Delivery
SECTION CONTENTS
- Continuous Integration (CI)
- Continuous Delivery
- Andon Cord
- Blue/Green Deployments
- Canary Releases & A/B Testing
- Deployment Pipelines
- Andon Cord
CONTINUOUS INTEGRATION (CI)
Continuous Integration (CI) is a practice where work is regularly committed back to a central “trunk” code baseline (Branching Strategies). As the name suggests, it’s intended to support regular integration work from (potentially) multiple sources, thus enabling:
- Fast Feedback. Integration occurs many times a day, ensuring problems are caught early in the developer lifecycle where they can be quickly resolved.
- Greater Customer-Centrism. CI provides a facility to support the continual delivery (Continuous Delivery) of value to a customer.
- Business Agility and nimbleness. Code both contains the latest features and remains in a deployable state, ensuring software can be delivered to the customer at any time, where we can really determine value. This approach also allows the business to pivot (with minimal investment) off of features that show little user engagement.
- Immediate transparency. All change is immediately seen by all (Shared Context) allowing problems to be quickly rooted out.
- Reduced risk. As I mentioned previously (Branching Strategies), branching is an isolationist strategy. It inhibits integration until the very end of the project - something to be discouraged, as it generates risk. Continuous Integration reduces this risk through regular integration.
Code that is developed with CI is (almost) always in a working state and therefore always ready for release (e.g. Continuous Delivery). CI promotes test automation to ensure quality (and as a Safety Net), which also becomes an enabler for techniques like TDD.
CI is typically employed using CI/CD Pipelines (Deployment Pipelines), where a job is executed after a baseline change to:
- Get the latest code.
- Compile it (assuming it’s not scripted).
- Run a suite of unit tests to ensure accuracy.
- Run any quality metrics; e.g. test coverage, code complexity.
- Package and store the outputted binaries for the subsequent deployment phases.
A failing pipeline requires immediate resolution, else it impedes everyone. As such, it’s common to inform the whole team of the failure, and then identify someone (typically the person responsible for the breaking change) to resolve it.
FURTHER CONSIDERATIONS
- Branching Strategies
- Continuous Delivery
- Deployment Pipelines
- Fast Feedback
- Customer-Centrism
- Safety Net
- TDD
CONTINUOUS DELIVERY
Deliver quick, deliver often.
Continuous Delivery (CD) is a relatively new concept within the software industry (but is well travelled in LEAN manufacturing), and represents a fundamental shift, both in how we deliver software, and in the value we place upon that delivery.
Continuous Delivery is a set of practices, tools, technologies, and mindset that (when combined and coordinated) help to deliver a constant stream of value by promoting the following three pillars:
- Fast, efficient delivery. Don’t expend vital capacity in the delivery of software when it’s better spent building out the ideas that will become valuable.
- Regular delivery. Deliver to your customers regularly to get valuable feedback.
- Repeatable delivery. Ensure delivery is repeatable.
Continuous Delivery has gained traction across unicorns, start-ups, and large established corporations, enabling them to keep up, or step ahead of their competitors. Some of the leading companies using it include Google, Amazon, Netflix, Microsoft, and LinkedIn.
WHY?
Before I explain what Continuous Delivery is, it’s important to first understand its origin.
As described in other sections (Lengthy Release Cycles and Atomic Deployment Strategy), long release cycles are notorious (and still prevalent) in many software businesses, and often causes:
- Confusion and misalignment. We don’t know what features are ready and deployed, which environments they are deployed to, or whether the customer is actually using it.
- A high risk of failure due to the scope of the change.
- Low stakeholder confidence, due to delays or rework costs.
- Poor TTM. Lengthy releases are challenging, so - as a natural form of pain avoidance built into our behaviour - we tend to do less of them.
- Poor Productivity. Staff aren’t building software to meet customer needs, they’re wrangling with its delivery.
- Unhappy staff. Long hours for thankless, morale-zapping tasks, and fruitless “release heroics”.
The Internet was a game changer. It commoditized products to a much wider audience, so much so, that many of us are commodity-driven. As this Ravenous Consumption has tightened its grip on an increasing number of businesses, it has forced them to flip their historical market-driven-by-business model to a more customer-driven one (you've only got to look at the digital transformation projects subscribing to a newly acquired “customer-oriented” or “customer-first” slogans to see this paradigm shift).
A “CUSTOMER FOR LIFE”?
The notion of a “customer for life” is a rare breed indeed (just like the notion of a “job for life”). It’s another example of the effect of the game-changer that is the internet.
In large part the accessibility and availability of the internet has increased the Optionality of the consumer. It’s much easier for consumers to source information about alternative suppliers (whether it’s banks, utilities, credit cards, or something else), get advice through reviews, and “switch” to a competing service, than ever. Increasingly, globalization has also had a large part to play; consumers may now select services from a global marketplace, not just businesses (historically) focused on a single region/country.
Some businesses may have grown complacent, leaning too heavily upon an antiquated “customer loyalty” model for too long. They’re now playing catch-up, and looking for alternative ways of attracting, and retaining their customers. They can do this by giving the people what they want; one mechanism to do this is Continuous Delivery.
Change is upon us, and many businesses must reorient and reassess their entire value delivery model. No longer is value mandated by the quarterly (or even annual) releases of big businesses, but by quick, reliable, and low risk deliveries that closely align with customer needs. In many forward-thinking software businesses Lengthy Release Cycles are being usurped by Continuous Delivery practices.
CONTINUOUS DELIVERY QUALITIES
The figure below shows some potential qualities of Continuous Delivery (note that most of these qualities also anticipate a DevOps-driven approach).
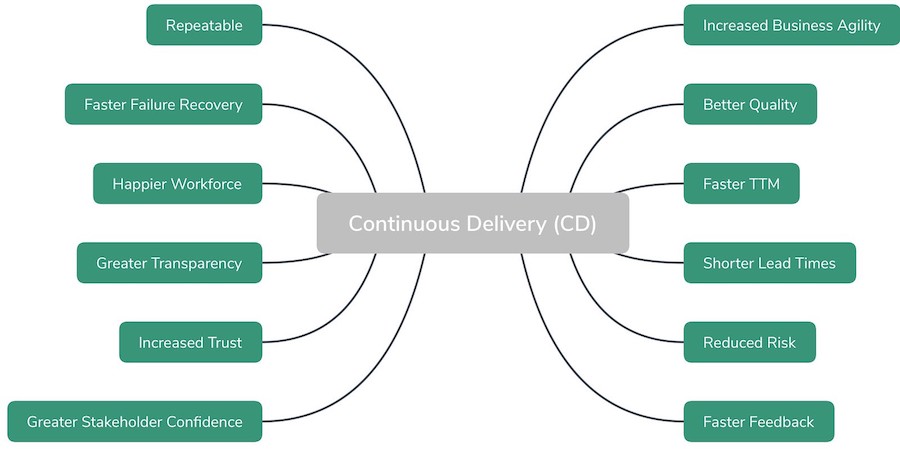
Let’s visit them.
FASTER FEEDBACK & INCREASED BUSINESS AGILITY
Introducing faster change cycles enables us to better embrace (the oft-desired trait of) change of business direction (i.e. Agility).
A software feature represents the manifestation of an idea. And ideas can be good, bad, successful, or unsuccessful. Some can be good and unsuccessful, others less good but highly successful. Success can also be influenced by a plethora of external forces, many outwith your control. The point I’m making is that the idea, along with (one form of) its manifestation, does not necessarily determine success; i.e. in a sense, for any feature, we are betting on its success.
Yet, we are almost always constrained, typically by time and/or money. In betting terminology, we can improve our overall odds by “hedging our bets”.
To “hedge one’s bets” is to:
“Lessen one's chance of loss by counterbalancing it with other bets,
investments, or the like.” [dictionary.com]
To do this, we must quickly recognise a failing feature (or success), and swiftly respond to it. We can do this in two ways:
- Gather and analyse business metrics to objectively measure success, and respond appropriately. If consumers don’t respond positively to the feature, they’ll tell you (either explicitly or implicitly, by not using the feature).
- Minimise drag, by promoting features to the customer at the earliest opportunity.
CONTINUOUS DELIVERY & DEVOPS
Continuous Delivery - in conjunction with DevOps - also intimates a restructuring of historically centralised, siloed teams structures (e.g. the operations teams) within an organisation.
Why? To increase throughput by:
- Reducing resource contention (i.e. multiple teams demanding access to the same resources to meet conflicting business needs).
- Reduce Expediting (a common source of waste).
- Increase quality, through the greater and earlier application of diverse skill-sets to a problem.
- Introducing self-organising Cross-Functional Teams requiring little (micro)management overhead or coordination.
Additionally, with Continuous Delivery, conventional means of committee-based release coordination and communication (such as the contentious Change Control Board) that gives credence to conflicting outlooks and priorities, and reducing business Agility, become unnecessary.
FASTER TTM
Shorter release life-cycles enables faster delivery of value, to:
- Meet desired customer timescales (reducing the need for customer-dictated delivery dates).
- To test the market appetite for this feature.
SHORTER LEAD TIMES
Lead times and waste have direct correlations. Any (partially) completed feature, stuck in Manufacturing Purgatory awaiting use, indicates waste, and has no immediate value, thus poor ROI. The longer the lead time, the less desirable a feature is when it finally arrives, and the greater the likelihood it suffers from competitive lag. Thus, favour short lead-times over longer ones.
BETTER QUALITY
Continuous Delivery offers faster feedback, resulting in swifter defect resolution; the positive residual outcome being better quality. And assuming that Cross-Functional Teams are also employed, we also find that each feature receives a greater investment from a more diverse range of stakeholders, and it occurs sooner. Yet that investment is not solely limited to internal stakeholders (i.e. where the feature may be tested and then forgotten about, until its ready to be released to the customer). Rather, there’s a greater sense of urgency to expose it to real users, quickly. Again, this allows us to focus our improvements in key areas of interest, rather than gold-plating irrelevancies.
Yet “good quality” also includes non-functional aspects, such as Performance, Scaling, Reliability, and Security. In a Continuous Delivery/DevOps model, teams are given greater control over their own deployment, releases, and testing, and are encouraged to resolve their own non-functional concerns without waiting for the availability of some centralised, specialised, business unit to become available. This fast feedback loop encourages experimentation and early refinement; thus, better quality.
INCREASED STAKEHOLDER CONFIDENCE & TRUST
Stakeholder Confidence is a vital aspect of a successful product or service. Closely related to Stakeholder Confidence is trust.
For instance, the cadence built up from regular delivery builds trust - both with the customer, and with internal stakeholders or investors. Whilst missing a deadline quickly builds up a level of resentment, both internally and externally.
Cross-Functional Teams reduce (and often eliminate) the throwing-it-over-the-fence syndrome, enforcing a more collaborative approach that builds relationships and trust, and promotes a Shift-Left culture, with minimal policing and work duplication typical of corporate cultures devoid of trust (i.e. it strongly discourages policing and micromanagement, and stimulates a feeling of trust in one another to do our own jobs). This approach can also flatten organizational hierarchies (Flat Organizational Hierarchies), again effecting a positive cultural impact.
REPEATABILITY
Continuous Delivery’s repeatable nature is a strong incentivizer to both greater internal, and external, autonomy. For instance, internal development, testing, sales, and marketing staff can all automatically provision an independent environment to satisfy their own requirements through a focus on autonomy and a self-service “pull” model. As can external customers, without draining vital internal resources to coordinate those activities, or forcing a rigid “shared environment” with limiting availability windows.
We can also be more precise in understanding change (e.g. within an environment), enabling us to quickly pinpoint specific problems, and reduce the conjecture often associated with an Atomic Release.
FASTER FAILURE RECOVERY
Continuous Delivery enables us to release fixes quicker, or rollback (using techniques like Blue/Green Deployments), providing greater control for swifter failure resolution. This efficient change mechanism promotes Availability, Resilience, and (thus) Reliability, and increases our operational nimbleness.
REDUCED RISK
Lengthy spells of inactivity between the “feature complete” date (when work is done), and the release date (when customers can use it), introduces significant risk because it promotes a Big-Bang Release. For instance, many things may have changed between the point that the release was tested (and known to function), and when it’s released for consumption; or (as I’ve experienced) a critical bug is identified late on in the release lifecycle, and the developer who made the change has left the organisation (a particularly frustrating scenario because little “change context” is now available).
It may also be environmental; i.e. the environment changes after the feature has been tested and passed, and that feature no longer functions. We’ve ticked all the boxes, sent the good news across the business, who’ve promulgated its forthcoming release to the outside world (through marketing and press releases), yet we’re all ignorant to its broken state.
Whilst the whole Big-Bang Release approach is frustrating to all and carries risk, that’s not to say that Continuous Delivery doesn’t carry its own risks (e.g. the potential to expose incomplete work). However, regular releases typically makes deficiency identification and resolution quicker than a monthly/quarterly strategy (Lengthy Release Cycles).
HAPPIER WORKFORCE
Let’s face it, releasing software is often monotonous and thankless. Feature development and enhancement is where the action is. Which is a shame, because getting the release process right is a vital ingredient (more so than developing any single feature - Betting on a Feature) enabling staff to spend longer on feature development (and do so in a highly-focused manner), and less time on the monotonous tasks.
These practices engage employees, increasing staff retention rates, and thus generate greater employee ROI (whilst we might not recognise an employee as an asset, each of us has an on-boarding cost - in the form of training and the support of others - and an ongoing cost (salary). Businesses aim to get a decent return on their staff investment).
Additionally, Continuous Delivery also promotes a Safety Net. This is culturally important; it encourages staff to make quick changes safely, and thus to experiment and innovate (staff solve problems their way), representing another great retention policy.
GREATER TRANSPARENCY
Have you ever worked in an organisation where the technology department were constantly fielding questions from the business in the form of: “is feature A in release Y or the last release, and is that in production yet?”
Whilst technology should know this information, a mix of Lengthy Release Cycles, Single-Tenancy Deployment models, Expediting (etc etc), makes it very easy to lose sight of where each feature is (and which environment it currently resides in). With Continuous Delivery, the feature is (almost) always in production; it just might not be complete, or enabled.
Continuous Delivery with DevOps also promotes Cross-Functional Teams, which as a residual benefit, increases transparency and builds trust between historically disparate skills-groups.
EXTERNAL FINDINGS
A study on Continuous Delivery & DevOps, from Puppet’s State of DevOps 2016 report (I found this one best described what I wanted to present), found that it offered:
| FINDING | THUS PROMOTING (MY INTERPRETATION) |
| 24 times faster recovery times |
|
| Three times lower change failure rates |
|
| Better employee loyalty (employees were 2.2 times more likely to recommend their organisation to a friend, and 1.8 times more likely to recommend their team) |
|
| 22% less time on unplanned work and rework |
|
| 29% more time on new work, such as new features |
|
| 50% less time remediating security issues |
|
i.e. Continuous Delivery & DevOps makes a good account of itself.
PRINCIPLES & TECHNIQUES
Whilst I’ve discussed the qualities of Continuous Delivery in some detail, I haven’t really discussed the principles and techniques that make it possible; some of which are shown below.
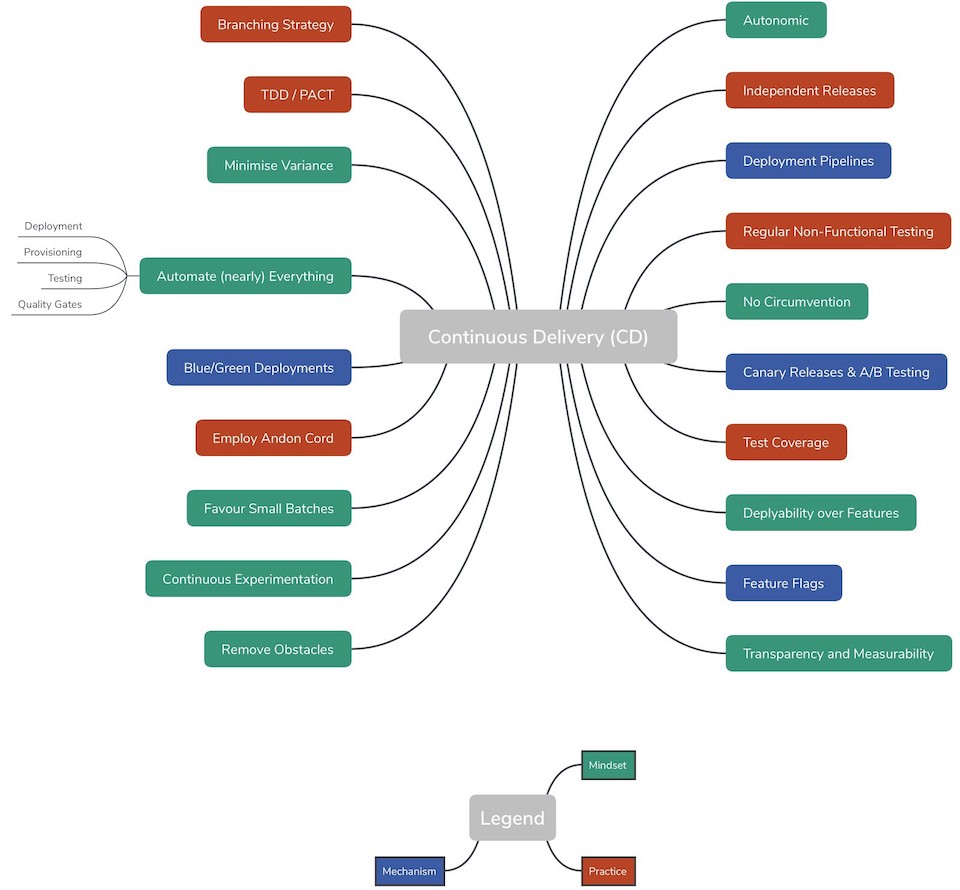
Let’s visit some of them.
FAVOUR SMALL BATCHES
Large batches of work (items) are anathema to continuous practices (Batch-and-Queue Model is inefficient). Large batches have greater risk (the larger it is, the more assumptions, and the more things can go wrong; e.g. Lengthy Release Cycles), shift learning to the right where it’s often impractical to action, reduce comprehension (there’s too much complexity to understand in isolation), and are difficult to estimate. Small batches tend to flow more smoothly through a system, have less impact, and thus can be delivered more efficiently.
Smaller batches (with fast flow) also helps with root-cause analysis. When a problem is identified, there is only a limited number of causes, shortening the diagnosis cycle.
Small batches also increases the visibility of the flow of work from idea to production, enabling it to be measured and compared. It also allows us to gather customer feedback early and often to continuously iterate and improve.
DEPLOYABILITY OVER FEATURES
Functional Myopicism makes it very tempting to focus all effort (and therefore capacity) on building new features for customers. Unfortunately, it's easy to lose sight of the need to deliver that software easily, quickly, and with little (internal and external) fuss. By prioritising software releasability over new feature production we ensure our software is built in a highly efficient manner, whilst also embedding quality, and increasing TTM.
EMPLOY THE ANDON CORD
When a problem is found, employ an Andon Cord to minimise contagion by stopping the system, downing tools on less vital work items, and immediately fixing it. Forcing the immediate resolution to a system problem increases quality and throughput.
EMPLOY CONTINUOUS INTEGRATION
Continuous Integration is the concept of continually integrating (code) change back to the working shared area, where it can be immediately accessed/consumed. It’s a foundational concept that Continuous Delivery builds upon. The continuous integration of change has several benefits, including:
- Immediate feedback (e.g. Fail Fast).
- Reduces the likelihood of large batches of change.
- Promotes collaborative working practices.
- (theoretically) Signals that code is always shippable.
INDEPENDENT RELEASES
Independent releases are another important aspect of both continuous practices, and modern application architectures, like Microservices. Decoupling the release of distinct software domains of responsibility increases our flexibility by enabling us to precisely deliver the area of change.
DEPLOYMENT PIPELINES
Deployment Pipelines are a key mechanism for making Continuous Delivery possible. They are a means of achieving the fast, reliable, and consistent delivery of software across multiple environmental boundaries.
Typically, with modern decentralised architectures (e.g. Microservices), one (or more) deployment pipelines exist per service. This promotes a more fine-grained control (than the historic atomic Monolithic one), enabling fast change turnaround, yet, due to an inherent and intentional pipeline Uniformity, it also exhibits a small learning footprint.
ENGAGE DECISION MAKERS & REMOVE OBSTACLES
Whilst this point may seem incongruous, embedded as it is within the others, it’s extremely important. Undertaking any program of change (and Continuous Delivery is no different) is difficult without successfully engaging the key decision-makers to invest in them. By employing management and executive support to focus on the removal of obstacles that impede flow (the “constraint” in the Theory of Constraints), we increase our likelihood to succeed.
BRANCHING STRATEGY
The selected source-code Branching Strategy affects your ability to continuously integrate (Continuous Integration), and therefore to efficiently deliver software.
Any approach that isolates a (code) change (isolation increases differentiation, and thus divergence) outwith the working area creates another form of Manufacturing Purgatory, or that temporally couples to an individual’s availability (e.g. to manually review and merge a branch of code), has the potential to introduce risk (through divergence) and impede flow.
That's not to say that I advocate no form of review (some industries may well mandate one), but alternatives, such as Pairing/Mobbing, may better support a constant stream of change, reduce temporal coupling (of bottleneck resources), and devalue formal merge procedures.
EXPEDITING & CIRCUMVENTION
Expediting is a common pitfall in (particularly reactive) businesses; it occurs when a feature is deemed more important than the others already in the system, so is given priority. Expediting typically involves Context Switching; work stops on the current work items, the system is flushed of any residual pollutants from those original work items, and then work is begun on the expedited work item.
It’s quite common for the expedited feature to be trumped by another newly expedited feature, like some horrific ballet of priorities (Delivery Date Tetris), often led by influential external customers (customer A has now trumped customer B), or through internal office politics and wrangling, as one department vies with another for power.
Expediting can also lead to circumvention. Established practices are circumvented to increase the velocity of a change (expediency), or so we hope. Yet that introduces risk (those practices are probably there for good reason), and also embraces a maverick attitude (culture), where some are above the need to follow established practices.
We expedite and circumvent mainly from time pressures. We can reduce those pressures through efficient and reliable delivery practices.
FOCUS ON AUTOMATION
Continuous Delivery places a heavy emphasis on automation, mainly at the configuration, environment provisioning, testing, deployment, and release levels. Anything that can (sensibly) be automated (bearing in mind ROI), should be.
Why automate heavily?:
- Provisioning - I (like many others) have suffered countless nights of ad-hoc provisioning exercises solely for the purpose of giving customers or staff (e.g. sales and marketing) access to a service. In many cases, the environment was never used, or only cursorily. This is a massive waste of resources that could (should) be focused on new features. By automating the provisioning of environments, we enable a wider range of internal and external consumers to access your services at a time that’s convenient to them, whilst also minimising the painful Expediting of these ad-hoc requests.
- Deployment and Release - once the environment is provisioned, we now need an efficient, reliable way to deploy and release our software onto it. Techniques like Deployment Pipelines provide fast turnaround, fast learning, and minimise waste, and are central to Continuous Delivery.
- Testing - this is covered in the next section.
AUTOMATE NEARLY EVERYTHING
Not everything is automatable, nor should everything be automated. It’s practical to automate anything that changes often, is painful to do manually, or that has significant consequences if something is missed; but it should always be done with an eye for ROI, and the Seven Wastes.
For instance, is it sensible to automate a highly stable and unchanging solution that already has a complete set of written test specifications? Possibly. But then again, it’s context-sensitive and may depend upon many factors.
It’s worth pointing out that there’s been several high-profile businesses (car manufacturers) who’ve attempted - and failed - to automate everything. There’s also cases in that same industry where automation has been removed. [2]
TEST COVERAGE
The promises of Continuous Delivery aren’t really achievable without a focus on test automation, and a key one around high automated test coverage.
Why is this important? Manual activities are (often) mundane, take time (i.e. money), and are error-prone, often due to the high degree of specialism/domain experience required of the testers. Typically, manual testing is undertaken late on in the release lifecycle (e.g. a UI must be made available, but that’s not hooked up till well after the APIs are available), and - because Quality is Subjective - that makes them a target for exemption, or reduced amount of ”selective testing”, when a deadline looms. This is a dangerous practice.
However, there’s also an additional risk to internal efficiencies. Software that lacks a high degree of automation and coverage typically has lower Stakeholder Confidence amongst the people building it (developers/testers); i.e. there’s no Safety Net to use to drive forward innovation and learning (Continuous Experimentation).
AUTONOMIC
Autonomic (self-healing) solutions are more resilient to failure; i.e. they self-heal. Continuous practices support more autonomic solutions through a mix of technologies and techniques, including - for instance - orchestration (e.g. Kubernetes’ declarative approach enables it to automatically identify failing services and undertake remedial actions, such as killing and spawning new instances), Blue/Green Deployments (semi self-healing, through rollback to an earlier branch), and Canary Releases (stop routing all traffic to the offender and revert back to the established path).
It’s also an interesting fact that within Toyota, the Andon Cord was used to instill autonomicity into their system/culture.
UNFINISHED FEATURES & FEATURE FLAGS
Continuous Delivery delivers (both complete and incomplete) features to a production environment, continuously. Consequently, not all features will be complete or ready for consumption. Yet, by deploying them, we still gain valuable learning, and reduce risk. This implies the need to hide certain features until we’re ready to expose them.
We can toggle the availability of features using a technique called Feature Flags. Basically, we wrap the contentious area of code around a configurable flag indicating its available state. Consumers can use enabled features, otherwise they can’t.
BLUE-GREEN DEPLOYMENTS
Consider this, you’re about to deploy a new set of features to production. Whilst you may have a high degree of confidence, any deployment has a degree of risk, and any downtime could have significant monetary or branding implications. The prudent amongst us would have a back-out plan if things go awry. Blue/Green Deployments is one such approach.
Blue/Green provides a fast rollback facility through a change in the routing policy. It increases Optionality, particularly relevant in times of trouble, by providing another route back to safety if things go awry.
CANARY RELEASES & A/B TESTING
Canary Releases and A/B Testing limit Blast Radius, enabling us to trial an idea (to prove/disprove a notion) to a subset of users, and provide a way to (gradually) increase its exposure to a growing number of users. They are a powerful way to innovate upon established product/features in a non-intrusive way. See the Canary Releases section.
TDD/BDD/PACT
Test-Driven Development (TDD), Behaviour-Driven Development (BDD), and PACT are all testing-related approaches that can improve Productivity, quality, and Stakeholder Confidence (partly through the use of a Safety Net). See TDD/BDD/PACT.
CONTINUOUS NON-FUNCTIONAL TESTING
One issue I have found with Lengthy Release Cycles is it often feels like non-functional testing (e.g. performance testing) is given a second-class status. Often, these type of tests are deeply involved, and tend to be performed to the end of the “release train”, where there’s rarely time to comprehensively test them before the next big deadline hits (i.e. it limits Optionality). This also contradicts the Shift-Left and Fail Fast principles - problems are only exposed late on where there’s little time to fix them.
LARGE BATCHES & NON-FUNCTIONAL TESTING
These problems may relate to delivering large batches (they typically have greater risk of failure, so we procrastinate), a lack of Uniformity, late accessibility (either API or web UI), and the centralised, siloed, organisation of teams.
Continuous Delivery allows us turn some of this on it’s head. We can embed performance and security testing in a more fine-grained manner (assuming a distributed architecture and deployment pipelines), gaining early feedback, then introduce them into a larger flow (e.g. user journey) with a greater degree of confidence. These tests also provide a form of Safety Net - we gather feedback sufficiently soon to pivot onto alternative strategies.
MINIMISE VARIANCE
Subtext: Promote Uniformity.
One of the biggest business wastes I’ve witnessed was their Single Tenancy product delivery model. Admittedly, at the time, the model was chosen for sound reasons (the multi-tenancy model wasn’t really popularised like it is today under the Cloud, and it encapsulated each customer from unnecessary change, or Scalability/Availability resource contention concerns caused by another tenant). Yet it also led to significant divergences in the supported product versions (different to each customer). This caused the following problems:
- It introduced significant complexity and business coordination activities (e.g. regular Context Switching of testers).
- It hampered the business’ ability to scale.
Modern continuous practices often promote Uniformity (e.g. deployment pipelines all look very similar, regardless of the underlying implementation technology of the software unit), simply because many variations may lead to the poorer scaling ability of the business, even when unit level productivity is greatly improved (Unit-Level Productivity v Business-Level Scale).
FURTHER CONSIDERATIONS
- Branching Strategy
- Blue/Green Deployments
- Deployment Pipelines
- Feature Flags
- Andon Cord
- The Cloud
- Safety Net
- Shift-Left
- Expediting
- Fail-Fast
- Lengthy Release Cycles
- Quality is Subjective
- Unit-Level Productivity v Business-Level Scale
- Canary Releases, A/B Testing
- TDD/BDD/PACT
- Tenancy Model
- [1] - https://en.m.wikipedia.org/wiki/Technology_adoption_life_cycle
- [2] - https://www.forbes.com/sites/joannmuller/2018/02/16/tesla-thinks-it-will-school-toyota-on-lean-manufacturing-fixing-model-3-launch-would-be-a-start/#3bfc05954c74
THE ANDON CORD
An Andon Cord is a LEAN term representing the physical or logical pulling of a cord to indicate a potential problem (an anomaly) and halt production within the system.
THE "SYSTEM"
The system in this sense is not some technology or software product, but the manufacturing system used to construct the systems and products the business sells.
Faults in a highly-efficient and automated production system can be very costly to fix. The products and services offered to consumers may well be vital, and/or have a high rate of dependence placed upon them from many downstream dependents; i.e. clients/partners/customers. Any failure may cause reputational harm, devalue your sales potential (Sellability), and potentially places your business in the firing line for customer recompense and litigation.
Many businesses face the prospect of two opposing forces; protecting your Brand Reputation, whilst also innovating/moving faster (TTM). We can’t slow down, but that may cause more mistakes, so we must limit the Blast Radius of any failure.
A RETURN TO BALANCE
Let me elaborate. Whilst automation is fantastic - it removes monotonous, (potentially) error-prone manual work, increases a business‘ ability to scale in ways that are unrealistic to achieve by investing in new staff, and it may also increase flow efficiency if employed in the right areas.
But... balance is everything. With great efficiency comes great risk. Automation increases the potential to flood the entire system with a fault that is replicated far and wide.
Let’s say a fault is (unintentionally) introduced into the system, and - due to the system’s high capacity - pollutes tens of thousands of units (or in the software sense, tens of thousands of end users).
There’s two problems for the business to solve:
- Rectifying the fault in the product that’s already with the customer. If it’s a physical unit (such as a car), it requires a more invasive approach (car recalls, for instance), whilst that’s not necessarily true with software (e.g. SAAS). I won’t discuss this further here as it’s not directly related to an Andon Cord.
- Rectifying the system to prevent further faults being delivered/processed.
SURELY THAT’S IRRELEVANT IN THE SOFTWARE WORLD?
You might initially think this is solely a physical unit problem, irrelevant to the highly shareable software-hungry world we live in. But software typically manages data too (which is often viewed as a business’ “crown jewels”); and any data inaccuracies (integrity issues) may have very serious ramifications; i.e. it may not be a single product “feature update”, that can be patched and quickly distributed to each user simultaneously (such as in a SAAS model).
So, let’s assume the system is processing a “unit” that is both unique to each customer and great emphasis is placed upon its accuracy. For example, maybe the automated system is processing a legal document, bank account, or a pension plan, and then spitting out its findings to another service to modify the customer’s record. In this case, the uniqueness and import may pose significant problems.
Furthermore, we should not discount the complexity of the domain under inspection. It’s complexity may well be the key reason for its automation in the first instance, and thus the business’ inability to source and train staff to undertake operational activities efficiently and accurately (i.e. the business couldn’t scale out in this manner). When a fault is identified, that domain complexity may be a significant impediment if accuracy can only be confirmed through manual intervention (the key constraint which the business looked to resolve through automation).
Let’s elaborate on the second problem. Say for every minute of work, the system pollutes fifty units. Within an hour, there’s 3000 (50 * 60 mins) faulty units, all potentially visible/accessible (it reminds me of the “Tribbles” in the original Star Trek series [1]). There’s now (or should be) a sense of urgency to stop exacerbating it. So, you pull the Andon Cord.
ANOTHER FINE MESS
Note that employing the Andon Cord does not necessarily indicate a fault, or an awareness of the problem’s root cause. However, it does indicate the suspicion of a fault.
When the Andon Cord is pulled, the entire system is stopped, awaiting a resolution. Workers, and processes, down tools on their current tasks and immediately work on its resolution.
Why immediately stop the system and look for a resolution?:
- We don’t exacerbate the problem; i.e. stop further waste.
- We promote better root-cause analysis. The longer a problem persists, the harder it becomes to track its root cause, and thus improve the system. Shortening this gap increases the likelihood of identifying (and thus, resolving) the problem.
- Culture. We instill a positive culture where failure is expected and staff are recognised for “improving the system” (see the next point).
- By improving the system, we do one (or both) of the following:
- Increase throughput, or “flow” through the system (i.e. better TTM), and/or,
- Reduce waste (i.e. increase ROI) through the system.
FURTHER CONSIDERATIONS
- [1] - https://en.m.wikipedia.org/wiki/The_Trouble_with_Tribbles
- Continuous Delivery
- https://itrevolution.com/kata
BLUE-GREEN DEPLOYMENTS
The software industry is a funny business. Complex Systems abound, and any change is fraught with hidden danger. There is a never-ending battle between the need for stability (traditionally from Ops teams), and the desire for change (Business & Development) (Stability v Change).
Blue/Green Deployments provides a powerful software release strategy that supports stability, yet still enables innovation and rapid change. From the end user’s perspective, Blue/Green is achieved through Prestidigitation.
PRESTIDIGITATION
Predestination (meaning “sleight-of-hand”) is a key part of any magicians arsenal [1]. A good magician can keep the audience focused on one thing, whilst the key action (the “switch”) occurs elsewhere.
That - from a customer’s perspective - is Blue/Green. The remainder of this section will describe how it does this.
Blue/Green has the following qualities:
- Enables both a form of stability (Principle of Status Quo), and of change.
- (typically) Increases Availability.
- (typically) Increases Resilience.
- Provides an insurance policy if things go awry.
- Supports technology modernisation. We can migrate to new versions of technologies with relative impunity.
- Limits (to some extent) Blast Radius, by ensuring failures are better contained and managed.
- It forms a type of disaster recovery. The switch you perform in an upgrade may be very similar to the one you’d perform if there were a disaster.
Let’s see it in action.
HOW?
Blue/Green is achieved through a mix of Indirection, environment mirroring, Expand-Contract (for the database), and Prestidigitation. However, the best explanation begins with an understanding of the traditional upgrade model.
In this (simple) example our product is represented by three services; S1 (v3), S2 (v1), and S3 (v2), (where v represents the version; e.g. v3 is version 3). See the figure below.

Target State
Let’s assume we’ve improved services S1 and S3 by adding new functionality and wish to deploy the latest versions of them:
- S1 (version 4).
- S3 (version 3).
The following sequence is typical of a traditional software upgrade:
- Identify a quiet period when little (or preferably no) users are using the system (often referred to by staff as “unsociable hours”).
- Stop any affected infrastructural services so they’re not serving requests.
- Backup the existing state, including the databases, in case we need to revert it.
- Deploy the changes (software services and data) upon the existing environment (key point).
- Configure any new features for use.
- Start up the existing environment with the new changes.
- Perform any unintrusive smoke testing in parallel to customers using it.
I’ve known cases where backup, deployment, then configuration could take hours.
The figure below shows the target state.

Target State
This approach is fraught with difficulties and dangers, including:
- A technical expectation on the business that downtime is permissible (Tail Wagging the Dog). There’s an expectation that the business has quiet periods with little user activity, which isn’t always the case.
- Potentially lengthy downtime during the upgrade process.
- An implicit agreement that any users currently using the business services may create orphaned records/transactions and be subjected to a poor user experience.
- An expectation that it’s acceptable for a rollback to cause further (potentially significant) downtime.
- That it’s acceptable to verify the success of the deployment in a LIVE setting, whilst the system is undergoing real use.
- That the environment (and its configuration) persists and is non-perishable. It may also suffer from Circumvention. This is a resilience anti-pattern (Cattle, not Pets).
- Fragile Big-Bang Releases - because (technology) staff are relatively expensive, we can’t expect them to regularly work late (unsociable hours) to release software (else our budget is eaten up by delivering software, not producing it). So, we procrastinate on delivery, creating further technical, delivery, and business risk.
These failings are increasingly unacceptable within our modern “always on” outlook. Blue/Green offers an alternative.
Again, let’s assume we’re deploying new versions of services S1 (version 4) and S3 (version 3). However, in this case we are managing two parallel environments:
- A "Blue" environment.
- A "Green" environment.
First, let’s make some assumptions. Let’s assume the current LIVE environment (which our users are accessing) is the blue environment, and contains the existing service versions. You may start with either environment, as long as it’s not currently LIVE. We then create a second environment (the green), to mirror the blue in all ways excepting the deployed applications (ignore the database for now, which has its own challenges). See figure below.
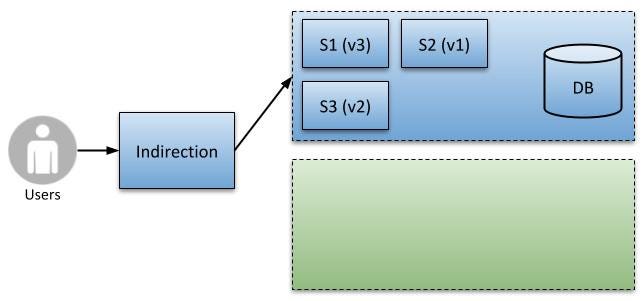
Starting Position
CATTLE, NOT PETS
I'd prefer to see a new environment provisioned from scratch, rather than reusing an extant one, as it better serves the Cattle, not Pets resiliency principle - we make much fewer Assumptions about the environment’s current state, and it counters Circumvention.
We now deploy the software upgrade to our green environment, resulting in two (relatively synonymous) environments. See below.
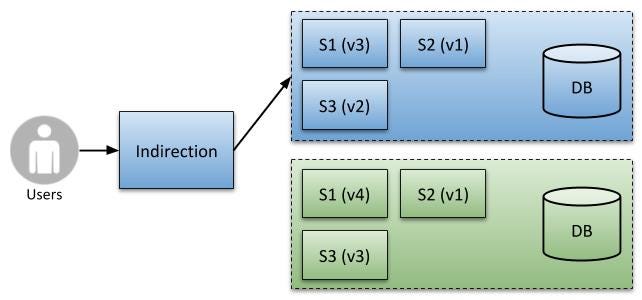
Initial Deployment
Note that all of our users are still accessing the blue environment. No-one is yet on the green environment. In the meantime, you can - with a high degree of impunity - run a barrage of tests in the green environment to verify its accuracy, prior to any real users accessing it, using smart routing techniques (like Canary Releases) in the Indirectional layer. See the figure below.

Canary Release Ability
Once we’ve confidence in the changes, we’re now in a position to make the switch. The Indirectional mechanism you’re using (e.g. Load Balancer, or DNS) is reconfigured to route all new traffic to the other (green) environment (Predestination). All users are now being served by the green environment. See below.
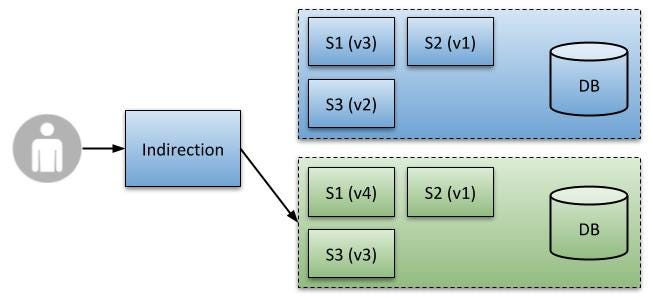
Switchover to Green
WHAT HAPPENS TO EXISTING REQUESTS?
Some of you might be wondering about what happens to any existing requests currently on blue, whilst the switchover to green takes place? Do these transactions escape, create data inconsistencies, and thus surface as troubling business issues?
Whilst this could occur, there are several countermeasures. For instance, if we do a Blue/Green database replication switch (see later), you can replicate change across both databases (and theoretically lose nothing). Another approach is to push the problem into the business realm, simply by restricting users/system(s) to read-only access for a brief period. Whilst this reduces the available functionality, it does ensure the switch doesn’t miss any vital state change transactions.
Long-running (bulk) jobs are also problematic. Many businesses these have long-running, yet time-sensitive tasks that may take hours to complete, may be bounded within a single enormous transaction (i.e. all-or-nothing), and can’t be procrastinated over (any payment-related action, for instance). Feel free to question the validity of this entire approach; not so much for the sake of Blue/Green, but for the sake of business resilience and dynamism.
What happens to the formally-LIVE (blue) environment? Well, the existing environment (blue) becomes dormant (it should not be immediately retired in case of rollback). At an appropriate time, we can do one of two things:
- Reuse it as the staging/proofing environment for the next release (where we switch from green back to blue). This may infer that we have long-running infrastructure that become a financial burden (depending upon the ephemeral qualities of the environment).
- (My preferred option) Destroy it, and once comfortable the new environment/deployment is correct and is stable, then recreate a new environment Just-in-Time (JIT).
THE INSURANCE POLICY
Blue/Green provides an insurance policy if things go awry, in the form of a simple, yet powerful, rollback strategy. At the most basic level, it’s achieved by reactivating the original (dormant) environment (blue in our previous examples), and switching traffic back to it (which is the reason for its dormancy, rather than its immediate destruction).
Let's say we’ve deployed our new product release to the green environment and routed all traffic to it. A few hours pass, and we begin to receive reports from users of a serious issue (it could be a bug, or a failing component). Identifying the root cause proves too abstruse to quickly resolve, but allowing the problem to continue could have serious business ramifications. Let’s see that in action.

Fault in Green Environment
Prior to the increased modern customer expectations on services and technology, the traditional solution to this problem may well have been to disable the entire service; something that benefits few. Luckily Blue/Green is to hand, and offers our users a service (albeit with a slight dip in functionality), by reverting back to our last known stable position on the dormant blue environment. See below.

Rollback to Blue Environment
That - in theory - is all that is required of us. It gives our users continued access to our services, and also give us breathing room to isolate and identify the real problem, resolve it, and then re-release the product.
And now for the caveat. Whilst all this is technically feasible, and doesn’t cause data integrity issues, it becomes much harder if it does. Which leads me on to the database.
THE DATABASE
The database makes for a far trickier opponent, mainly because it may be the first real stateful object to contend with.
The main problem with stateful data is that it can introduce layers of complexity. For instance, how do you ensure an entire system remains active and available whilst you switch and not lose any data, or create orphaned records and still enable a successful rollback strategy upon failure? Tricky eh?
In terms of rollback management, what do you do with all the data collected during the delta, between the execution of the original system and the execution of the new (broken) system, when you’re forced to revert it? You (probably) can’t roll out those transactions as it's an important representation of your current business state. And do those new transaction records contain state specific to the new change? Will they function with the old software?
TIME WAITS FOR NO MAN, AND NEITHER DO ROLLBACKS
The practicalities of undertaking a successful system rollback generally decreases over time. As data increasingly converges towards the new state (i.e. of the new system upgrade), reverting it becomes more technically challenging (and less appetising). Thus, the need for backwards-compatible, “non-breaking” changes.
I'm aware of two approaches to Blue/Green in databases:
- Single (shared) Database.
- Active/Passive Database Replication.
TECHNIQUE 1 - SINGLE DATABASE
Sharing the same database across both blue and green deployments is a valid approach that ensures data is retained and remains consistent. With this model you must ensure that the same data, structures, and constraints function regardless of the version of software accessing it. The advantage is that all data remains centralised, and there are slightly less moving parts than the alternative (discussed next). See the figure below.

Single Database
Typically, we achieve this by:
- Ensuring any dependency on the database is backwards-compatible with both versions of the software.
- Decoupling the database deployments from the reliant software deployments.
We change the database schema (assuming it’s structured) to function with both the existing and new software, and then deploy it (first) independently from the software it relies upon. With this model, we can be assured that the existing code functions with these new structural changes (our insurance policy), so we can now follow the database deployment up with our software upgrade.
At this stage, we have now upgraded both the database and the dependent software (i.e. our entire release). If things fail, we rollback the software, then determine how/if we need to clean up or migrate the newly captured data.
This approach is usually known as the Expand-Contract pattern. You expand the database model to support the new release, but don’t remove the dependencies required by the previous release, to then contract it later (by removing the original (unnecessary) database feature (structure/constraint/data)), once we have confirmed its stability.
TECHNIQUE 2 - BLUE/GREEN DATABASE REPLICAS
Database replication is another possible solution. And whilst it does offer increased Flexibility/Evolvability, it's a bit harder to manage than the shared single database model. See the figure below.
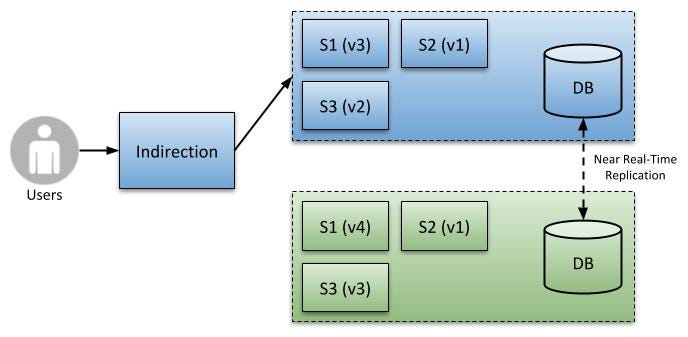
Database Replicas
In this model we maintain a stream of (data) change between the active and passive databases (some database vendors support near real-time replication). When the switch occurs, the active database becomes passive (read-only to our users), and vice-versa.
We still need to ensure we make structural changes (initially to the passive replica - which will soon become an active participant), which must still function on the current release, prior to the switch. Thus, the replication mechanism (rather than your software) must be smart enough to cater to the varying structural divergences of the two databases to perform an effective mirroring.
In the case of a rollback, we may make a full switch back to the original environment, both in terms of our software, and a return to the original database as our active one. However, replication should ensure data is not lost.
This all seems unnecessarily complex, so why might we use it? This approach can be invaluable to support innovation, security concerns, productivity, and systems evolution (Evolvability), as it enables us to undertake technology upgrades with a greater degree of confidence. For instance, say you’re currently on an older (unsupported and unpatched) version of a database, you may be able to upgrade a passive replica, check it functions, enable replication, then switch to make it the active database, whilst slowly retiring the unsupported version.
All of this depends upon one important Assumption - that all change can be replicated quickly from active to passive datatore. Any degradation in performance would hamper any Blue/Green-sensitive practice.
SUMMARY
There is a never-ending battle between the need for stability, and the desire for change (Stability v Change). Blue/Green is a powerful tool in our release arsenal, offering better stability, more predictable outcomes, a healthy innovation model, and a robust and efficient insurance policy (rollback and disaster recovery) should things go wrong.
Blue/Green enables us to evolve (upgrade) technologies (Evolvability) independently (e.g. to alleviate SECOPS), yet not persecute our users with unnecessary downtime or upgrade instability.
Blue/Green moves us beyond the difficulties and dangers of the historical deployment approach, which included:
- A technical expectation on the business that downtime is permissible (Tail Wagging the Dog).
- An implicit agreement that any users currently using the business services may create orphaned records/transactions and be subjected to a poor user experience.
- An expectation that it’s acceptable for a rollback to cause further (potentially significant) downtime.
- That it’s acceptable to verify the success of the deployment in a LIVE setting, whilst real users are also using it.
- That the environment (and its configuration) persists and is non-perishable.
- Fragile and expensive Big-Bang Releases, causing delivery procrastination, and creating further technical and business risk.
Whilst Blue/Green is - in the main - relatively easy to introduce; however, persistent state (i.e. databases) tend to be the one fly in the ointment, and need careful management.
FURTHER CONSIDERATIONS
CANARY RELEASES & A/B TESTING
If a (software) feature is just the materialisation of an idea, and some ideas hold more value, and are more successful than others, then how do you quickly identify ones worth pursuing versus ones to discard? Canary Releases and A/B Testing are two supporting practices to achieve this.
Any new feature has the ability to dazzle and excite customers; however, it may also frustrate, confuse, or disorientate them, or it might simply leave them detached. To compound the problem, we also find that unfinished features may frustrate some users due to their incomplete state, whilst others may see them as an opportunity (e.g. an efficiency improvement, or a way to beat the competition). The figure below represents what’s commonly referred to as the “innovation adoption lifecycle”. [1]
The diagram represents the willingness, and timeliness, of certain demographic groups to adopt an innovation (like a product, or a feature). Note how a significant proportion (34% + 34% = 68%) of the population aren’t drawn into a decision, and await feedback (are influenced) from the innovators and early adopters before finally committing to its adoption. This indicates the need to positively influence those innovators and early adopters, to in-turn, influence the majority.
It also divulges another key factor. Direct and immediate exposure of an untested feature (I mean untested in terms of its market value, not how rigorously the solution has been tested), to the entire customer base risks alienating an uncomfortably large proportion of those customers; something we must avoid. The trick is to engage (and learn) from the innovators and early adopters, whilst not alienating the more conservative (and significantly larger) customer base; enter Canary Releases and A/B Testing.
CANARY RELEASES & A/B TESTING
Coal mines are very hostile environments. Not only must miners contend with the dark, wet, and cramped conditions, they must also contend with toxic gases, such as carbon monoxide. In ages past, it was common practice for miners to be accompanied down the mine by a caged canary (a type of bird). The birds - being more susceptible to the hazardous conditions - provided a (rather cruel) form of alarm (i.e. an early warning system), alerting miners to potential danger, and allowing the aforesaid miner to exit the area poste-haste, prior to suffering the symptoms.
Canary Releases (and A/B Testing) apply this premise to the software world. They:
Canary Releases and A/B Testing are very similar concepts. Canaries tend to be about deploying and releasing multiple versions of a feature in parallel; possibly to limit exposure of potential bugs, possibly to promote the staged introduction of a feature to certain demographics. A/B Testing tends to focus more heavily on the usability/accessibility aspect (which often still need Canaries released to the back-end) and their impact on profitability; i.e. it allows the tactile aspects (ease of use, uptake etc) of software to be tested, in a controlled fashion, against real users, without necessarily introducing that change to everyone.
- Limit Blast Radius, by limiting who sees what, and when.
- Provide an alert to the controlling party indicating a potential problem, prior to it causing significant and unnecessary pain (see last point).
TRIALLING, WHILST LIMITING BLAST RADIUS
Canary Releases and A/B Testing limit Blast Radius, enabling the trialling of an idea (to prove/disprove a notion) to a subset of users, and provide a way to (gradually) increase its exposure to a greater number of users. Like a smart dimmer light-switch in some houses; turn it one way and you can increase the flow of light, brightening the room (i.e. in our case, increasing exposure to a greater number of users); turn it the other way, to reduce the flow of light and dim the room (i.e. reduce its exposure to users).
We do so by identifying trait(s) of certain users who we wish to treat (or serve) differently (it might be as simple as internal staff, to more complex scenarios, such as customers with specific tastes), then route requests for that demography to the untrialled feature (the idea), and gather useful business metrics to allow the business to decide next steps (thus, increasing the business’ Optionality). For instance, if we’re trialling a brand new unproven feature, we might start with internal staff, and any known “innovator groups”, and leave the remaining users (e.g. the early/late majority) to continue using their existing path, (potentially) no wiser to the new feature’s existence or capabilities (this is the prestidigitation virtue of these techniques).
Consider the following example. Your business sells a highly-capable software product that has already been well-received by existing customers. However, research from your product team has indicated a potential improvement to an existing (popular) feature that should entice more customers to your product. How should we prove this theory?
FUNCTION AND NON-FUNCTIONAL CHANGE
Note that whilst I’ve presented a functional change in this case, it need not be. For instance, introducing a small subset of users to a new user experience is a good example of A/B Testing, where we trial the more tactile aspects of software - rather than introducing new functions - to gauge user uptake. It could also (for example) be trialling an improved runtime algorithm that - whilst doesn’t affect user functionality - might offer a distinct performance (and therefore OpEx) improvement.
To be clear, this is a form of bet. Let’s say we don’t apply the Principle of Status Quo, and simply replace the existing feature with the new (supposedly improved) implementation; i.e. no Canary, A/B Testing, or Feature Flags. We may have several different outcomes:
- The feature is a roaring success; both existing and new customer’s love it. In this case we’ve saved ourselves a bit of time and unnecessary work.
- The feature gains no traction with new customers, but is somewhat successful with existing customers. We need to decide if the ROI justifies further work.
- The feature gains no traction with new customers and frustrates existing customers, and should be immediately dropped.
- The feature infuriates your existing customer base, who leave in droves. Maybe you and your customers idea of progress are not the same?
Surely, it’s not worth the risk? Instead, let’s be a bit more strategic and follow this release strategy to the following groups:
- Internal technical group. Identify glaring deficiencies and immediately resolve.
- Internal customers; e.g. the executive and product teams. Try it out and suggest minor improvements prior to launching to first external prospective customers.
- Small group of prospective customers. We want to engage with this group to (hopefully) buy our product.
- Small group of (specifically selected) existing customers. Possibly the ones you are most concerned about losing. Note that if the customer is another organisation, it’s feasible to only show the change to a (trusted) subgroup of their users.
- Everyone else.
In this case we’re applying Circle of Influence; i.e. with each concentric (outer) ring we slowly increase the scope of a feature’s visibility (it’s influence) to customers, until (hopefully) everyone gets it. See below.
In this case, Level 1 influence (internal IT staff in our example) offers less exposure than Level 2 influence (execs and product staff), and so on (you can have as many concentric circles as you think wise). Level 5 influence indicates everyone gets access to said feature. Full exposure to everyone may only take a matter of minutes, or it may take months (although this presents its own challenges); however, until everyone receives that feature, we will find that some users receive a different (functional) experience. We can pause and reflect at any point (say, at stage 2 in the above circle), if we identify a problem, want to improve it, or find our bet isn’t paying off.
SUMMARY
Why do this? One of Waterfall’s biggest failings is that it’s big bang. That’s fine if you get it right the first time, and don’t anticipate significant product evolution, but that’s rarely how life works. We try something out, we show it to others, they offer feedback, and we stop, expand the circle of influence, or iterate again; i.e. we’re refining all the time.
Techniques like Canary Releases and A/B Testing are a form of insurance, enabling us to limit Blast Radius, and “hedge our bets”, thus, protecting our brand, and enabling us to innovate with a Safety Net. However, these techniques can also introduce additional complexity (such as Manageability), and confusion in areas such as customer service support (e.g. customerA has indicated a problem, but what features were they presented with?).
FURTHER CONSIDERATIONS
DEPLOYMENT PIPELINES
At a basic level, Deployment Pipelines are a mechanism used to deliver value to customers regularly, repeatedly, and reliably. However, before discussing how they do it, it’s first important to know why they exist.
WHY DEPLOYMENT PIPELINES?
The distribution of software to customers has - historically - been fraught with challenge. (Relatively) modern approaches (e.g. distributed architectures) weren’t yet widely practiced, and many applications were monolithic in nature (Monolith), which tended to promote large-scale, irregular, monolithic deployments (Atomic Releases) that introduced variability, Circumvention, and uncertainty. Large releases were just as much about managing fear as delivering value, so quite naturally, we undertook them less.
Business, technology, and consumerism (in the consumption of business services) has progressed rapidly since then, in a few ways:
- The triad of technology, platform, and people (Technology, Platform, and People Triad) - a self-perpetuating feedback model that has driven expectations, and therefore Ravenous Consumption.
- Ravenous Consumption has created a monster in that the distribution and consumption of software has assumed far greater import. In essence, we are the victims of our own success - we’ve inculcated rapid change upon our consumers to such an extent that it’s now expected of us all - yet many are unprepared for it. What consumers found acceptable only a few decades ago is no longer so.
Businesses not only want to innovate, they must in order to survive. The key to this is two-fold:
- They must build the right type of value, quickly.
- They must find ways to deliver value to the market quickly - either to shape an idea, or to discard it. This requires a delivery mechanism; i.e. Deployment Pipelines.
THE FIRE OF INNOVATION
Out of the fire of innovation came Microservices (a backlash against brittle, slow to change/evolve life-cycles), Agile (a backlash against the established norm, and high-risk projects typical of using the Waterfall methodology), Continuous practices (a backlash against risky Lengthy Release Cycles, Atomic Releases, and stunted learning), and a greater focus on test automation (a backlash against slow and onerous tasks, with poor feedback and limitations on innovation). There’s a general trend toward small, incremental change, over large deliveries.
Most of these techniques have been driven by need. Ravenous Consumption has driven business, and therefore technology (through the Triad), to find solutions to its problems. Deployment Pipelines provide one such solution.
Divergence is - in this case - the enemy. Whilst divergence may suit innovation, it fails to establish a common standard of adoption (it’s no longer divergent by then), particularly across established businesses. In this case, it is preferable to align a suite of business services around one common, reusable approach, which is shareable and exoteric, over bleeding-edge and esoteric. Uniformity is key to deliver quickly, regularly, and reliably for a wide array of different business services.
THE RISE OF RELEASE MANAGEMENT
The prevalence of distributed architectures (e.g. Microservices) has also influenced release management. For instance, supporting independent software units is of limited value if they are still released in a single Big Bang Atomic Release.
Aligning a release management mechanism - like Deployment Pipelines - alongside Microservices and Continuous Practices helps to allay some of these concerns.
Deployment Pipelines are a means of delivering:
- Fast, yet reliable, TTM, across multiple environments.
- Shift Left principles. For instance, by placing less reliance upon Operations staff to manage deployments (by employing Uniformity), or by increasing support for the automation of testing (typically a late activity in a software release cycle).
- Fast Integration and Fail Fast. Teams encounter integration issues, or other failures, sooner rather than later. Code is kept in a healthy, releasable state at all times.
- Uniformity. There’s a consistency and commonality across all Deployment Pipelines, creating a shared, transferable understanding within a business (and indeed, across the industry). Pipeline uniformity also reduces faults through their repeatability, regardless of the environment.
- Fast Feedback/Fast Learning. Getting to the market sooner (due in part to Deployment Pipelines) enables businesses to more quickly gauge a feature’s success, and pivot as appropriate. This incremental delivery also reduces waste (better ROI), and focuses us to “do the right thing, over the thing right.”
- Safety Net. Executing a pipeline is fast, inexpensive, and is typically automated (e.g. Git web-hooks), so it's performed more often. This promotes greater experimentation, and thus, innovation.
- Greater team ownership and accountability. Deployment Pipelines helps negate the need for a centralised release team/management (which can be one source of bottleneck), in favour of a small, multi-skilled unit (Cross-Functional Teams) to manage the entire lifecycle of a solution. This promotes faster failure identification and resolution.
PIPELINES
A change typically has two release aspects:
- Check the stability, quality (e.g. gather source code quality metrics), and the functional accuracy of the source code being transformed into a software artefact. This should be done once per release. The output is typically a packaged software artefact (if successful), which is stored for future retrieval.
- Deploy the software artefact to an environment for actual use. Depending upon the (environmental) context, this may include verifying it meets all desired traits (i.e. functional and non-functional). This deployment process is (typically) repeated per environment, using a gated “daisy-chaining” approach. A release only progresses to the next stage if it succeeds in its predecessor.
TWELVE FACTORS - SEPARATE BUILD & RUN STAGES
One of the twelve factors (Twelve Factors) is to formally separate the build and run stages. This approach helps to:
- Minimise Assumptions. There’s very focused (cohesive) stages, only making sufficient Assumptions to complete its specialised responsibility.
- Improves Flexibility and Reuse. Finer grained pipelines can be combined and reused in a wider variety of ways.
- Fast rollback management. If the current release version fails a deployment, we simply ask the release pipeline to revert back to a previously known good state (release version).
- Pressurise Circumvention. Circumvention can create variability, and thus inconsistencies - something we discourage to create repeatability. Pipelines place great emphasis on repeatability, making it easier to do the right thing, than to circumvent the process.
MANUAL INTERVENTION
Note that whilst I’ll assume some form of autonomous process exists to identify change (e.g. Git web-hook) in order to release it - it need not be. A developer can initiate a build/deploy manually, using exactly the same pipelines that support autonomous execution.
Let’s visit the two stages next.
THE BUILD PIPELINE
In the build stage, changes to the source code are committed into version control (e.g. Git), where they are subsequently pulled and packaged into some form of executable software artefact (depending upon the underlying technology).
Typical steps include:
- Developer commits changes to version control.
- A web-hook is initiated automatically.
- Source code is “pulled” from version control.
- Source code is compiled (not all languages require this stage).
- Unit tests are executed. Unit testing is performed to ensure code exhibits certain qualities, standards, stakeholder expectations. It is also used to catch failures early.
- Quality analysis. We may perform static code analysis to check for common flaws/errors, ensure it meets agreed coding standards, and that it doesn’t introduce any known security vulnerabilities.
- Create/package the software into an artefact (if appropriate). Typical examples are .exe/.dll/.jar/.war file types.
- Store the artefact (if appropriate) for future deployment (e.g. Artifactory/Nexus), and assign it a unique identifier (for later retrieval). Note that this artefact is immutable - any new change to the source code requires the creation of a new artefact version (this also protects against Circumvention); i.e. we repeat this entire pipeline.
A typical build pipeline resembles the following diagram (assume the source code commit has already occurred).
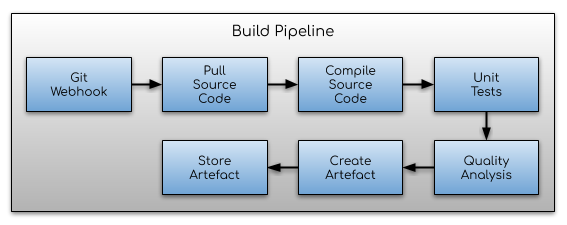
This pipeline should only be executed once. The output of this stage is to have a pre-checked, immutable, software artefact that can be deployed and executed.
Why should we only execute this pipeline once per release? For two reasons:
- It introduces an unnecessary element of (chaotic) risk to something that must (to be given any credence) be repeatable.
- It slows delivery (TTM), by increasing build time.
It’s quite possible to rebuild the same source code, yet get different results, and thus, inconsistent artefacts. This is dangerous. In the main, there are two causes:
- It is the result of stating implicit (rather than explicit) platform, build package, or third-party library dependencies, that change in the timeframe between initial build and the final production release.
- Someone, or something, has changed an explicit dependency (that you depend upon) in the timeframe between initial build and final production release.
Let’s say you don’t follow the immutable approach, and it results in inconsistencies. You may expend significant effort in acceptance/regression testing within the test environment, yet it fails unexpectedly to deploy into a production environment (your testing is therefore pretty worthless). The testers argue (quite rightly) that it’s been thoroughly tested so should work in production (and surely you’re not going to run the same regression across every environment?). Others might argue that it’s an inconsistency in the production deployment pipeline (incorrect in this case). You end up chasing your tail, wasting crucial time looking into deployment issues, when its root cause are the vagaries of an inconsistent build strategy.
SINGLE-TIME BUILDS ARE A MEASURE OF CONFIDENCE
By executing the build stage once (and only once) per release, we gain confidence in the artefact’s consistency across all deployments, which is then stored for future deployment. You can’t do this with the mutable alternative.
THE DEPLOY PIPELINE
A second pipeline, which depends upon the output of the first (build) pipeline, manages the deployment of the software artefact(s) to an appropriate environment(s), and thus, exhibits more runtime characteristics.
Typical steps include:
- Pull artefact for deployment.
- Deploy to the environment.
- Configure the software appropriate to that environment.
- Start up the process(es).
- Run Acceptance Testing (if appropriate). Execute user journey tests to confirm the software functions as expected.
- Run Load Testing (if appropriate).
- Run Penetration Testing, or other security testing.
A typical deployment pipeline resembles the following diagram.
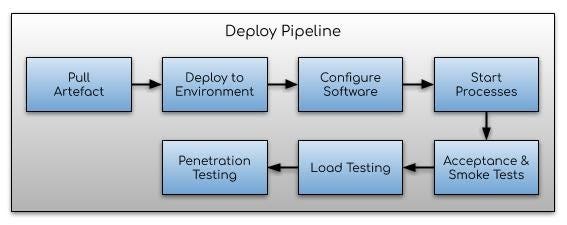
This pipeline may be executed many times, but typically once per environment (e.g. testing, staging, production). Any pre-production failure will halt the entire pipeline from proceeding (much like you would with an Andon Cord), where a “root-cause analysis” can be undertaken.
Note that some of these steps may not be performed across all environments. For instance, it may be impractical to execute performance or penetration tests in a production environment as it may skew business results (e.g. test results should definitely not be included in a business’ financial health calculations), or contradict security policies. You may also choose to undertake manual exploratory testing in a test environment - something you probably wouldn’t do in production.
APPROVAL GATES
Tools like Jenkins provide “approval gates” (typically through plugins) between stages (or environments) to ensure key parts of a pipeline only progress after manual intervention. Gates are useful if you don’t need (or aren’t ready for) continuous flow, or if it’s desirable to have specific roles (e.g. product owners) to coordinate releases with users.
FURTHER CONSIDERATIONS
- Continuous Delivery
- Assumptions
- Uniformity
- Jenkins - https://jenkins.io
- Big Bang Release
- Lengthy Release Cycles
- Circumvention
- Microservices
- The Triad of Technology, Platform & People
- Ravenous Consumption
- Agile / Waterfall
- Twelve Factors
- Fail Fast
- Cross-Functional Teams
- Safety Net
- Andon Cord
ANDON CORD
Like many other products, software is manufactured over a series of steps within a manufacturing process (Value Stream). Ideally, every single step adds value and is accurate - i.e. the work is done to an acceptable standard, and doesn't contain defects. In reality though, this isn't always practical.
Even for those with the most robust processes, defects will sometimes creep in. Defects are a form of Waste (the Seven Wastes). They lead to disruption and Rework (another form of Waste), and therefore to poorer TTM and ROI. There's a cost to resolving the issue, and a cost of not doing the thing you were meant to be doing (a form of Expediting - in this case to resolve quality problems for an existing product). We also know that the sooner a defect is identified and fixed, the cheaper it is [1]. This acts as a nice segue into the Andon Cord.
At the heart of it, an Andon Cord is a mechanism to protect quality. It prevents further Contagion within a manufacturing process. When a problem or defect is encountered, the Andon Cord is “pulled”, work stops (at least on the offending work station and those preceding it), the issue is swarmed, and an appropriate resolution is implemented (which may be a workaround until a more permanent solution is constructed) to allow the manufacturing process to continue.
To some readers, this approach may seem heavy-handed and radical; to me though, it's pretty logical. Rather than continuing to produce a substandard, or defective product, derided by customers or industry watchdogs, work is stopped until a good resolution is found. It's the ultimate form of system-level thinking. Value isn't solely about how a product is manufactured, it's also about how the business is perceived (Reputation), the potential impact to sales, and its customer care.
SYSTEM-LEVEL THINKING
There's a direct line between the quality of your product, your Reputation, and thus, more sales. This is why isolated working or thinking is dangerous.
Let's now complicate matters further by throwing Automation into the mix. Automation is a Change Amplifier - i.e. over the same duration, it makes more change possible - sometimes in the orders of magnitude - than its manual counterpart. As such, it must also amplify (and thus exacerbate) any defects introduced into that system. Consequently, the more defective work you do, the more defects you must contend with, and the harder it is to resolve (like the Magic Porridge Pot [2]). The Andon Cord makes good sense in such circumstances.
FURTHER CONSIDERATIONS