn’t guarantee a better deal (e.g. you may find the per-unit cost of the Serverless model to be more expensive than a busy “always-on” service). It's incredibly important to calculate the costs (total cost of ownership) before making such a decision.
KEY TECHNICAL ENABLERS
The cloud doesn’t just offer a wide range of services that can be provisioned in minutes, it also embeds key technical qualities within them, including:
- A powerful shared security model. Security can be hard. Anything that reduces the scope/burden placed on customers is therefore good. In the shared security model cloud vendors protect the infrastructure, whilst customers concern themselves with configuring the services they select, their applications, and their data [1].
- Massive Scalability. Many cloud services exhibit significant scalability traits out-of-the-box and managed through configuration.
- Fast provisioning. The ability to spin up a new environment in a matter of minutes is powerful, both as a path to innovation, but also for systems and business resilience (i.e. Business Continuity and Disaster Recovery - BCDR). Risk to business continuity is mitigated if a new replica environment may be spun up in minutes.
- High Availability. Many cloud services can be deployed in fault-tolerant, high-availability zones (e.g. Availability Zones) - again, typically through configuration.
- High Integrability. Technical staff want to deliver value faster, but also have sufficient agility to change direction. To do this, they need the ability to quickly link different components together, or adjust a solution to use an alternative component, with minimal fuss. This requires high Integrability - something cloud vendors are accomplished at.
GLOBAL INFRASTRUCTURE
The cloud’s global infrastructure allows businesses to take advantage of services with global reach. This is vital for businesses with customer bases (or aspirations to have) across many different countries or regions.
Historically, support for this model has been limited, creating agility friction (it was typically “solved” either by treating each region as distinct and trying to aggregate the datasets, or building out a CQRS pattern). Today though, we find the vendors have done the work for you, with some cloud services being truly global, supporting the same datasets across any region, and providing low latency access to that data.
LIFT-AND-SHIFT MODEL
The cloud creates greater optionality, and as such, it also appeals to established businesses with legacy applications. One such option is (the sometimes notorious) Lift-and-Shift model.
Consider for instance a business with a legacy application. They have recently signed a big deal, and must now significantly enhance one or more key technical capabilities within their product to support the deal (e.g. scalability, higher availability, disaster recovery, or even complexity). Unfortunately, the nature of the legacy application doesn’t fit well with the business’ aspirations; enhancing the current on-premise deployment model is unachievable or it’s too costly to (pragmatically) accept. Rather than follow this path, they look to a (partial or full) lift-and-shift into the cloud.
A lift-and-shift then is the concept of lifting the whole (or part) solution from an on-prem location and shifting it to the cloud, and thus benefiting from all of the services (hosting, networking, storage) and superior technical capabilities (like massive scale or high resilience) that it offers. You can find more on lift-and-shift here.
NOT A SILVER BULLET
It's worth noting that - at least from my experience - a lift-and-shift tends to be a short-to-medium-term tactical solution. It’s not a silver bullet to solve all of your problems, rather it’s something to provide breathing space whilst a more permanent solution is found. After all, a poorly designed or implemented application is still that, regardless of where it is situated.
HYBRID MODEL
Although sometimes overlooked in favour of a purely cloud-based solution, the hybrid cloud model can also be beneficial. It’s a hybrid residency approach, where some parts of an application/product are hosted in the cloud, and other parts are hosted on-premise.
This model suits businesses who either already have an existing solution and want to move parts of it to the cloud, or still have reservations about a wholesale migration to the cloud. It's useful because it enables businesses to reap some of the cloud’s benefits (e.g. scalability), without necessarily making a decisive leap into the cloud. A common realisation of this pattern is to use the hybrid model to shift part or all of a software application into the cloud, but retain the data on-premise.
SUMMARY
Ok, so you’ve patiently listened whilst I waxed lyrical over the cloud, however, I think it worth sounding a note of caution around vendor lock-in (Cloud Agnosticism). You need to make a decision. Do you use cloud services, thereby obtaining fast TTM, but potentially tying yourself to that vendor, or do you reduce that risk, by supporting more standardised technologies, thus slightly reducing speed and innovation, but enhancing business Agility?
FURTHER CONSIDERATIONS
- [1] - there is some minutia around platform type too (e.g. IaaS, PaaS) but it’s outside the scope of this book.
- CapEx v OpEx
- Cloud Agnosticism
- Economies of Scale
- Innovation
- Lift-and-Shift
- Single Tenancy v Multi Tenancy
SERVERLESS
The term Serverless is a misnomer for what is essentially an approach for managing and running software on a compute platform. It’s a term most often - but not exclusively - associated with cloud computing.
The big (foundational) idea is that in order for businesses to remain competitive they need developers to deliver more and more value (features). This is fine in theory, but - in practice - it’s not a developer’s only concern. For instance, developers must often undertake platform-related activities in order to make their software accessible; e.g. “take the software I develop over here, identify the hosts I need to deploy it to, configure those hosts, connect and then drop the executable software onto them (in the right location), hook up a load balancer, and then start up the services. Now repeat some of those steps multiple times...”. This whole endeavour is time consuming, and drives developers away from their main intent - to build features.
This is the problem Serverless attempts to solve. Serverless provides developers with a layer of abstraction from (many) platform specifics. It separates the ownership (and management) challenge more explicitly, with vendors taking ownership of more of the platform, whilst developers can focus more on building out functionality, assuming that they follow certain platform rules (i.e. it is opinionated). Although not a direct comparison, Serverless has similar qualities to the PaaS model.
In Serverless, developers don’t know (or care) which hosts their software runs on, or even when it is or is not running, as long as that service is available for execution when users need it; i.e. requests are handled just-in-time (JIT). The JIT aspect of Serverless caters to reduced waste.
THE SERVERLESS MISNOMER
The term “server-less” suggests that there are no “servers” used in this approach. Quite simply, this is not the case. The platform owner is still using hosts/servers to run your software; it’s simply been abstracted from you as a customer.
Enabling the abstraction of where software runs (no Host Affiliation) and supporting a JIT availability model also allows us to consider the next logical step - the ability to use this model to positively impact the runtime characteristics of our software. Indeed, Serverless allows us to flexibly and swiftly adjust to variations in the following areas:
- Scalability. Serverless is extremely elastic; it can scale up to incredibly high rates in a short time (assuming you’ve configured it to do so, and you’ve built the solution well), or down to a zero-usage model (where nothing is running, and thus incurs no costs).
- Availability. The lack of direct host affiliation and faster start-up times also supports greater availability.
- Resilience. The speed at which serverless functions spawn also makes it ideal from a recovery (and thus resilience) perspective.
And lastly, we should discuss the Serverless pricing model. Using a pay-per-use model offers customers a much finer granularity of payment. Again this stems from its characteristics of low Host Affiliation and just-in-time (JIT) availability, enabling payment to be measured (and taken) at an individual transaction level rather than per month.
As I mentioned earlier, Serverless is opinionated. It is typically realized by using (Serverless) functions, which adhere to certain platform rules, are configured for execution on the target platform, and are then deployed to that platform (note that deployment to a specific server is handled for you by the platform owner).
FUNCTION TRIGGERS
These functions can be triggered by a range of events, including HTTP events, scheduled events, or even database operation events (e.g. an insert). They can also be integrated into lots of Cloud services, such as eventing systems or database services.
Most cloud vendors support a number of different languages (including JavaScript, Python, Java, and C#).
SUMMARY
Serverless is a compute platform for managing and running software that offers excellent Scalability, Availability, and Resilience qualities. It is based upon two foundations:
- Low Host Affiliation. There is a low coupling to any specific host.
- Just-in-Time (JIT) availability. The service is offered just-in-time.
The term “server-less” is a misnomer. The platform owner still uses servers to execute software; specifics are abstracted away from you as a customer.
Serverless has a couple of potential gotchas to watch out for. Firstly, watch out for vendor lock-in (Cloud Agnosticism). It's easy to embed assumptions into Serverless functions, to bind them onto other vendor services, or to tie them to vendor libraries, thus creating Change Friction. This is natural, but one to be wary of if you want business agility.
Secondly, whilst the Serverless pricing model is generally seen as advantageous, be cautious of the pricing-per-transaction model when the service is “always on, and always busy”.
FURTHER CONSIDERATIONS
- Change Friction
- The Cloud
- Cloud Agnosticism
- PaaS
- Vendor Lock-in - https://docs.microsoft.com/en-gb/azure/architecture/example-scenario/serverless/serverless-multicloud
CLOUD AGNOSTICISM
The concept of Cloud Agnosticism is an interesting one. In one sense, I see concerning developments that may create serious Agility challenges for some businesses in the future, whilst at the other extreme there are real benefits to businesses who align their solutions around a single cloud vendor platform.
As technologists, we’ve been pondering the problems of vendor lock-in (in different guises) for decades. The cloud is no different, except in one area - the scale of the potential lock-in is far wider within a single business, yet the clouds’ ubiquity also means it also finds its way into more businesses. Let’s start then, by understanding this thinking, before moving on to discuss concerns.
Whilst most cloud vendors provide similar services (e.g. Serverless, storage, graph databases), their implementation and the assumptions they make, often differ, creating something proprietary. In isolation, this needn’t be a significant concern. However, also consider that cloud vendors are enabling (and even incentivising) integrations between their services at a frighteningly fast pace. Yes, that’s right. In this instance, the problem could be their ability to offer such a good service! Some paradox eh?
Cloud vendors quite naturally tend to focus their initial efforts on building and integrating into their own services (it typically creates the least friction). This creates a far more appealing platform for customers, and promotes Innovation. But there are consequences. It often leads customers to consume even more (highly integrable) vendor-specific services, which often contain specific Assumptions about: how or where it runs, its qualities, or how others integrate with it.
TIGHT COUPLING
The ease with which consumers can plug-in to other services carries its own risk - the risk of tightly coupling yourself to another without necessarily being aware of it.
“Want a messaging solution? What about our own vendor solution?”, “Need a streaming service? We’ve got a great one right here that’s easy to integrate into.”, “An API gateway? Sure, we’ve got one here. Just write the proxies you need in our proprietary DSL and you’re good to go.” See my point?
If I were to offer you a software service with excellent security, scalability, availability, resilience, and integrability - you’d likely bite my arm off. And why not? And if I could support you again and again, I’m sure you’d still be agreeable. We are - after all - talking about significant TTM benefits. So, is there really a concern, and if so, what is it?
Well, it depends. Increasingly, I’m seeing a more implicit coupling decision-making process. We’re embedding an increasing number of Assumptions into our systems that (a) don’t cross platform borders, (b) create a form of stickiness and potential pollution, and (c) we aren’t necessarily being alerted to them. The simplest road may well be the quickest, but it's not necessarily the best (Short-Term v Long-Term Thinking).
Cloud vendors offer great change impetus, but it can lead us to do rash things that we wouldn’t necessarily do, given more (thinking) time. The most obvious one relates to Portability, Flexibility and business Agility. I’ve been involved in numerous discussions and decisions around agnosticism, and - in short - selecting a specific cloud vendor isn’t solely based on sound technical arguments. Politics, deal-making, support in the sales stage, and client expectations can also play a major part. An aspiration to build a SAAS solution - thus making vendor choice a moot point - is a noble undertaking; however, I’m afraid reality may differ.
OTHER CONSIDERATIONS
I’ve seen vendor decisions influenced by sales partnerships - i.e. is the vendor willing to support your sales process with its own presence? I’ve also seen them shaped by a client(s) dictated preference. This can occur if a business sells to one or more “big-name” clients with a lot of clout, and they want more control (Control) than a typical SAAS solution. It’s quite likely those clients already have a preferred vendor (and one they’re willing to support), which may differ to your own, and thus create sales friction.
In these circumstances you must either stick to your guns, or find an agnostic solution that can cater to every client's needs.
SUMMARY
The decision of whether to make widespread use of vendor specific technologies isn’t always straightforward. Should you use proprietary cloud services, you probably gain good TTM and Innovation, but tie yourself to them. Should you reduce that proprietary footprint, then you may reduce speed and innovation, but get excellent business Agility.
Standardisation supports agility, but - because advancement is typically through committees and various discussions - it takes longer to achieve. However, if a standard exists, is well supported (by vendors), is sufficiently innovative, and meets your expectations, then it may be a good fit. Otherwise you may prefer a single vendor.
FURTHER CONSIDERATIONS
DENIAL-OF-SERVICE (DoS)
A Denial of Service (DoS) is a type of attack that targets a system's availability (and resilience), typically with the intent of denying legitimate users access to it. The idea is to flood those systems (Flooding the System) with so many requests, to the point where they either collapse, or are unable to service those requests in a reasonable timeframe. A successful DoS reduces Stakeholder Confidence in the system, and may cause reputational harm.
A Distributed Denial of Service (DDoS) is a specialised form of DoS that engages multiple hosts (distributing the attack workload onto multiple hosts) in order to perform both a wider (stronger) attack, and one that is harder to counter.
A DoS suggests an intentional malice on the part of the attacker; i.e. they are intentionally attacking a system(s) to achieve a goal, which may be financial, political, or even just for thrills and bragging rights. However, we should also be aware of the potential harm caused by an unintended DoS.
A self-inflicted DoS occurs when you unintentionally cause a DoS on a system (often, your own), typically by flooding it with requests (which may be valid for the business, but inappropriate for the context), until it's unable to action other (potentially critical) requests. Some examples include:
- If you have a runaway/rogue process (consuming all available resources).
- If you undertake a resource-heavy activity that consumes system resources needed elsewhere. Consider a team undertaking performance testing during peak business hours, and consuming critical compute or network bandwidth that's needed for legitimate customer use.
- A polling-heavy solution that involves many agents polling back to a central system (e.g. database polling) to check for changes.
FURTHER CONSIDERATIONS
(DISTRIBUTED) TRANSACTION TRACING
Most business transactions are typically composed of multiple discrete transactions, with each managed within its own discrete domain. These transactions represent critical business activities, and need tracked, to ensure that any unexpected consequences can be identified and diagnosed. But how do we track both parent and child transactions across a distributed architecture, when the work is distributed?
Let's look at an example of a (relatively simple) cart checkout transaction workflow, consisting of four distributed components (Carts, Orders, Discounts, and Inventory), and the flow: 1. Create Order, 2. Apply Discount, 3. Reduce Stock, 4. Fulfill Order.

Note that each component has three (Load Balanced) instances (e.g. Orders has instances O1, O2, and O3), distributed - for the sake of argument - across three separate hosts. This makes the exact route through the system unpredictable - there's no guarantee that two successive transactions will follow exactly the same path, nor should we conclude that every business transaction will succeed.
For instance, let's say that the cart checkout for Customer A takes the route: C1, O3, D1, I2, O1. Immediately following that, instance D1 fails, and is terminated, causing the system to spawn a new Discounts instance (D4). The next business transaction (for Customer B) might take the route: A1, O3, D4, I2, and O3. Each subsequent transaction will also be different. Those transactions are distributed and indeterministic, so how do we capture and correlate everything back to a single business transaction?
THE DISTRIBUTION CHALLENGE
The challenge here lies with the distributed model (over the centralised one). We can't gather evidence of every transaction from a single place (i.e. host), because it doesn't exist in a single place.
What's required is a way to trace each request - of multiple, discrete steps - through the entirety of a system, enabling us to easily identify and diagnose problems.
The solution is quite simple. We generate, and then share, a single unique traceId per (business) transaction, across domain boundaries (much as we might when passing the baton in a relay race), using it as a unique marker (for aggregation) in our log files. See below.

LOG CENTRALISATION
Fundamentally we're gluing pieces of the system back together to make it seem centralized when it's not.
The trace id is passed from one service to the next. Each instance writes the shared traceId (alongside any useful service-specific context) to its own log files, which are then published (mirrored) to a centralized log aggregator for searching, filtering and aggregation. We may now observe all transactions within our system at both low and high granularity.
FURTHER CONSIDERATIONS
IAAS, PAAS & SAAS RESPONSIBILITIES
The relationship between Infrastructure-as-a-Service (IAAS), Platform-as-a-Service (PAAS), and Software-as-a-Service (SAAS) may require further elaboration.
Broadly speaking, their responsibilities build upon one other; see below.
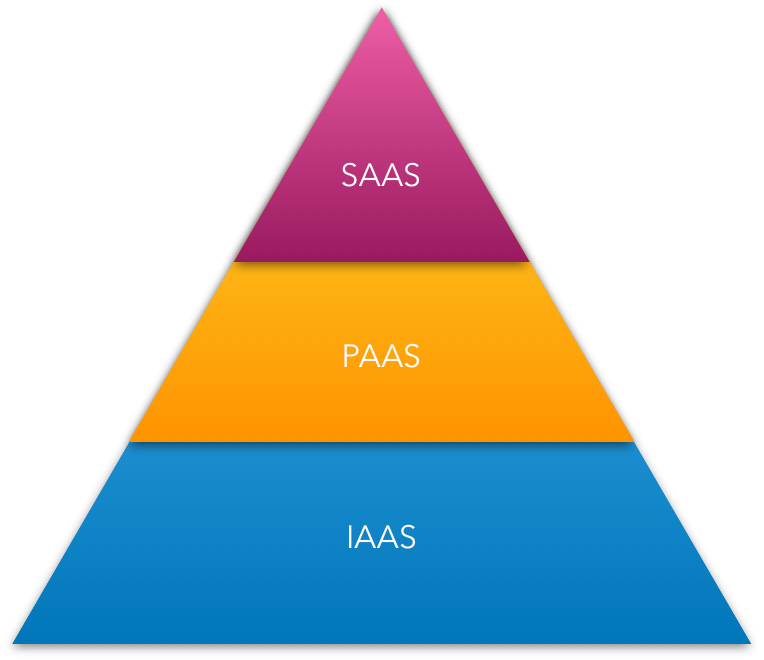
So, a PAAS extends the responsibilities typical of an IAAS with its own, and a SAAS extends the responsibilities of both a PAAS and an IAAS with its own.
CONSUMER RESPONSIBILITIES
Note that I'm describing the responsibilities as perceived by the consumer of the service, not necessarily the underlying implementation. For instance, just because a vendor supplies you a SAAS product doesn't necessarily mean they're using either an IAAS or PAAS solution themselves. That's up to the vendor, and you shouldn't really care. But you - as the consumer - aren't taking on any of those responsibilities.
So, what are these responsibilities? See the table below.
| On-Premise | IAAS | PAAS | SAAS |
| Application | Application | Application | Application |
| Data | Data | Data | Data |
| Runtime | Runtime | Runtime | Runtime |
| Middleware | Middleware | Middleware | Middleware |
| Operating System | Operating System | Operating System | Operating System |
| Virtualisation | Virtualisation | Virtualisation | Virtualisation |
| Servers | Servers | Servers | Servers |
| Storage | Storage | Storage | Storage |
| Networking | Networking | Networking | Networking |
| Vendor Manages This | |||
| You Manage This | |||
As you see, if you manage on-premise, you're responsible for all of it. If you go for an IAAS, then you are responsible for the management of the Operating System, Middleware, Runtime, Data, and Application. All other responsibilities lie with the vendor. If you opt for a PAAS option, then you are only responsible for Data and Applications. And finally, if you go with a SAAS option, then you are responsible for none of it (other than its integration and use), it all lies with the vendor [1].
FURTHER CONSIDERATIONS
- [1] - That's what makes the SAAS model so appealing.
- Infrastructure-as-a-Service (IAAS)
- Platform-as-a-Service (PAAS)
- Software-as-a-Service (SAAS)
INFRASTRUCTURE-AS-A-SERVICE (IAAS)
See: How We Got Here
In our modern world of mass consumerism (Ravenous Consumption), speed is king. The businesses able to deliver change more rapidly than their competitors are at a distinct advantage.
However, in order to achieve (and retain) this speed, they must assess anything that obstructs rapid change. One such obstruction is in the supply of the infrastructure necessary to run our software workloads.
MEANS-TO-AN-END
Whilst we need infrastructure to run our workloads (yes, even in the Serverless model), it's typically a means to an end. The business service (typically offered through software applications and data, but sitting on infrastructure) matters most. The infrastructure is an important - albeit secondary - concern, so why should it require such a heavy cognitive investment?
As described in IAAS, PAAS, & SAAS Responsibilities, the on-premise model expects you to do everything, including sourcing the hardware. But sourcing new hardware is slow, arduous and (often) expensive [1]. You've then got to wait for its delivery, add virtualisation, install and harden the operating system, install middleware, run network cables to them etc - all before placing your workload on it (which, fundamentally, is our goal). That's quite an undertaking [2].
Perhaps unsurprisingly, humans are pretty bad at estimating resource needs, causing us to overprovision, and consequently, creating Estate Bloat [3].
Clearly, this model doesn't suit rapid change (TTM), but neither is it great for ROI, Innovation, or - for that matter - customer-orientation. The conclusion? The delivery and management model was flawed and needed rethinking. Whilst we need infrastructure, we don't want the supplier mechanism that comes with it, nor the costly overprovisioning.
Imagine then, after considering all of these problems, if staff in a business could simply request infrastructure and be using it only minutes later. It would be a sea change.
That's what Infrastructure as a Service is. It's infrastructure, provided to consumers as a service, typically through APIs, command-line, tooling (e.g. IaC), or a front end. You don't get hardware deliveries. It's delivered virtually, from the (Cloud) vendor's location, after which you install the necessary operating system, middleware, and applications.
IAAS is definitely a step-up from on premise. It's the first (giant) step towards a self-service model. It enables you to focus more on delivering business value, but it's still pretty vanilla, requiring you to install, manage, and patch operating systems, middleware etc. That's great if you need that flexibility, but many of us don't. A PAAS builds upon an IAAS, providing a greater range of self-serve options. A SAAS extends that concept further, enabling you to focus on using an application (using it, integrating with it), not running it.
LIFT-AND-SHIFT WITH IAAS
An IAAS can work well with the Lift-and-Shift approach - you lift your current (on-premise) workload, and shift it to a cloud platform, using IAAS. It isn't without problems, but may be a decent stop-gap solution.
FURTHER CONSIDERATIONS
- [1] - Some purchase orders can take months to sign off.
- [2] - It takes time and a sustained effort if you're to prevent entropy.
- [3] - Lots of hardware using only a fraction of their potential resources. This problem was described here (Containerization).
- (The) Cloud
- Containerization
- IAAS, PAAS, & SAAS Responsibilities
- How We Got Here
- IaC
- Innovation
- Lift-and-Shift
- PAAS
- Ravenous Consumption
- SAAS
THE WEAKEST LINK IS THE DECISIVE FACTOR
A system is, by definition, a collection of individual components, parts, principles, or procedures that work together to solve a bigger problem. They are ubiquitous, yet regardless of the environment or domain they function in, they all follow common laws in relation to stress. The decisive factor isn't determined by the strongest, but by the weakest link.
Consider for a moment the Deadlift exercise [1] in weightlifting. It's a compound exercise, working a large number of muscles (and groups), including the: quads, glutes, hamstrings, traps, biceps, forearms, core, and grip. Your ability to deadlift heavy weights (the stress aspect) isn't determined by your strongest muscle (or group), but by your weakest, which is commonly grip strength [2].
Software systems work in exactly the same way. A set of components (or systems) are combined to provide some broader, useful function. When it is stressed (e.g. a significant increase in traffic, connectivity issues, a fault, or the target of a cyberattack), it tends to be the weakest part that fails first, often causing a domino effect on the other parts.
WEAKEST LINK & THEORY OF CONSTRAINTS
This is remarkably similar to the behavior we see in the Theory of Constraints. It's the constraint - i.e. the weakest part of the system - that dictates capacity, nothing else. Fixing the constraint is the only thing that will improve capacity of the overall system.
This principle has important consequences for qualities like Performance (e.g. latency in a synchronous system is heavily predicated by the worst performing component), Scalability (flooding the constraint often overloads the entire system), Availability (e.g. the lack of alternative paths is the weak link; its unavailability causes an outage), Resilience (e.g. recovery of the system is determined by the recovery potential of the weakest component), and Security (e.g. a targeted attack on the weakest link can gain the attacker broader access to the system).
FURTHER CONSIDERATIONS
- [1] - https://en.m.wikipedia.org/wiki/Deadlift
- [2] - Grip Strength is the ability to grip or pinch a load for sufficiently long to complete the exercise.
- Theory of Constraints