Monoliths
<< Previous - Sellability | Table of Contents | Next >> - Brand Reputation
MONOLITHS
Recommended Reads: How We Got Here
Monoliths, within the software context, have been around for a long time, and until relatively recently, were the mainstay of most companies. Fundamentally, it's a centralised application - the converse of a Distributed Application - that retains controlling oversight over all of its constituents. The diagram below uses Mass Synergy's e-tailer domain to demonstrate a monolithic application.
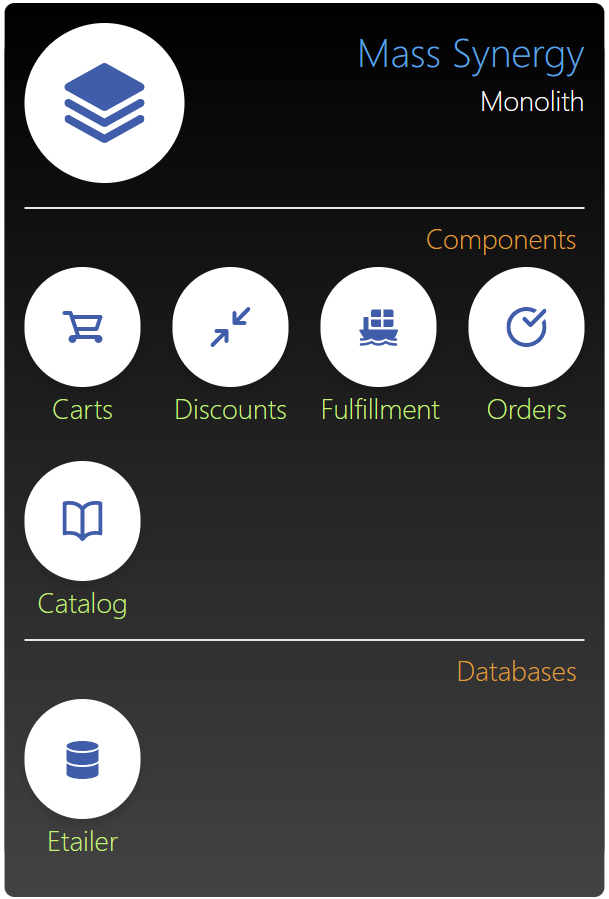
In this particular (Mass Synergy) example, I've captured five distinct domains: Carts, Discounts, Fulfillment, Orders, and Catalog [1]. Each domain encapsulates a specific responsibility. As I say, this is purely for demonstration purposes - most monoliths I've seen tend to have many more embedded domains.
Let's discuss the monolith's key characteristics, before moving onto its good and bad points. Firstly, note that the entire solution is contained within a single unit. This is what's meant by a centralised model - the unit contains everything needed for that application. They may be logically contained in multiple distinct domains (e.g. Discounts), but they're still packaged, deployed, and released as a single executable unit. Typically, this approach is also applied to the monolithic database; i.e. it's a single (database) unit, consisting of multiple domains.
The next logical point might be to discuss how change is handled within a monolith. Again, due to the centralised model, all change is managed through a single, centralised codebase, of which we'll talk through the consequences shortly.
What about communication between each domain? How does that work? Let's examine it using a (simplified) cart checkout workflow. See below.
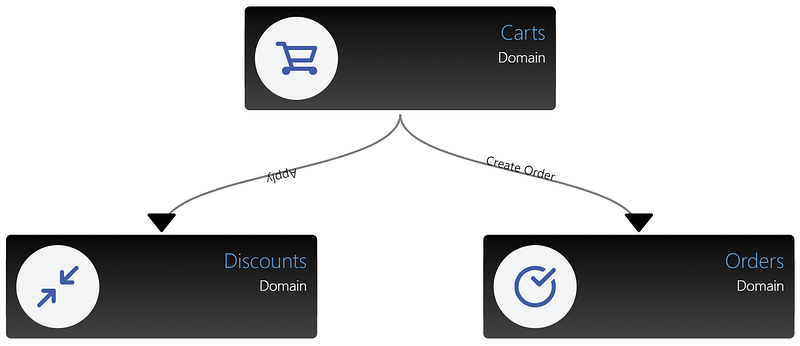
When a customer checks out their cart, it initiates a local workflow, from the Carts domain, through to Discounts, back to Carts, and then on to Orders. In general, the communication is contained within the single executable unit (the monolith), and therefore runs in the same runtime process [2]. To reiterate, it assumes all communication is local to that host (physical or virtual).
Let's now discuss the good and bad aspects of the monolith.
THE GOOD
Let's start with the good points. Firstly, there's Productivity. Monoliths can - at least initially - offer a highly efficient way to work, albeit, this comes with a significant caveat emptor [3]. Working with a single (small-ish) codebase suggests a low cognitive overhead, where things are pretty easy to find and there's no need to discover (or retrieve) other parts of an application to get a more holistic view. You get it all. This can also promote Maintainability - e.g. it's easy to find things. Debugging, tracing, and logging - all important parts of problem diagnosis - are also straightforward, since everything runs in the same process, or is centrally located.
Manageability is both better and worse. Good in the sense that there's only a single executable (packaging is simple) and deployment. A single package manifest can build the code, gather dependencies, and package up the entire application. Again, when it's relatively small, that makes for low cognitive overhead and is also a good way to distribute a product to other parties for self-management.
Performance is also (generally) good. If you recall, the saying: “Every performance problem in computer science can be solved by removing a layer” [4] suggests that reducing the number of layers improves Performance. There's no network latency concerns (the Principle of Locality), making requests fast. Monolithic database performance has similar characteristics. Where everything is local, and is treated as local (e.g. SQL table joins), you get good performance, but only to a point.
IN NORMAL CIRCUMSTANCES
Performance tends to be better in a centralised system (but not necessarily scale, which I'll cover later) assuming normal working circumstances - i.e. it's not under duress. Which seems entirely logical. To analogise, if you're entirely dependent upon yourself for everything, and you're overworked, who else can help? No one. It's the same principle with monoliths.
The benefits of localized communications don't just lie with Performance. The implication of no (or very low) network interaction - a common source of failure - is that we needn't concern ourselves with network failures [5], promoting (runtime) Resilience.
With respect to Availability, the local communication assumption means that once a request reaches a monolith, its outcome is determined solely by that monolithic instance. Once a request breaches the monolith's perimeter, nothing else can process it. In normal circumstances this isn't a problem - requests will be successfully processed and returned to the caller. But consider what happens when the system is under duress. We're at the whims of the Monolith - if it's slow, or fails (e.g. due to poor Scalability), then all requests that have entered may be lost, and Availability - in these circumstances - is quite poor. It's highly available until it's under duress, at which point it's not. To analogise, imagine the monolith is a bar where you've agreed to meet your friends for a few drinks. When the bar is quiet, it's easy to gain access; you can easily find your friends, and service is quick. However, consider what happens when the bar is overcrowded - you'll either be denied entry (turned away at the door), decide against it when you see the queue, or you'll gain entry but be unable to move (let alone find your friends).
UNDER DURESS
This point on duress is quite important. Reliability - in the everyday sense of the world - means you can rely upon the outcome; it's predictable. But how can you rely upon such an outcome, which is either highly available when the system isn't under stress, or suffers from poor availability when it is? It's a bit of a gamble, isn't it?
Whilst distributed systems aren't without challenge, one could argue that availability could be made more predictable. Whenever our systems face duress, we add more workers. Of course it's rarely that simple [6].
Transaction management also fits in nicely here. Monoliths typically offer the ACID properties: transactions are Atomic, Consistent, Isolated, and Durable. That's Immediate Consistency (Consistency), meaning every part is immediately in sync with the others. Purely from a Resilience perspective, we get a simple, in-built rollback mechanism for failing transactions. You don't get that with Distributed Systems.
THE BAD
There's a reason why, nowadays, distributed systems tend to find favour over monoliths. You're now about to find out why. Recall from an earlier section (How We Got Here?) that modern businesses have very different commercial constraints, options, markets, and customers than those of several decades ago. The Internet, Social Media, Web Services, Globalisation, and Ravenous Consumption have largely put paid to huge, lengthy, and slow change releases. Customers expect more, and sooner; they also have many more avenues to complain (i.e. affect your reputation).
THE ESTABLISHMENT
Being an established business in these circumstances may be viewed as both a blessing and a curse. A blessing, since you've already proved yourself and your product or service, and (hopefully) have steady custom. A curse, in the sense that you may now have technologies and a culture embroiled in a form of stasis, unfit to meet today's challenges.
Earlier, you may recall that I placed caveats on some of the Monoliths benefits of the ilk: “unless under duress”. Certainly, a Monolith can offer good Performance, (runtime) Resilience, Observability, and Availability when it's healthy, but it's up for grabs when it's not. At some point, many of these advantages turn sour. It's easier to maintain, until it's not. It's easier to debug, until it's not. It's more available, until it's not. You get the picture. So, if it's not always dependable (at all times, in all circumstances), is it really any more predictable than its distributed cousin?
There's lots to consider here, but let's start by talking about the monolithic codebase. A single, centralised codebase is great when it's relatively small, and not overly complex. But most businesses don't operate like that. At some point an event horizon is reached, making a monolithic codebase a burden, not a benefit, and also bleeds into aspects of Maintainability, discovery, change isolation, and Complexity - albeit it's a different type of complexity than a distributed system (i.e. the complexity of combining many disparate services); it's a centralised complexity within the codebase.
Fast Feedback is another concern. I vividly remember waiting twenty minutes to build, deploy, and test a simple change to a monolith. That's terribly slow feedback, and generates batching, leading to higher risk, and a lower Innovation potential.
Assumptions are in plentiful supply within a monolithic codebase. The larger it is, the more assumptions it contains. From my experience, more assumptions equates to greater Change Friction. Therefore, a large, tightly-coupled, codebase makes evolution difficult, mainly because it's difficult to isolate and decompose large changes. What should be a simple upgrade is no longer so.
Monoliths are generally built in a single technology stack (or runtime platform). This creates a lack of Agility. For instance, if you begin with Java, then you're probably using Java (or its runtime platform) forever more; not .NET, Node, or whatever else is around the corner. This is rather unforgiving and parochial. Technology evolves, and does so rapidly. What happens when better options arrive, or when one feature is better suited to a different technology?
Let's switch gears now and discuss change speed (i.e. TTM). Most Monolithic applications I've come across don't promote rapid (business) change. This is the consequence of centralisation, and its (relative) poor change isolation. Recall that a monolith is a single deployed entity containing everything it needs - you can't isolate even the smallest change from the deployed unit. That implies holistic change, regardless of whether that particular area has actually changed. You can't guarantee that your small change hasn't unexpectedly affected some other part of the monolith - thus requiring a level of Regression Testing on it.
The overall slowness of change - the result of poor isolation - also creates other problems, including: lots of change (i.e. batching of changes), slow release cycles, long test cycles, the Waterfall Methodology, and slow feedback (Fast Feedback). That all equates to Change Friction. Think of it like this. If I don't touch a software component, then I can be pretty confident it will still function as it did before. That breeds confidence. But I don't get that same level of confidence with a monolith. There's a possibility that I've polluted it, which means I must test more rigorously (higher regression), and consequently - due to batching - that probably means more Waiting.
UNIT TESTING
Testing the monolith isn't necessarily harder (than a microservice) from the unit level perspective [7], but it most certainly is from a release testing respect. The slow release cycles incentivises large batches of change, and combined with the poor isolation, creates additional regression effort.
MONOLITHS & WATERFALL
For me, the main issues with the Waterfall methodology (a common partner to monoliths) are:
- There's a hand-off mentality that leads to a greater loss of Shared Context.
- It's harder to reorganise and reallocate staff if issues are identified, thus we tend to batch changes.
- Larger releases are better at hiding quality issues.
- It's (generally) more risky.
It's hard to estimate or predict something that contains many changes. It contains more assumptions, and therefore greater risk, thus more things don't go to plan. That forces you to reassess your timelines against everything that you must do, and everything you should do. Inevitably, the "shoulds" (e.g. load testing, robust security testing, or documentation) get neglected, and are circumvented. Of course the next big project comes along and follows a similar trajectory. Over time, those missed "shoulds" add up, and then become business "musts", but by then, it's too late. Perhaps unsurprisingly, we also find that Expediting is more likely to occur when the scope of change is large, there's plenty of Waiting, and a general delivery lethargy (Lengthy Releases). Consider it like so - if something is stuck in the same place (e.g. in the test environment) for a long time, another work item is bound to come calling.
Domain Pollution is another concern I see time-and-again with monoliths, with the pollution here being one domain's responsibilities bleeding into another (unconnected) domain, mainly because it's easier for engineers to do this than the alternative (use Encapsulation and only allow access through interfaces [8]). This can create a range of problems, including our ability to scale, evolve, or organize ourselves (team structure).
Let's face it, non-functional, technological change doesn't always receive the same level of business prioritisation that features do. Take Upgrade Procrastination as a case in point. I find monoliths create Upgrade Procrastination - we procrastinate on its modernisation because this type of change is hard [9]. Over time, the consequences then bleed into Evolvability and Security - it becomes increasingly difficult to evolve or secure the application due to the Blast Radius. Ideally, upgrade work is (almost) seamless. There's no conscious decision to undertake it by the business, it just happens naturally.
The other upgrade aspect is product modernisation. I've seen businesses repeat the cycle of: build a monolith, use it, find that it's aged badly, build another monolith (initially containing a subset of the first monolith's feature, but with the intention of retiring the original), sell the new monolith, but never fully migrate all of the original customers onto the latest monolith. Cycle repeats again a few years later, ad infinitum. You've just massively increased the complexity, maintenance, and management costs of your estate, exacerbated when regulatory change hits all of it. It's best avoided.
Monolithic Manageability is more of a gray area. I think it's harder to configure a monolith (than a distributed component), since its configuration is also centralised, thus containing everything, yet only a small number of changes are relevant to your release. But, if you'll recall, monoliths tend to scale vertically (discussed shortly), there's no complex network configuration, or load balancing (at least within the monolith), and there's generally fewer of them in an estate, making them easy to discover and manage from that perspective.
In terms of Security, it's a mixed bag. It's easier to manage the security of a single boundary than a vast sprawling estate since we're guarding fewer gateways, but it's too easy to circumvent the Principle of Least Privilege, and the impact of Upgrade Procrastination is also concerning. There's also the potential for higher Contagion should the monolith's boundary be breached - if they get into the database, there's a good chance they can access anything in it.
Whilst the monolith's Scalability approach is indeed vertical, it's too narrow a distinction. It's quite feasible to horizontally scale an application architecture containing monoliths (note the distinction), by directing traffic to each monolithic instance through an intermediate (e.g. a Load Balancer). Ultimately though, you're still dealing with applications using a centralised model.
SUMMARY
It may at times have felt like I'm giving the monolith a bit of a bashing, but there's some good in there too. Overall Monoliths can be a good option when starting out, domain complexity isn't overwhelming, immediate consistency is important, the engineering team has rigorous processes, or it's the sort of workload that requires the Principle of Locality. At some point though, complexity starts to erode its benefits, and something else is required.
In terms of runtime qualities, we've a mixed bag. Performance, Availability, Resilience, and Scalability are decent, but only to a point, and therefore unpredictable. But then again, is it easy to predict how network communication behaves in a distributed environment?
Nowadays, there's a big push for distributed systems (e.g. Microservices, Serverless) throughout our industry, but it's not all one way [10]. Replacing a Monolith with Microservices offers certain advantages, but it moves complexity (code and release complexity with networks and infrastructure complexity), it doesn't remove it.
FURTHER CONSIDERATIONS
- [1] - Of course, this varies widely across industry and business.
- [2] - Albeit there's nothing preventing a monolith from calling services outside of its centralised boundary. If you're using any remote services - such as partner services - then you're not performing local calls, and therefore have to deal with the consequences - e.g. network failures, eventual consistency.
- [3] - Caveat emptor. It's only productive up to a point, and then it becomes increasingly unproductive. The trick is realising when it's benefits are no longer available.
- [4] - The statement relates to removing layers to improve performance. Of course localized interactions also have layers, but they're local, so don't have the same performance implications of distributed remote interactions.
- [5] - This is purely runtime resilience I'm describing here, not change resilience.
- [6] - The network gets in the way. So whilst you could add more services to increase availability, the downside is the reliance on a network that is far more likely to fail than a local interaction.
- [7] - Although I've certainly seen “God Controller” classes that have made it improbable, and seen terrible test running times, another sign of poor isolation.
- [8] - Unless domain boundaries are maintained.
- [9] - Recall that all of the monolith assumes (coupled) a single platform, middleware, and version. That's a very broad assumption. You upgrade it all, or nothing. Tie that with the extended timelines and regression effort and you get a recipe for Change Friction.
- [10] - There are some notable exceptions (prime video); e.g. - https://www.primevideotech.com/video-streaming/scaling-up-the-prime-video-audio-video-monitoring-service-and-reducing-costs-by-90
- Assumptions
- Blast Radius
- Change Friction
- Consistency
- Contagion
- Distributed Applications
- Domain Pollution
- Expediting
- Fast Feedback
- How We Got Here
- Innovation
- Lengthy Releases
- Microservices
- Principle of Least Privilege
- Principle of Locality
- Ravenous Consumption
- Regression Testing
- Serverless
- Shared Context
- Upgrade Procrastination
- Waterfall Methodology