Resilience
RESILIENCE
| TTM | ROI | Sellability | Agility | Reputation |
A system's ability to cope well with failure and reassert itself.
Resilience is the other half of Reliability, and close conspiracist to Availability. Whilst Availability relates to the system's ability to remain available to service requests, Resilience relates to how well a system copes with failure (or, how a system copes with adversity). Resilience then is partially about preventing a failure, but mainly about limiting the impact of a failure when it occurs.
ETYMOLOGY
The word “resilience” originates from the Latin for: “leap or spring back; recoil; rebound”.
FORMS OF RESILIENCE
As described here, I consider there to be two forms of Resilience:
- Runtime Resilience - often caused by environmental factors that are transient and outside of our control, but also by poor quality.
- Release Resilience - typically caused by ourselves, due to poor project management or delivery practices, a large Blast Radius, or incorrect Assumptions.
For many, the last two decades have witnessed a dramatic shift away from the expectation (nay, the demand) of always available systems, to one where we stand more willing to accept (the occasional) failure [1]. At first glance, this seems paradoxical. Why would we intentionally choose to accept more failures? We want fewer, not more, surely? In order to understand that, we must first understand our past. You can find out more here (How We Got Here).
Put simply, without some compensating factors, a greater quantity of change (as we've witnessed over the last two decades, caused by changing consumer habits) equates to an increased risk of failure. Without modifying our thinking and behaviour - from requirements gathering through to the operation of our software - it would have been impossible to drive through such rapid change. But it also caused us to adopt different habits (and views) towards failure. We became more tolerant of failure, assuming that we could quickly resolve it. Resilience then, has become more prominent.
LOCUS OF CONTROL
One (relatively nascent) idea gaining traction is our perception of control of complex systems (whether they be economic, technical, political, or something else); i.e. our locus of control. This is an extremely interesting area of study and is already having consequences on how we design our systems of the future.
The premise of Locus of Control revolves around the chimeric notion that we are able to control a Complex System. Whilst we invest heavily into preventative recourse, applying layer after layer of controls, in order to supposedly control a complex system, what we're doing is exacerbating any future problem through more rigid coupling, to the point that when a problem does (eventually) occur (we can't control every eventuality), it is far worse than it might have been.
Whilst we should always have Table Stakes in place (e.g. testability), it's sometimes prudent to allow a problem to occur rather than introduce further controls, and demonstrate Resilience through swift resolution.
A key measure of Availability is a system's mean-time-to-recovery (MTTR). A poor MTTR negatively affects availability, creating a range of technical and business problems. You may have read about some airlines, banks, and electronics businesses suffering from the (financial and reputational) consequences of an unexpected, lengthy downtime. This suggests poor technical or operational Resilience - a system or business function is unable to rebound in an acceptable time frame.
CRITICAL INFRASTRUCTURE RESILIENCE
The National Infrastructure Advisory Council (2009, 8) defines critical infrastructure resilience as: “…the ability to reduce the magnitude and/or duration of disruptive events. The effectiveness of a resilient infrastructure or enterprise depends upon its ability to anticipate, absorb, adapt to, and/or rapidly recover from a potentially disruptive event.”
We need systems and processes that are swift to recover, and are (preferably) autonomic. We can meet this objective through the use of a wide range of technologies, techniques, platforms, and organisational approaches, some of which I present below.
CHARACTERISTICS
The main characteristics that support Resilience are shown below.
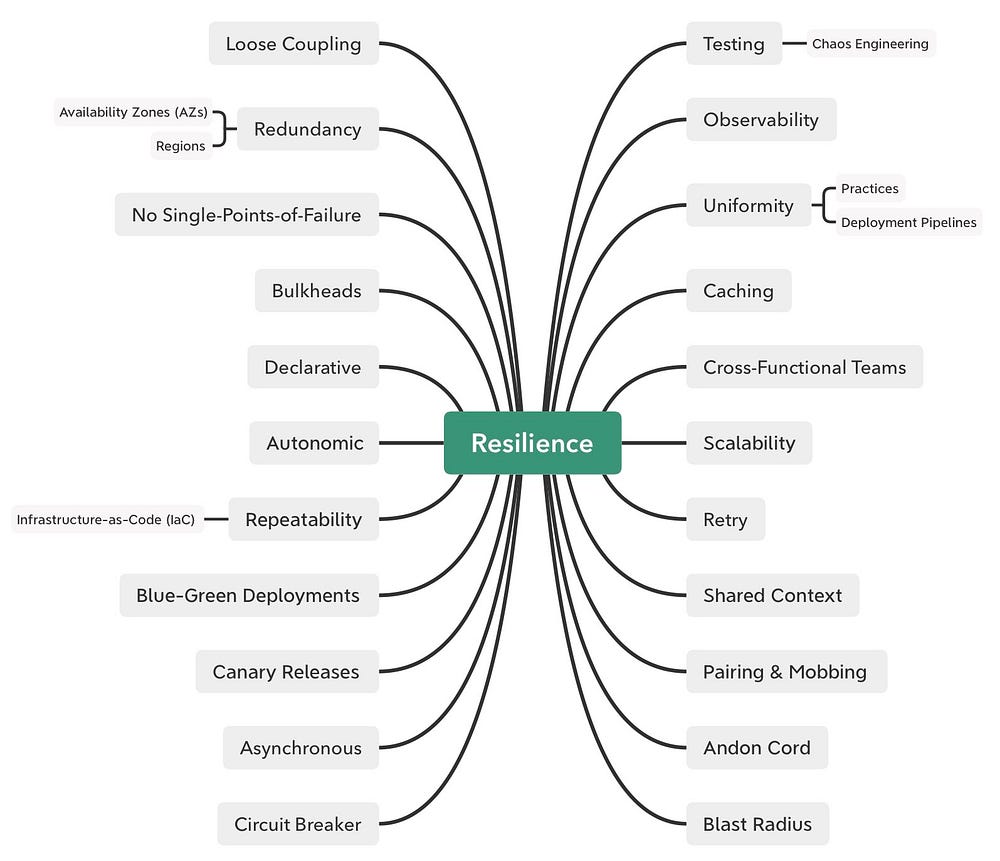
These characteristics also feed into other important areas - like applications architecture and runtime platforms - some of which I'll be discussing in other chapters. See Resilience - Solution Mappings for resilience solutions.
PILLARS AFFECTED
SELLABILITY
A solution (or, more likely, a business) that is known to have suffered from a significant outage has resilience challenges. These issues may be publicised and therefore available for prospective customers to view. This may impede sales.
REPUTATION
The longer a system remains unavailable, the greater the potential harm it does to your business. The ability to recover from failure is Resilience.
The impact of a failure (and thus Reputation) depends upon many factors, including: the type of service offering, the type of customers, time-sensitivity (e.g. stock market transactions have a short lifespan), and customer impact (e.g. do they lose money, or time, or something else precious to them?).
SUMMARY
Resilience relates to how well we (our systems, or business) react to failure. The greater our ability to resolve (or prevent) failure, the stronger our Reputation is likely to be. However, also be aware that not all systems need excellent resilience. It could be that your users are willing to accept some product instabilities if - for example - they get the service for free, or the information it contains isn't crucial.
Resilience has taken on greater importance as we have become more tolerant towards (short-term) failure. This was necessary to cater to the industry's consistent drive towards faster (and faster) change.
Resilience may be affected by several other qualities, including Availability (e.g. the solution has no redundancy, causing a lengthier outage), Scalability (e.g. a large event causing systems to fail when flooded with legitimate requests), Uniformity (e.g. too diverse a technology ecosystem, causing a lack of Shared Context), and Security (e.g. a Denial-of-Service causing an outage).
Resilience need not be technical; e.g. it may also be operational. A team that can't access the tools necessary to restart a service, or who rely upon a single person who is no longer around also has resilience challenges.
FURTHER CONSIDERATIONS
- [1] - Obviously it's not true of everyone. Some systems demand extremely high availability so don't see rapid change of the ilk in modern web-based solutions.
- Complex System
- Denial-of-Service
- How We Got Here
- Resilience - Solution Mappings
- Shared Context
- Table Stakes