PRINCIPLES & PRACTICES
Work-In-Progress...
SECTION CONTENTS
- What is Software?
- The Atomic Deployment Strategy
- Lengthy Release Cycles
- Tools & Technologies Do Not Replace Thinking
- Loss Aversion
- Lowest Common Denominator
- Table Stakes
- Internal & External Flow
- Drum, Buffer, Rope
- Value Identification
- Value Contextualisation
- The Principle of Status Quo
- Circle of Influence
- Unit-Level Productivity v Business-Level Scale
- Efficiency & Throughput
- Change v Stability
- Circumvention
- Feasibility v Practicality
- Learn Fast
- Gold-Plating
- Goldilocks Granularity
- "Shift-Left"
- Growth through Acquisition
- Growth without Consolidation
- The Acquisition / Consolidation Cycle
- Neglecting to Consolidate
- Frankenstein's Monster Systems
- Analysis Paralysis
- CapEx & OpEx
- Innovation v Standardisation
- Non-Repudiation
- Spikes & Double Investment
- New (!=) Is Not Always Better
- “Some” Tech Debt is Healthy
- Consumer-Driven APIs
- MVP Is More Than Functional
- There's No Such Thing As No Consequences
- Why Test?
- Bulkheads
- The Paradox of Choice
- Twelve Factor Applications
- Automation Also Creates Chalenges
- Declarative v Imperative
- Work Item Delivery Flow
- Shared Context
- Direct-to-Database
- The Sensible Reuse Principle (Or Glass Slipper Reuse)
- "Debt" Accrues By Not Sharing Context
- Divergence v Conformance
- Work-In-Progress (WIP)
- "Customer-Centric"
- Branching Strategies
- Lift-and-Shift
- Test-Driven Development (TDD)
- Declarative v Imperative Leadership
- Theory of Constraints - Constraint Exploitation
- Agile & Waterfall Methodologies
- Agile & Less Iterative Activities
- Duplication
- Reliability Through Data Duplication
- Waste Management & Transferral
- Behaviour-Driven Development (BDD)
- BDD Benefits - Common Language
- Single Point of Failure
- Endless Expediting
- Project Bias
- Effective Over Efficient
- Multi-Factor Authentication (MFA) & Two-Factor Authentication (2FA)
- DORA Metrics
- KPIS
- Immediate v Eventual Consistency
- (Business) Continuity
- Upgrade Procrastination
- Blast Radius v Contagion
- Contagion
- Principle of Least Privilege
- Infrastructure As Code (IaC)
- Blast Radius
- Runtime & Change Resilience
- The Principle of Locality
- Reaction
- Evolution's Pecking Order
- Late Integration
- Expediting
- The Three S's - Survival, Sustainability & Strategy
- Inappropriate Foundations
- Silos
- Minimal Divergence
- The Cycle Of Discontent
- Context Switching
- Creeping Normalcy
- Economies Of Scale
- Unsustainable Growth
- Consolidation
- Roadmaps
- Strategy
WHAT IS SOFTWARE?
Let’s begin with a more fundamental, philosophical question. What is software?
My interpretation? Software is but a specific realisation of an idea.
In his Theory of Forms, Plato concluded: ‘... "Ideas" or "Forms", are the non-physical essences of all things, of which objects and matter in the physical world are merely imitations.’ [1]
So, an idea may have many different forms (or interpretations), of which a specific software implementation is just one. There can be many other interpretations, such as different software interpretations, a more physical manifestation (e.g. hardware), or a business interpretation (one that doesn’t necessarily involve technology). Consider digital transformations for example. They typically replace one interpretation (existing business workflows) with another (a digital, software, interpretation), but it’s often the same idea realised differently.
The fixation on interpretation over idea is problematic as it creates an interpretation attachment, causing us to:
- Forget that an interpretation is just one (changeable, malleable) view of an overarching idea.
- Lose sight of the idea, in favour of the interpretation. We're so busy looking at how our interpretation is affected by change (which comes in many forms) that we preclude the possibility that something newer or more radical has been discovered, (more or less) neutralising your interpretation. Of course this view is understandable - no-one wants to tell a business who may have invested millions that its interpretation (solution) is about to become redundant.
- Build (unsustainable) solutions from an “bottom-up” approach. I’ve seen this approach push people to favour a reuse strategy (for the sake of it) rather than due to logical decision making or common sense (Sensible Reuse Principle).
- Be polluted by concepts from the existing interpretation. e.g. the terminology, entity naming, structures, the modelling of relationships, flow, and user interactions may not be appropriate for the new interpretation.
- (Potentially) Lose competitiveness. We continue to build upon a (now) flawed interpretation.
- Think in the shorter-term (realisation), rather than longer-term (ideas).
So what’s my point? We should show caution in how we view value. Value isn’t solely about a specific software interpretation, it’s about the idea and its practical interpretation. Of course, I’m not proposing that we neglect the interpretation, only that we adjust our views to better incorporate the idea, promoting it to first-class citizen status.
THE RISE OF THE FINTECH
The last decade has given rise to many new Fintech (financial technology) businesses. The news is full of their success stories, as they start to take market share from (and outmanoeuvre) the established players. Why is this?
They’re able to interpret the same idea differently, typically in a way which is more appealing to customers than what’s already on the market. Because there’s nothing already in place at point of inception (both in terms of a solution, or in terms of the pollution of a specific realisation), they’re able to work top-down (from idea to interpretation to implementation), building out their realisation based upon modern thinking (social, technological, delivery practices, devices, data-driven decision-making, machine learning, consumer-driven, integrability, accessibility), whilst many established businesses continue to use a bottom-up (realisation-focused) approach, munging together new concepts into their existing estate.
All of this leads to a serious problem for established businesses if innovation and progress are constrained by its existing realisation, and Loss Aversion is at hand. Whilst they could certainly attempt to retrofit modern practices into aging solutions, it doesn’t resolve the key issue - the realisation is (now) substandard, and requires a sea change to re-realise the idea (from the top down) using modern thinking.
INFLUENCES
Market pressures, innovations and inventions, modern practices and thinking, trends, better collaboration, knowledge, and experience all affect how an idea is interpreted, and can cause us to reinterpret it in a new, distinct, or disruptive way.
Customers pay for the idea and the interpretation, but in the end it's the idea they want. They’re tied to the idea, not necessarily to the interpretation. If they find an alternative (better) interpretation elsewhere, then they’ll take their custom there. Alternatively, you may alter (evolve) your own interpretation, or change it entirely and so long as it still aligns with the customer’s interpretation, still retain their custom.
FURTHER CONSIDERATIONS
- [1] - Plato’s Theory of Forms - https://en.m.wikipedia.org/wiki/Theory_of_forms
- Innovation Triad
- Loss Aversion
- Sensible Reuse Principle
THE ATOMIC DEPLOYMENT STRATEGY
I use the term “atomic deployment strategy” to describe a common deployment approach, commonly aligned with the Monolith - where all components must be deployed, regardless of their need. It is an all-or-nothing deployment strategy.
The standard Point-to-Point (P2P) architecture typical in a Monolith suggests a tight-coupling (Coupling) between all software components/systems in its ecosystem. This has several knock-on effects, including (a) making the extrication of specific services/domains from their dependencies difficult, and as a side-effect (b) forcing deployments to include all components, even when only one component is required (or has changed), and regardless of the necessity.
This approach suffers from the following challenges:
- Release and Operational pain – Software Engineers must build/deploy components that are unrelated to the problem being solved. The Ops team expend effort deploying and managing software that is never used (or changed); In others ways, less so due to less moving parts.
- Releases are large, complicated affairs and thus incentivise a Lengthy Release Cycle mindset, slowing change and inviting Entropy.
- Highly inefficient - an unsurety over what’s changed leads us to retesting everything (even though we know large areas haven’t changed).
- Siloing. Atomic Deployment Strategy leads to Lengthy Release Cycle, which leads to longer flows, which naturally leads to the creation of little specialised silos.
FURTHER CONSIDERATIONS
LENGTHY RELEASE CYCLES
Lengthy (e.g. quarterly or monthly) release cycles can be tremendously damaging to a business, its employees, and its customers.
Lengthy Release Cycles often promote excruciating, siloed steps, involving many days of waiting, regular rework, unnecessarily long and complex deployments, and the forced acceptance (testing) of a large number of changes in a relatively short time frame. They also suggest that anything at the end of the release cycle is particularly at risk of expediting, for the sake of a promised release date.
CONWAY’S LAW AND RELEASES
Conway's Law states that: "organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations." [wikipedia]
So, if a system architecture mimics how the organisation communicates, then why wouldn’t its delivery flow also mimic it? i.e. in a siloed organisation, where inter-department communication is limited, and any decision requires lots of lead time, then we’ll also find similar issues with the release cycle (siloed, with lots of waits).
Lengthy Release Cycles can cause the following issues:
- The siloing of teams.
- Communication issues.
- Lack of group ownership.
- Ping-pong releases.
- Mistrust.
- Poor Productivity.
- Poor Repeatability.
- Cherry-Picking, and thus expediting.
- Poor quality.
Let’s view them.
SILOING OF TEAMS
The longer the flow, the easier it is to fit unnecessary steps into a flow, creating little pockets of resistance to fast change.
Silo’ing can cause the following issues:
- A lack of transparency, collaboration, ownership, and accountability.
- Quality is not introduced early enough.
- Rework is a common practice.
Most of the succeeding points are caused by Silo’ing.
COMMUNICATION ISSUES
Silos are the natural enemy of good communication. Work that is undertaken in a silo has (to my mind) a higher propensity to be flawed, simply because of numbers. (As a generalisation) the more brains on a problem, sooner, the higher the quality of that solution.
Consider the natural tendency for siloed teams to work on software in isolation, typically neglecting to involve any Operations or Security stakeholder input (that would slow things down, wouldn’t it?). I’ve often seen cases where the Operations team either won’t deploy the feature, or are duressed into deploying it (against their will and better sense of judgement), causing the accrual of Technical Debt.
Often, it’s because the developer has assumed something (Assumptions) that competes with an operational expectation (e.g. until recently, that’s been stability, although now it might be nearer Resilience), and hasn't sufficiently communicated with them due to the organisation’s siloed nature.
This lack of good communication, alongside Lengthy Release Cycles causes misunderstandings, such as knowing which features are deployed in which environments (see Twelve Factor Apps - Minimise Divergence). E.g. the developer thinks that a bug fix is in Release X on environment Z, whilst in fact, it never got that far.
FEATURE HUNTS
I’ve listened to lengthy conversations around “Feature Hunts”, until someone finally provides evidence (typically by testing it) of what feature is where. It’s mainly due to Lengthy Release Cycles. Feature Hunts are a big time waster for everyone involved.
Poor communications, caused by the siloed mindset, are one reason for the increasing popularity of Cross-Functional Teams.
LACK OF OWNERSHIP
“I can’t do that, only [Jeff/Lisa/insert name here...] knows how to do that. We’ll have to wait for them.” Ring any bells?
That response is pretty common in siloed organisations suffering from Lengthy Release Cycles. It stems from a lack of group ownership and cross-pollination of skills and knowledge that you’d typically get in a Cross-Functional Team.
Why? I think it’s a mix of skills availability and context. For instance, just because someone in Operations has the skills to solve a particular problem, doesn’t mean they have the context to make the right change.
As a technologist, I admit to finding context much harder to understand than technology. Whilst I can pick up most technologies in a relatively short time, applying those skills and techniques in the right domain context is far more challenging (and one reason why I’d argue that consultants should rarely have the final say in a solution, unless there is parity between parties). If you don’t have context, you can’t own it, and if you can’t own it, you can’t help. Alas, we must await Jeff.
Pair/Mob Programming, or Cross-Functional Teams are some counters to this problem.
PING-PONG RELEASES
The scale of change embedded within each release often results in one (or more) major/critical bugs being identified, often late in the cycle (e.g. in system, acceptance/exploratory testing). These bugs must be fixed, causing lengthy “ping-pong” releases between development, build and release, deployment, and several forms of (formal) testing, causing lots of unnecessary waiting and rework.
TRUST
Technology books often focus on mechanisms over people (but sometimes the solution needs something more people-focused). Yet one of the cultural concerns over Lengthy Release Cycles is trust.
Lengthy Release Cycles promote silos, and individuals who are siloed may feel isolated, and neglect opportunities to interact with people within other silos. This is more than a shame, it’s a travesty. People who don’t know one another may have no means to build relationships, and thus trust. And without trust, we face an uphill battle to deliver meaningful change in a short time.
TRUST & CAMARADERIE
The camaraderie that stems from a well-knit, integral team of like-minded individuals shouldn’t be overlooked. It’s an extremely powerful tool to build highly performant, collaborative, antifragile teams.
Much of a team’s strength comes through the accrual of trust. E.g. Bill trusts Dave and Lisa as they’ve worked well together for years. They understand one another’s strengths (and weaknesses), and often complement them to build a stronger foundation. Cross-Functional Teams also build a shared learning platform that reduces single-points-of-failure, thus building trust. Consider the mutual trust and respect that the astronauts built up on the lunar landings, including how each one must learn how to perform the other’s job (a Redundancy Check).
Yet siloed teams don’t get the same opportunities. Whilst people may build trust within the silo, they can’t (necessarily) trust what comes before or after their own little island, creating a Us versus Them mentality.
Colleagues who don’t/can’t truly trust one another may live in a world of stop-start communications (e.g. “I don’t trust them, so I’m going to ensure I know exactly what they’ve done before I let it pass”; a form of micromanagement), and where duplication of work is predominant (e.g. “so what if they’ve tested it, I don’t trust they did it right, so I’ll do it again myself”). Mistrust hampers our willingness/ability to Shift-Left, and thus slows Productivity.
PRODUCTIVITY
Long Release Cycles exist (in a large part) due to difficult environment provisioning. Even in the cases where provisioning is quick, we often still find they’re not a carbon copy of the production environment. This has efficiency ramifications.
For instance, without an efficient provisioning mechanism, we invite systemic problems to creep into the work of development and testing staff, simply because they lack any means of fast feedback; thus, we limit people’s confidence in their own work because they can’t guarantee it will function as intended (i.e. no Safety Net).
Creating the right mechanisms to successfully and efficiently provision environments quickly takes time and money (which is why some organisations never get around to doing it; they’re always “too busy building functionality”). So, some organisations attempt to remedy this by providing a shared environment. But this approach is also flawed. For example, who owns the environment, keeps it functioning, and ensures its accuracy? If no one owns it, no one will support it. The result is stale software/data that doesn’t reflect the production setup. Again, this is hampered by Lengthy Release Cycles and poor provisioning.
RELEASE MANAGEMENT TROUBLES
I’ve seen some interesting approaches to release management through the years (including verifying readiness).
At one organisation, I witnessed a great deal of ping-pong releases, where the entire software stack was deployed, configured and tested, only to find that some feature or configuration had been missed, thus forcing the cleansing and reprovision of the environment, rebuilding the code, redeployment and reconfiguration of the application (which took a couple of hours each time), recording all changes (it was hoped) in an “instruction” manual, and then retesting it all again. This vicious cycle might occur multiple times.
Once the testers gave the thumbs up, the environment was dropped, all the steps in the newly formed “instruction” manual re-executed, then all the testing repeated to prove the instructions were indeed correct! What a massive waste of time and money.
LENGTHY RELEASE CYCLES & CHERRY PICKING
Lengthy Release Cycles may also promote poor practices such as Cherry Picking (a form of Expediting). Cherry Picking is (typically) where someone with little appreciation for the technical difficulties, identifies features/bug fixes they think the business needs and discards the remainder for later release (we hope). Cherry Picking raises the following concerns:
- The picker(s) may regularly favour functionality over non-functional needs (i.e. Functional Myopicism).
- It promotes messy branching and merging activities, where the engineer must identify what’s been picked, discard the remainder, then merge what’s left back for release. This is painful, error-prone, and pretty thankless.
REPEATABILITY
Lengthy Release Cycles make most forms of change difficult (Change Friction). Thus, when change is required (which happens often in dynamic organisations), it incentivises the circumvention of established processes (i.e. Expediting) in an effort to right a wrong; e.g. the effort to manually hack a change into a production environment seems quicker than following the established process (Short-Term Glory v Long-Term Success).
Whilst this approach seems quicker, it actually increases risk in the following areas:
- The change exacerbates the problem, resulting in a bigger problem.
- The change remains unrecorded (or incorrectly recorded), and requires a manual intervention inconsistent with normal practice (i.e. a notorious practice for introducing faults). Tracking the original change is difficult, so we may only be able to infer what changed.
IMPACT ON QUALITY
Lengthy Release Cycles can cause quality issues, simply because of timing. Lengthy Release Cycles tend to increase wait time, hamper collaboration, and don’t lend themselves well to fast feedback (or fail fast). Consequently, there is less time to rectify issues; i.e. less time to increase quality, without incurring cost and delivery time penalties. The question then becomes more contentious; do we release now, because we’ve promised the market something but knowing there are quality issues (which might affect customers), or hold off for another month/quarter to resolve quality issues but potentially suffer reputational damage, and let down our customers in other ways?
Performance (e.g. load) testing is a good example where Lengthy Release Cycles can impact quality. Performance tests (e.g. load, soak) are undertaken towards the end of a release cycle, once everything is built, combined, coordinated, and deployed to a production-like environment. This takes time (and is a lot more involved than you might imagine), and may (see previous points) be difficult to provision (i.e. time and money).
Tasks (such as performance tests) which are not undertaken till towards the cycle end (neglected entirely, or only performed half-heartedly), makes reacting to any identified problems difficult. In the case of performance testing, you may be forced to release software with known scale/performance concerns, leading to poor quality, and incurring Technical Debt. And Lengthy Release Cycles likely means you’ll often find yourself down this same path, where performance testing is never (or rarely) done due to time pressures. Unfortunately, we’re only pushing the problem further down the line, where it will be worse.
Quality is again at risk. And bear in mind that quality can be subjective (Quality is Subjective).
FURTHER CONSIDERATIONS
- Change Friction.
- Expediting.
- Safety Net.
- Shift-Left.
- Cross-Functional Teams.
- Twelve Factor Apps.
- Technical Debt.
- Quality is Subjective.
TOOLS & TECHNOLOGIES DO NOT REPLACE THINKING
We live (and work) in a highly complex, interconnected world. Complex interrelations abound, and every decision we make has both positive results, and negative consequences.
Yet, humans love simplicity, having a natural tendency to focus on positive outcomes, whilst neglecting negative consequences. This oversimplification promotes the chimeric notion that every problem has a silver-bullet solution.
My point? Tools, frameworks, design patterns, technologies, and even books (like this one), are all tools to support thinking; they are not replacements for it.
REAL-WORLD EXAMPLE - THE IMPORTANCE OF THINKING
To support my point around thinking, consider the doctor/patient relationship, and specifically the procedures involved in the diagnosis and treatment of a patient.
Below is a quotation from a medical article. I’ve bolded the words of particular relevance.
“The diagnostic process is a complex transition process that begins with the patient's individual illness history and culminates in a result that can be categorized. A patient consulting the doctor about his symptoms starts an intricate process that may label him, classify his illness, indicate certain specific treatments in preference to others and put him in a prognostic category. The outcome of the process is regarded as important for effective treatment, by both patient and doctor.” [1]
Let’s pause a moment to consider it.
As a precondition to the medical assessment, the doctor familiarises themselves with the patient’s medical history. The assessment takes the form of a familiar protocol, where the doctor asks the patient about their ailment, listens to the patients description/assessment, then begins a dialogue, probing the patient (at appropriate times) to gather more detailed, or accurate, information about the symptoms (i.e. to identify a root cause). Understanding the history (i.e. contextual information) is important here (there’s often an association between past problems and the current ailment), as it may lead to a revelation that will enable the doctor to classify the illness.
Note that at this stage, whilst the doctor has (hopefully) classified the illness, there’s not a single mention of a treatment plan. Only once the doctor has undertaken sufficient due-diligence, and has a keen understanding of the cause (including potentially testing that hypothesis), will they then diagnose and offer a treatment plan. The doctor now begins the next stage; indicate certain specific treatments in preference to others.
At the treatment stage the doctor uses their knowledge, expertise, and judgement, to formulate the best treatment plan based upon their given constraints. Let’s pause a moment to reflect on this.
Now consider the following. Why do doctors consider your age, fitness level, cholesterol, known allergies, genetic familial issues, in addition to accounting for your medical history etc, prior to identifying a treatment plan? Because they must work within the constraints of your Complex System; i.e. how your system reacts to a treatment plan may differ to how my system will react.
However, doctors must also work within the realms of another Complex System; they may be constrained (or influenced) by external influences like time, treatment cost (like budgetary costs; e.g. expensive treatment plans may be disfavoured, even when they’re known to offer more promising results), or (in some cases) unorthodox new treatments (such as in the treatment of a potentially terminal disease; albeit this is a bit of a caveat emptor). We’re talking about the intersection of two complex systems: one for the patient, and one for external parties.
Let me reiterate my last point. No treatment plan is recommended until after the doctor has considered a number of key factors and constraints, and made a balanced decision based on all available evidence.
Returning to the technology domain, I’m sorry to say, I often see a very different approach to how technology treatment plans are undertaken. Whilst I’m not saying it’s true of everyone, my experience suggests that many technologists spend far too little time diagnosing the problem, and often have already formulated a treatment plan before understanding the context to apply it to, or whether it will really work (and this may be subjective too!). This is a form of Bias. To rephrase, I rarely see technologists consider all of the constraints, often only considering the first-level ramifications, but ignorant to second and third-level consequences, or formulating a treatment plan based on an accurate diagnosis of the problem.
The reason for this behaviour is harder to qualify. Is the cost of medical failure much greater (maybe there’s little opportunity to rectify a medical failing - the patient is already affected), or more obvious, than the failure of a technological decision, thus less time is spent diagnosing technology? Possibly, but I suppose that depends on the context. Maybe a medical faux pa is recognised sooner (e.g. the impact on the patient is more immediate)? Are there more rigorous validations in the practicing of medicine than in technology? I’m less sure about that one. Do we know more about the human body than technology? No, I’d label both as Complex Systems...
I suspect there’s a more obvious answer, known as Affect Heuristic.
“The affect heuristic is a heuristic, a mental shortcut that allows people to make decisions and solve problems quickly and efficiently, in which current emotion—fear, pleasure, surprise, etc.—influences decisions. In other words, it is a type of heuristic in which emotional response, or "affect" in psychological terms, plays a lead role.” [2]
“Finucane, Alhakami, Slovic and Johnson theorized in 2000 that a good feeling towards a situation (i.e., positive affect) would lead to a lower risk perception and a higher benefit perception, even when this is logically not warranted for that situation. This implies that a strong emotional response to a word or other stimulus might alter a person's judgment. He or she might make different decisions based on the same set of facts and might thus make an illogical decision. Overall, the affect heuristic is of influence in nearly every decision-making arena.” [3]
We’re often driven by our emotions towards a specific technology or methodology, which may play a lead role in our decision making. I've seen this time-and-again; from an unhealthily averse response to certain vendors, regardless of the quality of their offering, to an inappropriately positive outlook towards specific cloud technologies incompatible with the business’ aspirations, or timelines. It sometimes leads to technologists attempting to fit a business around a technology constraint, rather than the converse (Tail Wagging the Dog).
BALANCED DECISION-MAKING OVER TOOLS & TECHNOLOGY
A good deal of this book attempts to demonstrate the complex interrelations within our industry. My advice is simple. Rather than attempting to solve a problem through the introduction of a new tool or technology, I (at least initially) emphasise the importance of better understanding these complex interrelations, helping you to make more informed and balanced decisions on technology/tooling choices.
BRING OUT YOUR DEAD
The technology landscape is littered with the broken remnants of once lauded tools and technologies that nowadays cause raised eyebrows and sheepish grins.
Some enterprises now face major challenges, through the heavy investment in a (now irrelevant) technology. The problem is twofold:
Whilst hindsight is a wonderful thing, I believe that with the right mindset and knowledge, it’s possible to foresee many (but not all) obstacles on the road in enough time to avoid them, or pivot, simply by applying more balance to the decision making process.
- Transitioning to a new technology is technically challenging.
- The existing technologies and practices are so ingrained in the organisation’s culture (through Inculcation Bias) that there’s little opportunity to reverse the decision.
There’s no such thing as a free lunch. “Good” outcomes and “Bad” consequences are so entwined that it’s impossible to separate one from the other, and extricate only the good. Consider the following cases:
- SOA & ESBs. As a nascent practice, SOA was lauded as a technological revolution. It certainly had merits, such as the better alignment of business and technology, and service-focused solutions. It also helped to pave the way for XML to be treated as the defacto data transfer mechanism. Yet nowadays SOA (generally) has derogatory connotations. As do ESBs (Enterprise Service Buses), popularised by the rise of SOA, and now demonised as incohesive, single-points-of-failure.
- Employing Rapid Application Development (RAD) principles and tools may increase initial development velocity, but they may also increase Technical Debt (e.g. exposing entities as DTOs, or advocating a direct-to-database integration mindset, inculcating a bottom-up mentality to API and UI design, and thus resulting in solutions made for developers, not users).
- Many cloud/vendor technologies are fantastic, but some are highly proprietary, and can tightly couple you to a specific vendor (Honeypot Coupling).
- “All problems in computer science can be solved by another level of indirection.” [David Wheeler]. “Any performance problem can be solved by removing a layer of indirection”. [Unknown].
- Embedding business logic in SQL procedures (typically) hardens code from attack, and suggests improved performance (at least latency, not necessarily scale), but it likely also increases vendor coupling, reduces Portability, and introduces (affordable) talent sourcing difficulties, thereby hampering your business’ ability to scale.
- SQL joins across disparate domain tables likely increases performance, and scalability but only to a point. It mayalso reduce Evolvability, (horizontal) Scalability, and potentially reduces Security (increases the area to secure; Principle of Least Privilege cannot be applied).
- Returning a persisted entity (rather than a DTO) from an API promotes Productivity through Reuse, but reduces Evolvability, and may introduce security vulnerabilities (exposing too much).
- Microservices has many redeeming qualities, but they also increase manageability costs, may nudge you down a (previously untraveled) Eventual Consistency model, and (if not carefully managed) can cause Technology Sprawl.
- Solutions built around a PAAS reduce many complexities (through abstraction), and likely increase development/release velocity. Yet they’re more opinionated (than IAAS for instance), and also tend to reduce Flexibility, by constraining the number of ways to solve a problem.
MARKETING MAGPIES
Beware of Marketing Magpies; individuals who wax lyrical on new tools and technologies, based mainly around the (potentially biased) opinions of others. They may be missing the balanced judgement necessary for strategic decisions.
KNOWN QUANTITY V NEW TECH
Never hold onto something simply because it’s a Known Quantity, and never modernise just because it’s new and shiny. Change takes time and patience, and should always be based upon a business need or motivation.
Will we be demonising Microservices and Serverless in decades to come? Possibly. So let’s finish on a more uplifting note.
The best tool at your disposal is not some new tool, technology, platform, or methodology; it’s a diverse team with complementary skills and experience, with a precise understanding of the problem to solve, a good knowledge of foundations and principles, coupled with a deep understanding of the complex interrelations that exist between business and technology, and sound, balanced decision-making which remains unbiased (and sometimes undeterred) by the constant noise and buzz that encompasses our industry.
FURTHER CONSIDERATIONS
- Inculcation Bias.
- Marketing Magpies.
- Honeypot Coupling.
- PAAS.
- Technology Sprawl.
- Microservices.
- Technical Debt.
FURTHER READING
- [1] - https://academic.oup.com/fampra/article/18/3/243/531614
- [2] [3] - https://en.m.wikipedia.org/wiki/Affect_heuristic
LOSS AVERSION
“In preparing for battle I have always found that plans are useless, but planning is indispensable.” - Dwight D. Eisenhower
Coupling should be, but often isn’t, considered alongside Loss Aversion (i.e. how averse your business is to the loss of a service, or feature). Owners of systems with a tight-coupling to integral services or features, may suffer great financial hardship if those services become unavailable (e.g. whether in the temporal capacity, or something more final, such as partner bankruptcy). Astute businesses identify key services or features they are averse to losing, and either plan for that failure, or deploy countermeasures (by building slack) into the system.
Netflix provide the archetype from a systems perspective, practicing several key aspects of fault tolerance (in their Microservices architecture) to counter Loss Aversion:
- They proactively identify failing services, stop/throttle requests to them, and may terminate defective ones.
- They apply fallback procedures for underperforming services; e.g. they may present static recommendation content if the personalised customer response isn’t received in a reasonable time-frame.
- They intentionally inject faults, or additional latency, in a controlled manner, into their system to learn from it. Whilst this may seem counterintuitive, it actually increases their resiliency.
Consider the following scenario around Loss Aversion.
Let’s say I’m starting a new business venture to provide baking advice and recipes. To market my business, I need the following things:
- A domain name representative of my branding. Let’s call it blithebaking.com, costing me $5 per month.
- A website, to advertise my services, offer advice, recipes etc.
- Business cards. I use these as part of my branding exercise, to hand out to potential customers. Printed on each card are my contact details and website address (i.e. Domain Name).
The coupling might take this form.

Domain Name Coupling
Now whilst this represents a very simple case of Coupling, there’s already a few potential failures here. In this case, I’ll focus on the domain name.
Let’s say I’m remiss, and fail to renew my domain name on its renewal date. Several scenarios can play out:
- I’m comfortable with the loss (i.e. I’m not averse to the loss, accept it, and move on). In this case I’m loosely coupled to this outcome and can easily recover.
- I’m uncomfortable with the loss, but remedial action is available (i.e. I’m moderately averse to the loss). Whilst in this case, I’m tightly-coupled to the outcome, I have recovery options (let’s say I manage to renew the domain name).
- I’m uncomfortable with the loss and there’s no remedial action available (i.e. I’m highly averse to the loss).
Let’s say option 3 occurs. I’m remiss, and lose my domain name to a competitor (it’s a popular domain name!). That competitor links their own website to the blithebaking.com domain, which either confuses all my existing custom, or routes them all to my competitor. I’ve drawn up a table of potential outcomes below.
| Scenario | Domain Name Costs (monthly) * | Business Cards Costs (one off) | Website Costs | Number of Customers (sales avg. $50) | Overall Potential Cost | (My) Level of Aversion |
|---|---|---|---|---|---|---|
| 1 | $5 | $50 (100 cards) | $0. Built it myself. | ~10 | $610 ($50 + $500) | Low |
| 2 | $5 | $50 (100 cards) | $0. Built it myself. | ~500 | ~$25K ($50 + $25,000) | Medium to High |
| 3 | $5 | $10K (100,000 cards) | $0. Built it myself. | ~10 | ~$10K ($10,000 + $500) | Medium to High |
| 4 | $5 | $10K (100,000 cards) | $0. Built it myself. | ~1000 | ~60K ($10,000 + 50,000) | High |
| 5 | $5 | $10K (100,000 cards) | 2K per change. Third party managed. | ~1000 | ~62K ($10,000 + $2,000 + $50,000) | High |
| * The domain name costs aren’t included in the overall potential costs; they highlight the disparity in how a tiny outgoing may relate to the Aversion costs it affects. | ||||||
You can see how quickly the combination of aversions can wreak havoc. The key concepts are:
- How tightly I’ve coupled myself to depend on something else (whether it’s a business card, or custom).
- How costly (to me) the loss of that dependency is (this need not be monetary).
Scenario 1 is the best in terms of low coupling/dependence. I’ve spent very little on business cards, and I have limited custom at this stage. I might grumble, but I can live with this outcome. Scenario 2 has cost me dearly due to the significant number of customers I had. Scenario 3 is an interesting one. Whilst I have limited custom, my somewhat unorthodox approach of purchasing 100,000 business cards as an up-front investment (a form of stock), prior to validating my business model, has done me a disservice, inflicting a form of self-inflicted Entropy upon myself.
Scenarios 4 & 5 show the worst cases, where my Loss Aversion is at its highest. In Scenario 5 I demonstrate that for the sake of only $5 a month, I’ve inflicted immediate costs in the region of $62,000. But there’s also the unseen, insidious costs to consider here; e.g. note that I haven’t considered the longer-term branding implications. Has it actually cost me hundreds of thousands of dollars?
How the number of customers affects our Loss Aversion falls into the scale category. Large-scale failings concern me more, because of the large disparity between (say) 10 customers, and 1000 customers.
LOSS AVERSION MAY BE SUBJECTIVE
One individual’s perception of Loss Aversion may differ to another, introducing an additional degree of complexity. For instance, whilst I might consider a $15K loss unacceptable, another - with stronger recovery capabilities - may not.
TIME CRITICALITY & LOSS AVERSION
Time criticality (the permanence of the failure) is another consideration.
Temporal failure may be sufficiently disruptive to put your business at risk, and you might want to consider:
- What is an unacceptable duration of disruption to your business? Depending upon the situation, it might be seconds, or even days.
- Timing. When did the failure occur? E.g. if my sales website fails at 3am one cold Sunday winter morning, I’m probably less concerned than it occurring at 6pm on Black Friday. Alternatively, if a large proportion of my revenue comes through events (e.g. a sports event), then the timing of a failure is crucial.
What’s interesting about my earlier example was that the outcome was - given enough time and foresight - utterly controllable. Most of the problems I found myself in were due to my inability to react, which I’d inflicted upon myself.
Whilst there’s no golden rules around Loss Aversion, that doesn’t suggest we shouldn’t plan; especially when each scenario is unique, complex, and responses may be subjective. The outcome of any decisions made here should feed into discussions around Coupling.
FURTHER CONSIDERATIONS
- Coupling.
- Complex System.
- Entropy.
- Microservices.
- https://www.sitepoint.com/help-ive-lost-domain-name
LOWEST COMMON DENOMINATOR
Lowest Common Denominator - if correctly used - can be a powerful tool. In a sense, it promotes Uniformity, which is a powerful Productivity enabler.
Consider the following example. For many years (and even today), one of the biggest problems facing integration protocols was the lack of widespread support for a single approach across the major vendors. Achieving a significant quorum was difficult as each vendor was either already heavily invested in an existing protocol, or was promoting their own. Standards existed but they were many pockets of resistance.
For instance, for many years Microsoft supported COM and DCOM, whilst Sun/Oracle promoted RMI (based upon Corba) for much of the “enterprise edition” integrations. Whilst both protocols are highly regarded, they often influenced the direction of the implementation technology; e.g. there was a vicious cycle, where opting to implement one solution in Java promoted the RMI protocol, which in turn influenced all further solution implementation choices to be Java (regardless of whether it was the right tool for the job).
As new technologies, such as XML (and later JSON) emerged, we began to see a nascent form of (implicit) standardisation (through uptake, rather than necessarily vendor-driven). Web Services settled upon string-based data transfer structures that were highly flexible, hierarchically structured, human readable, and could easily represent most business concepts, all over HTTP. It allowed the implementation technology to be decoupled from the contract (or API interface), enabling us to separate how we communicate with software services, and how behaviours/rules are implemented within it (Separation of Concerns). As long as you could communicate in string-form over HTTP, you could integrate; i.e. it became the Lowest Common Denominator.
We’re now seeing this Lowest Common Denominator used across highly-distributed polyglot systems (e.g. Microservices) as the default communication mechanism.
MICROSERVICES & LOWEST COMMON DENOMINATOR
One of Microservices key benefits is its ability to support highly distributed, heterogeneous systems. It achieves this, in large part, through the use of the Lowest Common Denominator principle to communicate between software services.
LOWERING THE GAP
Interoperability is a key design feature of the .NET platform. It lowered the gap, by providing a common engine to leverage any managed (running under the CLR) and unmanaged code (written as C++ components, or COM, ActiveX) to communicate. The benefits include:
- Greater choice of implementation technology, inculcating a “Best Tool for the Job” mindset.
- The ability to source a greater pool of talent - if you can’t get C~ talent, you might source some VB.net.
- Extended sharing and reuse capabilities; e.g. reuse an existing investment, such as using a VB.net library in a C# application.
Note that whilst Lower Representational Gap draws upon the many benefits of Uniformity, one drawback may be innovation; i.e. new ideas often come from unique sources; less readily from sources that share many common attributes within an established order.
FURTHER CONSIDERATIONS
TABLE STAKES
In gambling parlance, to play a hand at the table, you must first meet the minimal requirement; i.e. you must match/exceed the table stake.
In business, Table Stakes are the features, pricing, or capabilities, a customer expects of every product in that class; i.e. it is the Lowest Common Denominator. In many cases, Table Stakes’ features are the core, generally uninteresting aspects of a product, so integral that they’re rarely discussed in detail during a sales negotiation (you shouldn’t be at the negotiation table without it).
Whilst Table Stakes normally relate directly to the product, they need not. For instance, a customer may demand regular distribution through a technique such as Continuous Delivery, or a cooperative and inclusive culture more akin to a partnership.
INTERNAL & EXTERNAL FLOW
Good Flow is an important characteristic of any successful production line, and thus your ability to deliver regularly, accurately, and efficiently. Yet it seems that many businesses fall foul of what I term Internal Flow Myopicism; i.e. they only consider their own internal flow when considering their delivery pipeline - and this may not represent the whole picture.
The figure below shows an example of flow within a (software) delivery pipeline. Let’s assume in this case that it’s a software supplier providing a platform to customers to build products upon. In this case, the assembly line has only five sequential stages (S1 to S5).

Flow
The “constraint” (i.e. the slowest process in the flow, or bottleneck) is, in this case, stage 3 (tagged with an egg-timer symbol; it’s also the smallest) in our five-stage process. No matter how fast the rest of the system is, throughput is dictated by this constraint. Inventory sits on the Buffer (see Drum-Buffer-Rope), waiting to feed the constraint.
What isn’t always immediately obvious from the above diagram (and something that is easy to overlook) is that the entire flow (from inception until real use by an end user) is typically far more expansive than just the internal flow. For instance, let’s say a supplier provides you a service (such as a software platform), which their customers (i.e. you) build upon to create their own product, which they - in turn - sell to their own customers. The figure below shows who’s involved in that chain.

Customer - User
Technically, from a suppliers perspective, the supplier’s customers are also intimately linked to the flow and should not (at least from the customer’s perspective) be considered in isolation; yet they were never represented on the original (supplier) diagram. IF Value is indeed associated with both what YOU provide AND what your SUPPLIERS provide, then this is an important point.
If we were to consider Drum-Buffer-Rope to represent both the supplier and the external customer, we would likely find that the drum beats to the much slower rhythm of a specific customer (the slowest part in the chain); not the velocity of the supplier, nor the fastest customer, not even of the second slowest consumer. Let’s see that now.

Entire Flow
The Supplier pushes it’s wares out to three customers; A, B, and C. Customer A moves quickly and can easily integrate those supplier changes whenever they arrive. However, Customers B and C move slower (B in this case being the slowest) and can't integrate those supplier changes so quickly. This, therefore, is the theoretical constraint (I say theoretical as it doesn’t happen like this in practice).
Of course, this picture is somewhat skewed by reality. None of the parties necessarily knows one other, or their velocity. And neither - in most cases - is the supplier aware of them. Customers are only cognisant of the supplier velocity, and their own velocity, nothing more.
But humour me for a bit longer. It’s all academic after all. If - as I have inferred - we find that the constraint sits with a specific customer (B in our case), yet the drum actually beats at the supplier’s speed, then we find that all of the inventory (the Buffer in Drum-Buffer-Rope) builds up ahead of Customer B (much like in the tale of The Magic Porridge Pot [1], where the porridge keeps flowing until the whole town is filled with it), and to a lesser extent, in front of the other slow customers (C).
You might question the fairness of this situation; why can’t the supplier move at my speed? So allow me to present you with an analogy. Imagine yourself in ancient Greece; specifically Athens, during the time of Socrates (circa 470-399 bc, if you’re really interested). Before you stands the great man, surrounded by his avid students and followers, all deeply engaged in one of his famous discourses. Let’s also assume you understand ancient Greek. The dialogue moves at a furious pace, back-and-forth between teacher and students, and you quickly find yourself unable to follow the main thrust of the argument.
Rising from your seat, you interrupt Socrates mid-flow, explain your lack of clarity, and suggest the group adjust their verbal discourse to a tempo more suited to your mental faculties. Would the great man, or indeed his followers, appreciate your (regular) interruption, and be willing to sacrifice everyone’s learning and enjoyment (it would probably frustrate a few), to slowly recount every minutiae, solely for your comprehension? Or might you be shown the proverbial door? My money is on the second option. So why should a software vendor (Socrates in this analogy) behave differently?
Of course, there is an alternative tactic, which fits well into our analogy. Rather than interrupting the flow, and facing indignation and alienation, you try to hide your ignorance; returning each day to hear the great man speak, reclining in your seat, nodding in appreciation at appropriate intervals, but not once comprehending the argument. What’s occurring here is your own form of personal (learning) debt accrual; at some critical juncture you’ll suffer a personal catastrophe (one day Socrates turns to you and asks you to argue your point of view - of which you have none readily available), and may even be laughed out of Athens (maybe the Spartans will be more accommodating?).
Let’s now return to the software world, and see if we can fit it with our analogy. If we find that the software our business depends upon moves at an uncomfortably fast pace, we can:
- Make our views known, and hope someone listens. However, unless they’ve a (very) good reason, that supplier probably won’t slow for you (and maybe won’t even notice you). The drum beats to the supplier’s needs, not yours, not some other consumer.
- Ignore (and procrastinate over) the problem. This amounts to (virtual) inventory accruing in front
of your business (which, being a virtual offering, is difficult to see).
If you don’t keep up you accrue technical debt (affecting Agility, amongst other things),
and reduce the value you can provide to your customers. You can ignore it for a while,
but eventually it will cause:
- Embarrassment.
- A competitive disadvantage.
- Frustrated customers.
- Integration issues due to the progressively larger queue of upgrade requests.
- Stay ahead of the game. This amounts to regular dental flossing; it might not be enjoyable, but its regularity promotes good health and minimises major incidents.
FURTHER CONSIDERATIONS
DRUM, BUFFER, ROPE
Good Flow is an important characteristic of any successful production line. Drum-Buffer-Rope (DBR) - popularised in the Theory of Constraints (ToC) - is a heuristic to visualise flow and constraint management.
The figure below shows a basic example of flow within a (software) delivery pipeline.

Software Delivery Pipeline
In this case, the assembly line has only five sequential stages (S1 to S5). We find that stage 3 (tagged with an egg-timer symbol) is our system “constraint” (the slowest step in the process).
Now that we’ve identified this constraint we can represent it using Drum-Buffer-Rope. See the figure below.

Software Delivery Pipeline with Drum-Buffer-Rope
In this model the Drum represents the capacity of the “constraint” (i.e. the slowest process in the flow, or bottleneck); in this case, stage 3 in our five-stage process. No matter how fast the rest of the system is, throughput is dictated by this constraint.
WAR DRUMS
For centuries, drums were used by the military for battlefield communication, to signal an increase or decrease in tempo (such as during a march), or to signal coordinated manoeuvres.
Inventory sits on the Buffer, waiting to feed the constraint. The Rope can be pulled to increase flow to the constraint; i.e. ensuring the constraint is never starved (which would effectively cut the entire system’s throughput; a unit of time lost to the constraint is a unit lost for the overall system).
FURTHER CONSIDERATIONS
VALUE IDENTIFICATION
Value should be a measurement of the whole, not the part; not solely what you can offer, but an amalgam of what you and your supply-chain can offer your customers.

Perceived Customer Value
Whilst customers may not always explicitly state it (Functional Myopicism), they expect certain qualities in the software and systems that they use (and purchase); such as stability, Security, accessibility, Performance, and Scalability. Customers who directly foot the bill for your service probably also appreciate efficient (and cost-effective) software construction and delivery practices.
TABLE STAKES
When viewed, these system qualities are often seen as Table Stakes, and may be glossed over during sales discussions. However, that doesn’t make them irrelevant.
Most businesses rely heavily upon the software platforms and services of others; and as a business, we inherit traits and qualities from those suppliers (e.g. platform stability, or instability); yet we can’t necessarily Control any of these aspects themselves. And if customers value the whole, not the part, then logical deduction suggests that these inherited traits also hold customer value. The figure below shows some examples of inherited traits (value) that suppliers may offer you and your customers.
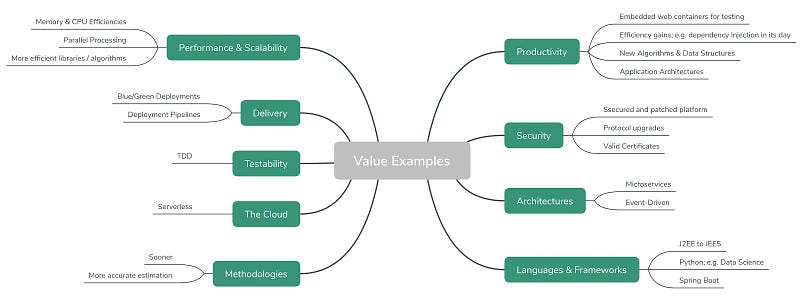
Value Examples
Some might question the merit of these qualities, so let me present you with some examples based upon my experiences.
EXPERIENCES
EMBEDDED WEB SERVERS/CONTAINERS
Web servers/containers are used to host software and serve out web requests. Historically, they have been treated as entirely independent entities, embedded within the deployment and runtime software delivery phase, rather than the construction phase; however, those lines are now being blurred.
Embedding web containers into my day-to-day engineering practices had profound benefits on my software development habits and productivity over my original working practices. Bringing development, testing, and deployment activities closer together enabled me to do more of what I had typically invested less effort into (not through choice as much as through necessity), and to do so sooner.
For instance, prior to the switch, these were the steps I would typically follow:
- Write the code.
- Build and package the code.
- Stop the web container.
- Copy the runtime artefact.
- Navigate to the correct folder in the web container, and paste in the artefact.
- Start up the container.
- Wait for it to start.
- Execute runtime acceptance tests.
Whilst I performed some form of incremental development involving deployment and runtime test phases, it was numbing and laborious, and rife with start/stop/navigate/wait activities. Embedded web containers changed all that, and also allowed me to embrace TDD practices.
I estimate these practices improved my delivery performance by around 25%, enabling me to deliver functionality (of greater robustness), sooner, through more rigorous testing.
MAVEN
Whilst Apache Ant was a significant step forward over its predecessors (e.g. “make files”), it was - for me - Apache Maven that was the real trailblazer. Maven is a build automation and dependency management tool that uses an elegant, easy-to-follow syntax, sensible conventions (e.g. a standardised location for source code and unit tests), has fantastic dependency management (a key problem to minimise duplication and “versioning hell”), and strong plugin support (see my point about embedded web containers). The end result? Increased Productivity, Uniformity, and (release) Reliability.
MOB PROGRAMMING
Whilst initially sceptical of this approach (a group - or mob - work on the same work item together for an extended period, until complete), I soon found it to be a great way to align teams around a domain and/or a problem, gain new skills, collaborate, build trust and acceptance, grow in confidence, and increase business scalability and resilience (having a pool of people with sufficient expertise to solve similar problems increases flexibility and enables the more reliable sequencing of project management activities).
DISTRIBUTED ARCHITECTURE
The introduction of a distributed (Microservices) application architecture enabled me to innovate (use a range of different technologies to solve a problem), isolate change (increase Productivity) and therefore reduce risk, support evolution, and embed TDD practices into my day-to-day work.
THE CLOUD
The Cloud has had a significant impact on many technology-oriented businesses. Need I say more?
LINKS AND ENABLERS
Most of these technologies/techniques have close associations or interrelations; and one often becomes a direct enabler to the next. For instance, in a previous role, I couldn’t gain the benefits from embedded web containers (or Maven), until we broke the monolithic architecture into smaller "Microservices". Once that approach became available, I could more readily apply a TDD mindset to many problems, resulting in better quality code and swifter future change. That TDD-driven mindset supported a marked increase in automated test coverage, which subsequently promoted continuous practices, like CI/CD. Once that was in place, I could look at Canary Releases etc etc.
My point is that there are almost always second and third-order effects to any decision, and you can’t necessarily know what the downstream impact of introducing one idea/technology will be. As I described, the introduction of one innovation may lead to many others, leading to a flood of innovation, and cultural improvements across the business.
PERCEIVED VALUE
Surely some, if not every one of these innovations has value? So, why are they given a second-class status within so many organisations? I can think of several reasons:
- Features are - to put it bluntly - more interesting to most people than non-functional qualities, and therefore drive more interesting discussions.
- Customers infer many of these qualities as Table Stakes, so they may be glossed over and easily accepted in sales discussions. This is a double-edged sword - it allows sales discussions to be steered by the key drivers (e.g. functionality), but it doesn’t necessarily promote these as important qualities in the minds of leading internal executives. Not asking about something, and not caring about it are two different things.
- Many of these traits aren’t easily contextualised (Value Contextualisation).
- Customers don’t appreciate the ramifications of the absence of a system trait (to my last point about contextualising) until it’s too late. A failure in any one quality can cause severe embarrassment, reputational harm, or even a business’ demise (consider the reputational harm done by businesses suffering from a data breaches). I’d place a bet that most of the executives within the organisations that have suffered a significant security breach are now deeply aware (contextualised) of failings in the Security quality.
WHAT’S THE MINIMUM?
Good ROI is mainly about doing the minimum to satisfy Table Stakes, whilst investing the remainder on creating diverse functionality that excites customers. You want prospective customers to leave with the perception of a high quality product (which it hopefully is), and balance effort (and therefore ROI) by doing just enough Table Stakes to be successful. But how do you measure what's the minimum? It's rather subjective.
We can perceive value from two alternate angles:
- What external parties (customers) perceive.
- What the internal business - offering the service - perceives.
See the figure below.
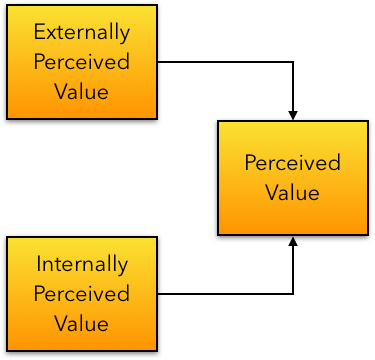
Perceived Value
The external and internal parties perception of value are rarely identical, and can often be radically different. There’s no hard-and-fast rules in how different stakeholders perceive value. For instance, whilst some customers may perceive value lies with Functionality, Reliability, Usability, (and possibly) Security, internal stakeholders may perceive value lies in Functionality, Reliability, Scalability, Security, and Productivity. Much of these views comes down to our ability to Contextualise, yet perception may also shift over time, as people gain new learnings, or by the stimulus of some tumultuous event, causing us to reassess our previous beliefs.
We might visualise the problem as two distinct sets of perceived value, intersecting where the two parties are in agreement. See the figure below.
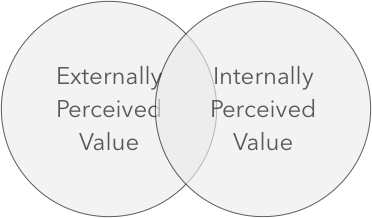
Two Value Sets
For instance, if both parties viewed Security as being of prime importance, then that quality would lie within the intersection, and should therefore be accorded an appropriate amount of energy from both parties. Ideally, there would be a large intersection (a commonality) between the two, representing a close alignment in goals and virtues between the two parties (you and your customers); such as in the figure below.

Large intersection means greater alignment
To my mind, this scenario better represents a partnership between aligned parties, rather than the typical hierarchical customer-supplier model that’s been a mainstay of trade for centuries. In this partnership both parties are deeply invested in building the best product or service; not because it benefits the one party only, but because it benefits everyone: 1. your business, to build a world-class product to sell widely, and 2. the customer, to allow them to reap the biggest benefits from that product.
As Adam Smith put it:
"It is not from the benevolence of the butcher, the brewer, or the baker that we expect our dinner, but from their regard to their own interest." [1]
"INTERNAL VALUE? - WHY SHOULD I CARE? I DON'T PAY FOR THAT"
External customers may be of the opinion that they don’t pay for internal value. They’re paying for functionality, not some seemingly vague notion called Maintainability, Scalability, or some other “ility”.
Whilst I understand that viewpoint, it seems rather myopic, and - to my mind - not entirely valid. In one way or another (whether in its entirety, or through some SAAS-based subscription model), external customers pay a share for the product or service that is delivered. And ALL software has production and delivery costs. And what about innovation?
If the supplier is slow (because they have inefficient construction or delivery practices), the external customer “pays” in the following ways:
There’s also something to be said around Brand Reputation. As a customer, you should be able to ask the tough questions about scalability, resilience, security, productivity etc. Misinterpret these and you’ll pay for them too; whether in fines, lost revenue, share price, or simply embarrassment. Don’t believe me? Do a quick search on some of the big organisations who’ve suffered a major security breach, or the airlines that have suffered system availability/resilience issues, and analyse the outcome.
- They’re investing in the time for that business to do things other than produce functionality, or (for instance) the further stabilisation of the platform.
- They’re not getting innovation quickly enough. Consider this a bit longer. I’ll wait... Innovation is key to the existence of many businesses; without it, many would have shrunk into insignificance. And if your competitors (using another supplier) can out-innovate you, then surely that represents a problem?
SUMMARY
My point? Different parties perceive value differently. The greater the discrepancy, the greater the chance of that partnership (eventually) failing. Some modern businesses have dismissed the rather one-dimensional, and deeply hierarchical, customer-provider business model, to favour one of a collaborative partnership, by aligning on what’s truly valuable (the qualities intersection) and learning from one another, to build long-term relationships of mutual benefit.
We dismiss the value that (upstream or downstream) suppliers can provide from our regular productization practices at our own peril; they offer benefit internally and externally; platform upgrades should be given a first-class status alongside internal product improvements.
However, to appreciate value, we must also be able to contextualise it; the subject of the next section (Value Contextualisation).
FURTHER CONSIDERATIONS
- [1] - The Wealth of Nations - Adam Smith
- Flow
- Table Stakes
- TDD
- Functional Myopicism
- Control
- Value Contextualisation
VALUE CONTEXTUALISATION
The ability to contextualise value comes from several sources, including:
- Knowledge; e.g. "Everything I’ve read on this subject indicates this is the best way to do it."
- Experience; e.g. "I’ve seen this before; we better resolve it now, or it will bite us later."
- Use the knowledge/experience of others to guide you to make better decisions.
- Experiences still to occur. These are often the stimulus of some tumultuous event, causing us to reassess our beliefs. They shape your future (business) self.
We can categorise this contextualisation as either proactive (enabling forethought - i.e. Prometheus), or reactive (hindsight, or afterthought - i.e. Epimetheus). See below.
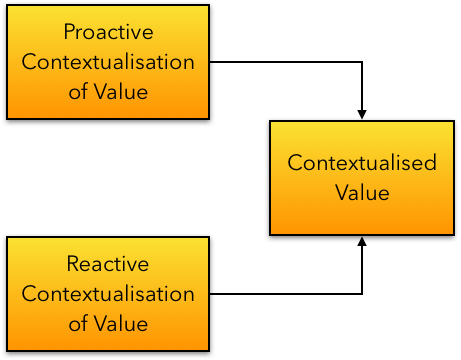
Value Contextualisation
Value - therefore - is an amalgam of what customers can proactively contextualise, and what they must retrospectively contextualise (typically, right after a significant system failure).
The ability to proactively contextualise value can be a very important ability. See the graphic below.
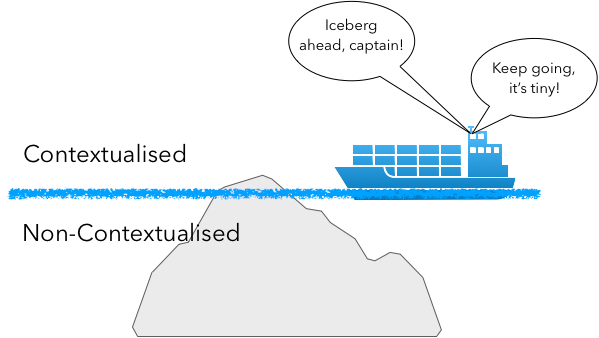
Failure to sufficiently contextualise leading to disaster
Failing to spot, or - in this case - to contextualise (the crew spotted a problem, they just never afforded it sufficient credence) the unseen, and change course, may result in disaster; i.e. if we build a product or business where little is visible (and known), and much remains invisible (the insidious unknown), we should proceed with caution, and be mindful of icebergs.
Most business customers I meet with see what’s above the water (e.g. functionality), and thus, can contextualise it. Yet, they don’t necessarily see, ask, or are given access to, what lies below the surface. Thus, they can’t contextualise its importance or indeed, its purpose. Business news is rife with examples of systems that weren’t sufficiently contextualised (or given credence) by their owners, forcing them to react (and rather swiftly) after a tumultuous event [1]. But the horse has already bolted.
A CHRISTMAS CAROL
In Charles Dickens’ famous classic novel A Christmas Carol [2], the main character - Eberneezer Scrooge - is portrayed as a spiteful, grasping, misanthropist, with no love for anything other (it seems) than money. You probably you know the story.
Scrooge had lost all sense of his humanity, and became blind to problems of his own making. Prior to the main event, we are treated to various scenes of loathsome rapacity as he turns away men of charity with hurtful words; scathes and mocks his good-natured nephew; loads misery and poverty upon Bob Cratchett and his family, and even dismisses the chained spectre of his once lauded, and now dead business partner, Jacob Marley, warning Scrooge to repent before it is too late (Marley is dismissed as a piece of undigested food). None of these actions are sufficient for Scrooge to contextualise what he truly values, so he is given a hard lesson.
Scrooge is visited by three ghosts on the eve of Christmas; the ghosts of Christmas past, present, and future. Through the course of the night, Scrooge is shown the error of his ways, and his own mortality is laid bare. It slowly dawns on him that he cares for more than money (e.g. his own mortality, how others view him, and his regained love of fellow man). He repents in time, and is able to change his destiny.
Where am I going with this? Well, it took the visitation of the ghosts for Scrooge to contextualise what he truly held valuable; i.e. it took a tumultuous event for him to reassess his values/beliefs, in order to make changes. Fortunately, time was on his side.
Whilst this novel has a fantastical theme, the underlying issue of reactive contextualisation still applies to how some businesses are run. These businesses are ill-prepared for the visitation of some “quality spectre” (whether it be Security, Resilience, Scalability, or regulatory non-compliance), and are forced to reactively contextualise. It takes some tumultuous event to wake them, during which time they’ll probably suffer harm (e.g. reputationally, financially, innovation dampeners).
We can’t change an outcome, yet by proactively contextualising, we can influence both our current position, and our future.
There’s another aspect to consider here too; whilst what’s below the surface may not sink you, it also may not be to your advantage. The metaphor of the graceful swan above water (external customers contextualise this), with duck legs paddling furiously below (the internal business contextualise this) fits well into this model.
You might be paying for a swan, but getting a duck! Aesthetic Condescension is a popular trap to the unwary; slap a new front end on a legacy product, and sell it as something new. The unwary see a flashy new UI and link the entire product (and practices) to modernity, even though it’s just a veneer. Again, there is a contextualisation problem; we’re blinded by beauty and can’t see the ugliness below (or the other idiom; "you can put lipstick on a pig, but it’s still a pig" [3]).
WILLINGNESS TO LEARN
Of course, much of this proactive contextualisation assumes a willingness to learn.
I knew a senior executive who (at least outwardly) seemed entirely unwilling to learn about the key technologies or practices used to build the business’ product suite. Now, I’m not suggesting that that executive should be coding software, but their lack of appreciation for it, and how teams worked, made it hard for them to contextualise, so they couldn’t proactively support the business needs - e.g. to identify, correctly prioritise, and solve key problems on the horizon, prior to them becoming serious impediments. My view is that if you’re in the technology business, you should make an effort to understand technology, at least at a high level.
“Only if we understand, can we care. Only if we care, will we help.” - Jane Goodall
SUMMARY
Contextualising value is not necessarily about resolution; foremost, it's about awareness, and then deciding what - if anything - to do about it. Once we can contextualise problems, we may then progress into risk management.
Value Contextualisation comes in two flavours:
- Proactive (Prometheus).
- Reactive (Epimetheus).
One is about understanding your path and (potentially) changing your future; the other is about dealing with the after effects of an unknown and unexpected future (more of a fatalist mindset). The converse of proaction is reaction. Favour Proaction over Reaction.
Many have failed to sufficiently contextualise, or give credence to a problem, and suffered. Business news is rife with stories of failing systems leaving customers stranded, significant data losses causing eye-watering financial penalties (sometimes into the hundreds of millions of dollars), and key systems failing to scale at inauspicious times, angering customers and inducing financial recompense. Business Reputation is at stake.
FURTHER CONSIDERATIONS
- [1] - https://www.cnet.com/news/biggest-data-breaches-of-2019-same-mistakes-different-year
- [2] - A Christmas Carol - Charles Dickens
- [3] - “Some superficial or cosmetic change to something so that it seems more attractive, appealing, or successful than it really is.” https://idioms.thefreedictionary.com/lipstick+on+a+pig
- Value Identification
- Table Stakes
THE PRINCIPLE OF STATUS QUO
Retaining the status quo - meaning the “the existing state or condition” - is important to many businesses.
Whilst many modern books, practices and methodologies place a heavy emphasis on change and innovation at both the technology and cultural levels (i.e. break Cultural Stasis), they tend to neglect to mention the fact that most businesses also depend upon a certain degree of status quo to survive. Innovation tends to be about future success, but stability is about the present situation.
BALANCING FORCE
Sometimes, we are driven so much by what we can achieve, that we forget to ask if we should do it. The Principle of Status Quo suggests that we maintain a modicum of balance between change and stability (Stability v Change).
Most businesses, and customers, can’t manage extreme change; it requires deep and sustained cognitive load, and each change carries an inherent risk. Whilst innovation is desirable, it needs to be carefully judged and managed so it doesn’t impact the current perception of stability. No one I know has (successfully) attempted to transition from Waterfall to Agile in one fell swoop, or migrated from on-prem to the Cloud, or shifted from a Monolithic architecture to Microservices. Change occurs incrementally, not as one big bang, and we maintain most of the status quo whilst undertaking that transition.
Consider - for instance - Agile, Blue/Green Deployments, Canary Releases & A/B Testing. Whilst these practices are certainly a vigorous nod towards progression and change, their approach is methodical and also protective of the status quo, with features like small, incremental change (Agile), fast rollback (Blue/Green), and smart routing to minimise impact on more conservative customers (Canary).
FURTHER CONSIDERATIONS
THE CIRCLE OF INFLUENCE
The Circle of Influence is a way to visualise who (and by what degree) change influences. It can be a useful tool for influencing and negotiation. The figure below shows an example.

The Circle of Influence
- Layer 1 - the least influence; provides the least degree of access.
- ...
- Layer 5 - the greatest influence; everyone has access to the feature.
It takes significant effort to convince others of the need to change (whether that change is how we work, functional, or cultural). People have many different reasons to reject change; from a simple bias, to a lack of understanding, or that they (rightly or wrongly) think the change holds no value. Attempting to convince everyone, in a single big bang change, is doomed to failure. See the figure below. [1]
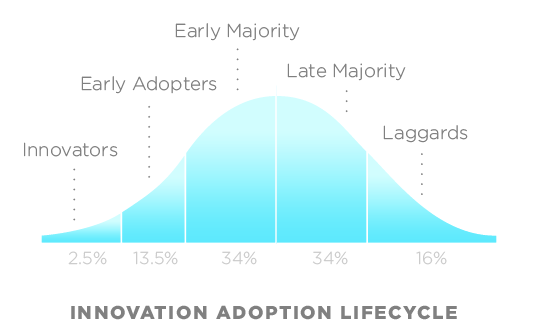
Adoption of Innovation
The graph shows you when change is actioned by different groups. Note it occurs at different times, and has various influencers.
EXAMPLE
At a previous employment I saw an opportunity to make a big difference in the way we built software; yet I didn’t shout loudly for all to hear. It would have been pointless, and may even have hampered the change’s introduction.
I began by influencing my immediate circle (colleagues I worked with on a day-to-day basis), explaining the problem (don’t underestimate the time this takes) I aimed to solve, discussing my proposal with them, and listening to their concerns and improvements, before progressing onto the next stage; a proof of concept (PoC).
This PoC was a success, and gave me and my immediate circle greater confidence that we could expand into the next circle of influence - the wider technology department. Again, there were more discussions, we took improvements on board, extended the PoC, and then took it to the next set of stakeholders (another circle of influence). By the third or fourth concentric circle, we had sufficiently influenced all of the C-level execs to give us the nod to use it for all future work.
If I had approached this big bang, I wouldn’t have found sufficiently strong support to influence everyone. Additionally, the overall solution wouldn’t have gained from the improvements offered by my colleagues.
The solution is to build up concentric rings of influence until you’ve enough motion that there’s no stopping it. But you need to get that stone rolling in the first place; and they can be big.
BIDIRECTIONAL INFLUENCE
Circle of Influence has bidirectional influence. You promote ideas for others to trial, and they agree, disagree, or offer improvements (influence in the opposite direction).
Circle of Influence might be used from internal to external (e.g. customers) influencing, or it might remain internal to the business (e.g. hierarchical influencing). It need not be from least influential to most influential (HiPPO - highest paid person’s opinion); e.g. a cultural change may begin with HiPPOs, but be pushed down to all employees in concentric circles of influence.
ALIGN AROUND A PROBLEM, NOT A SOLUTION
Unless you can explain a problem in a way that the circle truly understands (and I mean truly), they’ll not be able (or willing) to support you to influence the next concentric circle. Forget about explaining the solution until you’re sure they understand the problem.
And even when you think those stakeholders do understand, don’t be surprised when they ask you questions that disprove that theory. You might repeat this four or five times before some stakeholders truly understand the problem, but once they get it, you’ll find the solution just clicks.
Don’t be disheartened. Once people are truly subscribed, they’ll fight your corner. Find enough of the right type of stakeholders, and you’ll have enough sway to influence everyone.
“Only if we understand, can we care. Only if we care, will we help.” - Jane Goodall
Circle of Influence is used a lot (implicitly) in Canary Releases & A/B Testing. They are the means of practicing Circle of Influence.
FURTHER CONSIDERATIONS
UNIT-LEVEL PRODUCTIVITY V BUSINESS-LEVEL SCALE
There’s a lot of focus on unit-level (individual or team) productivity. It’s easy to see, relatively easy to measure (e.g. velocity), and it’s highly contextualised by those individuals in the team affected by it (and therefore championed). Yet, greater unit-level productivity does not necessarily equate to greater business-level productivity (or scale). Beware of focusing too heavily upon unit-level productivity if it hampers business-level scaling.
I’m skeptical of what some promote as wholly good practices (to me, context is key, and no single approach is wholly good, or wholly bad). Take the practice of Technology Choice per Microservice for instance. Whilst selecting the best tool for the job is a sensible practice, few seem to discuss the second or third order consequences, caused by an avalanche of such decisions across the entire business. Could we be harming the overarching business with these unit-level decisions? And if so, where is the tipping point?
Let’s consider Technology Choice per Microservice - a great example of unit-level decision-making - in more depth. The premise is simple; each unit may decide which implementation technology(s) to use, per microservice.
At first glance this seems entirely harmless. It promotes a sense of ownership and accountability within that unit, giving it the stimulus to find the right tool for the problem. However, being ultimately flexible in technological choice also comes with the risk that the overall solution is so technologically diverse (i.e. a complex ecosystem) that (a) comprehension can be hard, (b) security concerns are spread over a wider range of technologies, and (c) moving technical staff across domains is difficult (e.g. Simon may be an extremely competent Java developer, but he has no skills in node.js).
Most systems consist of tens, hundreds, or even thousands of these Microservices. If every unit can select their preferred technologies, we’re promoting a policy where it’s acceptable to increase the complexity of an already Complex System, resulting in even fewer people who can contextualise it in its entirety. The consequence of that, is further system-level (not unit) fragility; you’re increasing the number of moving parts (in the form of software platforms and libraries), and actually reducing your ability to Control change.
Where does one stop? Can that unit also select divergent technologies for logging, alerting, monitoring, or any other metric-gathering tools that could be used to understand aggregated system health? Personally, I’d prefer the ability to measure, analyse, and view in a consistent manner.
There’s also something to be said for Uniformity from a security perspective. Systems with greatly diverse technologies (technology sprawl) suggest an increase in Manageability and Security challenges. Patching many divergent technology stacks for vulnerabilities may be tough, as it infers an increased likelihood that we must wait upon more vendors to release a patch as each learns what to change and how to distribute it.
DEPLOYMENT PIPELINE UNIFORMITY
Modern continuous practices often promote Uniformity. For instance, Deployment Pipelines all look and behave very similarly, regardless of the underlying implementation technology of the software unit, simply because many variations may lead to a decrease in that business’ ability to scale; even when unit-level productivity is greatly improved.
A predominant focus on unit-level productivity can create:
- A patchwork quilt of differing technologies, versions, and skill-sets. This is a double-edged sword.
- Difficulties aligning the entire business (i.e. the units). However, the counter-argument is that aligning the unit may be easier.
- Difficulties using existing resources from other areas of the business, due to a great divergence of skills and knowledge. This may force you to look externally, or buoy the team with temporary consultants.
- Challenges in the management and security of the overarching system, as there’s a wider suite of technologies to understand and analyse how to secure them (I still see a lot of centralised security teams in businesses, so you’re not necessarily gaining their expertise JIT).
- Further specialisms in bottleneck (constraint) units. Considering Flow; if we knew this unit to be our constraint, would we attempt to improve productivity, increase capacity within it, or do both (they’re two slightly different models; see Efficiency & Throughput)? If we opt to improve the existing unit's productivity, we should be cautious not to introduce further scaling constraints to that bottleneck. To rephrase, we can certainly increase the efficiency of what currently constitutes that unit, but if it remains a constraint post-change, and we've reduced our ability to scale that unit up by selecting an esoteric technology or practice, then we may have exacerbated the situation. Making a unit efficient reduces waste, but it doesn't necessarily equate to greater throughput, or sales.
- More reliance upon capacity planning. Depending upon the form of divergence, you may be limiting your ability to scale the unit, solely to the resources available in the unit, which you must then manage more closely.
- Reinventing the wheel. If there are aspects of a job, or techniques that are identical across all units, should a business re-invest for each unit to build their own interpretation of it (which will almost always be sufficiently different to produce hard-to-identify inconsistencies in “the overall system”), or should that be a shared responsibility? Shared libraries (written in one language/platform), Deployment Pipelines and Role management are good examples of this. For example, should each unit be able to reimplement a suite of existing core libraries to function with their choice of technology? Or should each unit construct their own deployment pipelines, even though each is almost identical? The costs aren’t solely around implementation either; regression testing how the new component functions in the entire system, for instance. Is this strategy solving real business problems?
HOW DO YOU CHOOSE?
The benefits of unit-level productivity upon a business can be highly attractive. And whilst there is often a case for a unit to have complete autonomy, and not be too considerate of the overarching business, it really depends upon the context. And if that statement holds true, then conversely, there must also be cases where an improvement within that unit (individual/team) doesn’t equate to a more successful business.
Before we discuss how we might choose when to increase the efficiency of that unit, I suggest a quick refresher on the differences between efficiency and throughput (Efficiency & Throughput).
As discussed in that section, increasing the efficiency of the unit - by introducing a different technology or technique - fits more closely with a vertical system scaling model (than a horizontal one); i.e. you’ll increase Productivity, and also gain some throughput increase. If your goal is to reduce waste, then this may be a sound investment. However, let’s say your goal is to significantly increase throughput (as it’s a major constraint in Flow). In this case, by focusing on efficiency, not only may you still reach a hard limit, but you may also have exacerbated the unit’s ability to scale out.
So, how do you choose when to increase the efficiency of that unit? Let's return to our discussion around Technology Choice per Microservice.
Firstly, let’s assume that the unit has chosen an appropriate technology (it isn’t always the case), which - if implemented - will increase team productivity. Below is a list of questions to help assess the situation?:
- Why do you want to increase unit-level productivity?
- What benefits will it realise?
- Are you doing it to reduce waste, or to increase capacity?
- Are you building something highly innovative? In which case a new technology may be appropriate. However, should you not consider a tried-and-tested technology/approach for more conventional change?
- How many of the team are sufficiently skilled to make the changes?
- If not sufficiently skilled, what’s the upskill cost in time and money? Incidentally, there’s also a cost to not upskilling in the form of poor employee retention.
- What investment is required into that unit to make those efficiency changes, against what proposed return (ROI).
- Do you need to bring in outside help?
- How easy is it to find external talent if it’s not readily available internally?
- Are there any geographic constraints? This one assumes remote working isn’t a good fit for your organisation. For instance, I work in an area with a high propensity of corporate finance institutions. As much of their technology stack is built using Java technologies, many smaller businesses in the area find it very hard to acquire and retain Java talent to work on their own projects, simply because those finance corporations have vacuumed most of them up. Moral of the story - understand the local market before deciding upon a certain technology.
- How divergent is the proposal from the existing business technologies/approach? What effects do you see it having on those other areas?
- What other dependencies are coupled to the change; e.g. new forms of existing libraries, deployment pipelines?
UNIT-LEVEL CULTURAL POLLUTION
There's something else to consider at the unit-level, related to interpersonal skills. In recent times there seems - particularly within some influential tech-oriented quarters - to be a backlash against the incredibly talented, but culturally suicidal Culture Polluters.
You probably know the type. These so called “Brilliant Jerks” are talented and highly-productive at the unit level, and can find innovative solutions to difficult problems. But there’s always a downside... they are a complete nightmare to work with. In extreme cases, they cause such irreparable problems that other teams/individuals must be insulated from them, and those culture polluters are either forced out, or must be ring-fenced to work by themselves.
Were beginning to realise the detrimental effect these people can have on a culture, and thus on a business’ success. “Brilliant Jerks” can affect a business’ ability to grow and scale. It’s another example where the promise of unit-level productivity (said jerk) is disfavoured to make way for a much broader cultural improvement [1].
If we only look at unit depth, we’ll see highly-productive people; but if we look more broadly and wholly, we’ll witness a dysfunctional business (e.g. people not able or willing to communicate, ideas and innovations from other quarters quashed before they have the opportunity to grow, and a lack of camaraderie, trust, and collaboration).
It’s easy (and seemingly smart) to install these individuals into key business domains and positions - they are after all very good at their job - to the point where you’ve committed the cardinal sin of embedding an irreplaceable Single Point of Human Failure into a key area of your business. At this juncture, you’ve little choice but to retain them, no matter how difficult or horrid they are to others, as you simply can’t replace them. The outcome of this is likely to be lost talent (as colleagues leave), and the hampering of new talent acquisition (as word gets around about your culture).
SUMMARY
To clarify, I don’t advocate a blind investment in unit-level productivity without regard to context, and thus, understanding the wider business ramifications. Whilst the intent of most unit-level decision-making (e.g. Technology Choice per Microservice) is good, beware of “too much of a good thing” (in this instance creating an unmanageable technology sprawl).
Conversely, whilst Uniformity is extremely potent when dealing with similar, or conventional tasks, it may lack what’s needed for radical change and innovation (which is where unit-level productivity can shine). You - with a mind both on technology and the business (i.e. sufficient context) - are best placed to decide when to favour radical change over convention.
I reiterate the following philosophy throughout this book. To make better decisions requires two things:
- Caring sufficiently to truly understand a problem, and its context.
- Balance. There’s rarely - if ever - a silver-bullet solution. A solution which seems wholly advantageous on first glance, can have second and third-order consequences that aren’t necessarily perceived until many years later. Don’t fall into the trap of believing there are no consequences to a decision.
Balance the need for units to grow and learn, against the cost (monetary, time, or cultural) for the business to support many diverging units. I’d recommend avoiding the extremities (you always do it one way, or you have too many methods to count) and use the Goldilocks Gauge (not too little, not too much, just the right amount).
Finally, beware of Marketing Magpies - individuals attracted to modernity and marketing propaganda, for the sake of modernity over necessity. These individuals are often influential, have strong backing in the form of some evidence (but it’s rarely contextualised since it originates from external sources), and may promote unit-level gains whilst forsaking overarching business needs.
FURTHER CONSIDERATIONS
- [1] - Brilliant Jerks
- Efficiency & Throughput
- Microservices
- Marketing Magpies
- Culture Polluters
- Single Point of Human Failure
EFFICIENCY & THROUGHPUT
For the sake of completeness, I’d like to discuss the differences between efficiency and throughput (or capacity).
Dictionary.com defines “efficiency” as (I’ve bolded the key words):
“the state or quality of being efficient, or able to accomplish something with the
least waste of time and effort; competency in performance,” or alternatively,
“accomplishment of or ability to accomplish a job
with a minimum expenditure of time and effort...”
Efficiency, therefore, is about expending as little time or money on a task, by performing it so well that there are minimal wasteful activities. You can improve efficiency by reducing waste, thus reducing expenditure (i.e. better ROI).
Throughput, though, is different. Dictionary.com defines it as (I’ve bolded the key words):
“the quantity or amount of raw material processed within a given time, especially the work done by
an electronic computer in a given period of time.”
The focus here is not on reducing costs per se, but about increasing the system’s overall Flow, by increasing the capacity of a key area of that system.
The concept of increasing business unit (an individual, or team) efficiency or throughput (increasing its ability to scale) isn’t vastly different to how you might improve a software system’s efficiency or throughput (Performance v Scalability).
You can increase system capacity in two ways:
- Vertically. Also known as scaling up.
- Horizontally. Also known as scaling out.
You can scale vertically on a single node by either (a) increasing hardware resources or (b) by improving the runtime efficiency of how the software on that node functions. The trouble with vertical scaling is that you may still reach the node’s maximum threshold and can go no further.
You can scale horizontally, not by improving efficiencies, but by adding further nodes (hardware instances), and delegating work to those nodes in a distributed manner. This form of scaling is more potent (but more complex) than vertical scaling because there’s no theoretical limit.
Increasing business unit-level efficiency - by introducing a different technology or technique to an established team or individual - fits closer to the improvement to runtime efficiencies, described in the vertical scaling model; i.e. you’ll likely increase that business unit’s productivity, and - to some extent - increase throughput (whilst you can increase throughput solely by increasing the efficiencies of an existing business unit, it is limited to whatever that business unit can manage), but you might still reach the maximum capacity of that unit. This may be fine if your goal is to reduce waste but may not be if your goal is to significantly increase Flow.
FURTHER CONSIDERATIONS
CHANGE V STABILITY
“And then He created rapid change, and all cheered, excepting the ops.” :)
The technology industry (in particular) has a problem - the continual friction between the two competing forces of change versus stability.

The industry moves incredibly fast. The future success of a business lies with the need for “change” in order to innovate and stay ahead of the competition. Innovation holds risks, but also has the potential for massive reward. However, the sustainability of most established businesses depends upon their ability to maintain a set of stable products and services to existing customers. Most established businesses need the best of both worlds; the “do cool new stuff, but don’t disturb the status quo” philosophy.
These conflicting forces can also create challenges internal to a business (Cultural Friction). The traditional centralised team and departmental structures of many established businesses may create groups that foster conflicting opinions, or even goals; i.e. whilst the overarching business is fostering/promoting change (acted out by adding new features); the traditional (centralised) Operations teams - responsible for maintaining stability in production systems - really desire stability (they’re the ones who get woken at the witching hour by alerts due to a failing system).
The centralising of teams tends to centralise mindsets too. Change - no matter how small - risks instability, and thus causes Change Friction. A group focused on delivering rapid change will attempt to drive it forward with increasing rapidity (sometimes too quickly), whilst a group focused on stability can create a stalwart defence against (rapid) change, and may be disincentived to do so. A business needs a balance of both.
This friction will remain so, ad infinitum; so what can be done about it? To my mind, there are several methodologies, cultural fits, and practices that can bring balance, including:
- To generalise, big changes create a big stability risk; whilst small changes create a small stability risk.
The following practices fit into this category:
- The Agile methodology. Deliver small, incremental change, regularly, that have less risk embedded within them.
- Continuous Practices (Delivery, Integration). Integrate and deploy often with small changes.
- Canary Releases & A/B Testing. Introduce change through a Circle of Influence (minimising the impact to stakeholders), Fail Fast, and faster learning. Our ability to learn with each expanding circle of influence allows us to change course, and ensure we only build the minimum (the MVP) required to meet demand. This approach keeps management overhead to a minimum, thus promotes stability by only managing what we must. The best way to debug software is to not have that software in the first place!
- Blue/Green Deployments. We can introduce incremental change yet still support stability in the form of a rollback. Applying Expand/Contract can also benefit us.
- Cross-Functional Teams. Breaks down some of the barriers caused by centralised teams, enabling skills, ideas, and concerns from various quarters to be addressed early.
FURTHER CONSIDERATIONS
- Change Friction
- Agile
- Principle of Status Quo
- Blue/Green Deployments
- Continuous Delivery
- Canary Releases and A/B Testing
- Cross-Functional Teams
- Circle of Influence
- Fail Fast
FEASIBILITY V PRACTICALITY
“Many things are feasible, not everything is practical.”
The technical feasibility of something is neither a good indicator that it should be done, or that there is the capability to do it.
Let me offer an example. A (service provider) client once gave me a job to investigate options to replace parts of their existing internal product. The options on the table included integrating with several external sources, or building out the functionality internally (i.e. the Build v Buy dilemma). After initial discussions, it became clear that key business stakeholders were already preparing for an external (Buy) solution, reasoning that it would be a straightforward integration, and the business would realise the benefits of fast TTM. My role was to offer some technical due diligence of the options, and “determine their feasibility” (that was the requirement).
The thing is, as I delved deeper, I found that all options were technically feasible (I apologise for my pedantry, but that was the requirement). The question was far too vague to sensibly answer. It was quite possible to successfully integrate the product with any of the Buy products - given sufficient time and money - but not one was practical.
There were several key concerns:
- Many of the external Buy options performed the same functions as key parts of the product being replaced.
This raised the following strategic concerns:
- If the business embedded a purchased product into their own platform, and then sold that product onto their customers, would that decrease the perceived value those customers placed in the overarching product, and dilute the business’ market differentiation?
- If the target (partner) system functioned similarly to the one being replaced (maybe even better?), would the business depreciate their perceived value (and reputation) in the eyes of its customers?
- Might those customers be enticed into discussions directly with those partners and cut out the middle-man?
- In what ways could this approach benefit that partner business, whilst hindering the client? Credibility, for instance. Could that partner become a more formidable competitor? Would they become less willing to fulfil the client’s business needs as they grow?
- (Prospective) customers have the right to question which partners the business selects (particularly if data resides with an additional party in another part of the world). Expanding data capture activities to more parties, potentially across distinct geographical zones, could create sales tension (e.g. European Data Capture Rules).
- As I later discovered, not all business stakeholders agreed with this strategy (i.e. handing over a “Crown Jewels” function to a potential competitor). Shouldn’t the decision around technical feasibility have been drawn up after the strategic decision was fleshed out? In this case there was little point in undertaking technical due diligence when key business stakeholders couldn’t agree on the strategic approach.
- The business began aligning itself more closely with an Aggregator model. Whilst this isn’t necessarily bad, aggregators tend to have less Control of the solutions they aggregate (integration-heavy rather than function-heavy). This represents a problem to any business building bespoke client solutions.
- Aside from all the strategic questions were serious integration issues, due to a large Functional Intersection. Because both the client product and the Buy options were composed of many tightly-coupled components (with tight data-coupling expectations too), the systems made many Assumptions about the existence of dependent domain entities (populated), before the key function could be of any use. Retaining consistency would require a double integration (bidirectional in some cases), across all dependent domain entities. By the time everything was integrated, the client would have lost the benefit (i.e. the supposed TTM benefits didn’t exist).
- Bespoke behaviours couldn’t be easily addressed. Partnering with another involves some level of trust. Control is another factor. If you partner with a big player, you can’t expect them to regularly dance to your tune. If bespoke responsibilities now lie with a partner, how do you ensure they’re acted upon by a partner who doesn’t necessarily have the same context, or care for it, like you do?
My point? Being asked what’s feasible does not necessarily correlate with what’s sensible. You can do almost anything; the first question is should you?
FURTHER CONSIDERATIONS
CIRCUMVENTION
Circumvention - meaning “to go around or bypass” [dictionary.com] - can create reliability and consistency problems across a businesses. It is often the result of Reaction, leading people to action change quickly (to remediate some impending doom), but never following it up with a more permanent, sustainable solution. Circumvention changes may be easily forgotten, insufficiently promulgated, or are unable to be tackled (particularly if reaction is second-nature to that organisation), leading to Technical Debt.
WHEN CIRCUMVENTION BECOMES THE NORM
Watch out for circumvention practices that become the established norm. Each circumvention embedded is like a tick, slowly poisoning your bloodstream; debts accrue in the form of additional complexity, reduced TTM, and increased Single Point of Human Failure etc.
Common examples of Circumvention include:
- Circumventing coding standards. This may lead to misunderstandings, and maintainability/productivity issues.
- Circumventing a deployment step, or configuration. This may cause inconsistencies and increase risk (in the current, and subsequent, releases), affecting Resilience, increasing downtime, and adding confusion. It may also reduce TTM and ROI.
- Circumventing performance tests. This may - for instance - be used to ensure a product is released in time (i.e. release expediting).
- Circumventing security best practices. Again, this may be due to expediting (e.g. to present a new product at a key convention), but never being followed up with remediation.
- Circumventing test best-practices (e.g. TDD / test automation). You’ll still get functioning software, but it’s probably less robust, and future changes are harder (no Safety Net).
SUPPORTING CIRCUMVENTION
Whilst conformity typically leads to convergence, circumvention can lead to such diverseness in practices that the practicalities of supporting, or offering support to a highly circumvented process, are severely hampered.
Circumvention might best be explained with a story... Andy has recently joined the company in an IT Operations role. Whilst an experienced IT systems operator, Andy has no business domain context, but has been asked to deploy a new software release into production.
For the sake of argument, let’s say the release is a monolithic software application, with very little in the way of deployment automation. The deployment consists of a number of “build instructions”, crafted over many years (of blood, sweat, and turmoil), and now runs to over three pages in length. The table below represents part of those instructions.
| 1. | Copy .zip file to xyz directory. |
| 2. | Change Directory to the xyz/web directory. |
| 3. | Unzip the archive (e.g. unzip ...). |
| 4. | Rename the directory to web-deployment (ensure it’s case sensitive). |
| ... | ... |
| 97. | Delete the temporary files in xyz directory. |
| 98. | Configure the system variable “bob” to be the value 10. Explanation: it needs to be greater than 9 to allow the application to start up correctly. |
| 99. | Tail the log file and check the web server started up correctly. |
| 100. | Configure the system variable “bob” to be the value 5. This is the correct value, but can’t be set until AFTER the application is started up. |
| ... | ... |
| 200. | Done! |
The process is somewhat protracted, taking several hours to complete. And whilst most instructions are exoteric, Andy finds some highly contextual and esoteric. For instance, whilst steps 98 and 100 are imagined, I’ve seen many examples of these seemingly nonsensical instructions required for some key system to function as expected. These steps are examples where Circumvention has become an established practice.
These instructions are abstruse, and nothing has been done to remedy them. Andy should - quite rightly - question the veracity of these instructions.
In this case Andy misses step 98, and completes the remaining steps unaware of any problem. It’s not till step 200 (e.g. 3 hours later) - when the entire system is deployed and configured - that he finds it doesn’t work. It’s a further two hours (plus an additional Ops resource) to track the problem down to a single missing step. It’s certainly not Fail Fast. None of this is Andy’s fault; it’s a problem with the process (it shouldn’t be so manual, onerous, and filled with circumvention), rather than the person.
Finally, we may find that once embedded, Circumvention is rarely questioned. How do we know these steps are still relevant? They were required when first recorded, but they’ve been taken for gospel ever since, yet it’s quite possible they no longer affect the outcome (just muddy the waters). As no-one has time to check their relevance, they continue to add unnecessary complexity, worry, and slowness.
SUMMARY
As I mentioned at the start, Circumvention is often the result of Reaction, leading people to action change quickly (to remediate some impending doom), but never following it up with a more permanent, sustainable solution. This approach is then repeated as each reactive measure is required.
Circumvention could occur anywhere in the product engineering lifecycle. For instance, circumventing performance tests will eventually lead to the introduction of poorly performing software (which can hamper several business qualities) - yet problems can remain dormant for a long time. This mindset may even pollute a development culture; i.e. if writing performant software is perceived by key stakeholders to have little merit, would some developers rest on their laurels (and why would junior developers know any different)?
At some stage, we reach a tipping point, where more is invested (both in time and money) to work around this proliferation of circumventions, accumulated over time, than it would take to permanently solve the problem. This, inevitably, leads to poor TTM, waste (poor ROI), embarrassment, and even Branding issues.
FURTHER CONSIDERATIONS
LEARN FAST
“If fail we must, let us do so with haste.”
Purview the business section of any decent bookstore and you’ll find many independent publications all singing the same tune - failure is not only an inevitability, but an important quality to (eventual) success.
Late learning - in any form - is a problem in a world dominated by Ravenous Consumption, whether related to late success (i.e. you could have achieved greater success, sooner), or of late failure (i.e. you’ve burnt lots of cash on worthless features).
EMBRACE FAILURE, BUT BE INTOLERANT TO ITS LATE DISCOVERY
We must learn to embrace failure as part of the path to success, whilst being intolerant to its late discovery - i.e. if we must fail, let’s do so quickly.
We can ill afford late learning with Ravenous Consumption nipping at our heels. Its counterpart - Learn Fast (which Fail Fast is a subset of) - has several redeeming qualities:
- It reduces waste, and thus improves ROI, by not burning cash on inconsequential features.
- It promotes adoption of the “do the right thing, over the thing right” mantra; creating a loop of fast feedback and experimentation, provoking faster (yet more accurate) decision-making (to pivot, or to plow on) based upon measurable outcomes.
- It increases Temporal Optionality (you can expect more options around timing, such as when to deliver an important release). Timing can be crucial. Even superior products, delivered late, can fail in the face of a highly saturated market. Strategy - as any military strategist will tell you - is about applying the right amount of pressure, at the right time, to the right area. Get it right, and it can have astonishing results. Learn Fast widens your options, better enabling you to find the gap and leverage it.
With Learn Fast, I’m looking to test my assumptions, identify surprises (which might take me down an entirely new and untraveled path, or prove an approach unviable), and compare them against my preconceived notion (and possible Bias) - which may sit at odds with reality. I don’t wish to over-invest in any single untested idea until I have greater knowledge and (therefore) confidence in my approach. In software products this typically involves doing the minimum possible to (safely) distribute an idea (e.g. deploy it into a production environment), where it can be measured and studied.
Learn Fast mitigates some of the risk associated with building out an entire solution, only to find it doesn’t function in practice. Both the foundations of Agile, and of continuous practices, are based upon this principle. For example, we learned to associate Waterfall with risk, due to its Big Bang Delivery approach and protracted learning, so favoured small increments of value.
Embedding this principle within a culture can also have beneficial results. For example, Cross-Functional Teams (diverse units exhibiting a variety of skills, experiences, and thought processes) provide a form of Learn Fast, simply by aligning these diverse groups, sooner. This style of team is regularly cooperating and communicating, fleshing out prototypes, negotiating MVPs, building out coordinated value in small increments, and discussing areas of contention much sooner. Diversity speeds learning.
FURTHER CONSIDERATIONS
GOLD-PLATING
Good artists have two important characteristics:
- They have a flair for creating exquisite works.
- They know when to stop work.
The first point needs no further discussion, so let’s consider the second.
Good artists have a keen sense of when a work is complete. They're also acutely aware that - after some point - any further change may actually decrease their work’s value. This cessation of activity at a key juncture also has another important quality - it prevents them making any further (unnecessary) investments with no sensible return. In the technology world we term this unnecessary over-investment as “gold plating”.
Like an artist (which - by the way - a software developer is a form of), technology staff can get carried away. It’s easy to lose sight of the wood (business value), whilst navigating around the trees (technical detail). To my mind there is a large proportion of technologists who either have an unhealthy Refinement Bias, or who struggle to identify the next right thing to do. However, it’s also a tricky subject, particularly if we consider that the idea of “doing it right” can vary greatly, and that Quality is Subjective.
Good technologists however, are also acutely aware of spend. One eye rests on the technology, whilst the other is continually reassessing the change in terms of business benefit and spend. Good technologists know when to stop refining and tackle other concerns.
SMALL STORIES COUNTER GOLD-PLATING
If you’ve ever worked in an Agile manner, you’ll be aware of the drive towards delivering small, cohesive stories.
There’s many good reasons to keep stories small and focused. One benefit being their ability to hinder the hidden gold-plating activities that can pop up in larger projects. Note that I’m not suggesting you shouldn’t Refactor, only that you should not continually refine something well past the point of no return.
To conclude this section, I’d like to recount a story. Some time ago, the company I worked for hired a software engineer to bolster our small team on a software project. Soon after his arrival we started finding unexpected changes to our source code that occurred overnight; we tracked them down to our new joiner.
Now, the original code wasn’t that bad, so whilst we were a bit skeptical, we agreed to incorporate the minor improvements he made. He obviously enjoyed making these refactorings and had a lot of time on his hands (hence the out-of-hours commits).
Soon after though, we’d arrive in the morning to find significant code restructurings. What was worse, it was debatable whether his changes offered any improvement. What began as a minor infringement soon became a major source of contention within the team.
Remember, every change should go through the rigours of the engineering lifecycle before it is accepted, and these were the days before automated deployments and testing went truly mainstream. We found ourselves undertaking a raft of additional activities (e.g. deployments, regression testing) solely to verify the previous night’s “refinements”. This didn’t add business value, slowed our velocity, polluted our culture (the team found the approach uncollaborative), and detracted us from our goal. We concluded that his time was better spent on building new functionality than refining thoroughly adequate software.
This was the ultimate form of gold-plating; where a set of refinements actually slowed progression towards an important business goal, wasted cycles, and created unnecessary cultural friction in a close-knit team.
FURTHER CONSIDERATIONS
GOLDILOCKS GRANULARITY
“Not too coarse, not too fine, just right.”
Granularity is an important, and sometimes overlooked aspect of software design and engineering. It relates to how we define responsibilities, and how we propose that consumers interact with our software. Selecting the wrong granularity can place unnecessary burdens on both the solution and its consumers.
FACADE
The Facade Design Pattern hides complexity from consumers by acting as a higher-level intermediary. This intermediary exposes a coarser-grained public interface to consumers, whilst hiding the finer-grained interactions (the ones the consumers would have made themselves) internally. Not only does Facade hide complexity, it may also improve Performance and Evolvability too.
API design offers us a good example of the importance of granularity. Expose too fine a grain of API, and risk a “chattiness” that causes performance (latency) issues (a process making many remote interactions can cause substantial performance degradation), the embedding of too many Assumptions in the consumers that it affects Agility (such as tight coupling on the sequencing of a workflow), Resilience concerns (more network interactions increase failure risk), data consistency concerns (e.g. a business transaction is left in a partially complete state), and scaling concerns (e.g. the network/server processes n individual requests when one would suffice).
On the flip side, make them too coarse and we risk placing too many Assumptions within the APIs themselves. This makes them incohesive, they may suffer from poor Flexibility/Reuse in different contexts (i.e. lower our ROI) and Maintainability problems, and may even suffer from Integrability challenges (around comprehension and common-sense).
FAULT-TOLERANCE OF COARSE-GRAINED REMOTE INTERACTIONS
Coarse-grained communications promote greater reliability as they are (generally) over sooner (less network interrogations) and have fewer opportunities to fail due to network instabilities.
Let’s look at a dialogue now (between Lisa, the integrator; and Jeff, the API Service provider). Whilst fabricated, this conversation is based on several I’ve experienced.
Lisa (Integrator): “Hi Jeff, I have a question about API x that I’m trying to integrate with. The API contract says that field z is mandatory. Why must I pass this data in? It makes no sense and I don’t even use it anyway...” Jeff (API Service Provider): “Sorry Lisa, it’s part of the API contract. I know it doesn’t make much sense, and you don’t need it, but we need it to make the flow work, so please can you add it.” Lisa: “Could you not just change the API to make it optional?” Jeff: “Sorry, but other consumers rely upon it being there and we can’t change it. Sorry.” Lisa: “Ok, could you create me a new API just for what I need? Also, I’ve noticed a few other fields that don’t make sense either.” ... Dialogue proceeds. ... Jeff (soliloquy): Lisa is absolutely right, yet I can’t say that. I don’t even understand why we need to support these fields myself. I wasn’t around when this decision was made, and no one seems to remember the reasoning. All I know is that passing it in makes our APIs work. I hope I don’t get any more of these difficult questions...
This is not a good conversation to have with a customer (which the integrator may represent); nor is it customer-focused. It resembles a tennis rally where there’s no winner, just two deeply frustrated people (where one side asks reasonable questions but gets nowhere, and the other is focused on fending them off rather than offering helpful solutions). These sorts of conversations reflect poorly on the API service provider. Both the messenger and the overarching business look foolish, and customers lose respect and confidence in both you and your offering (Reputation). Whilst not the only cause, in this case, (overly) coarse-grained responsibilities was a major factor.
TABLE-LEVEL VIEWS
I've worked with several solutions that coupled the UI forms (and navigation) directly to the underlying database tables. Whilst extremely fast to build (RAD), in the main they were:
Coupled the user experience directly to how those underlying table structures were navigated. This was both inflexible and created Evolvability challenges.
- Unintuitive. It was so easy to expose the underlying data structure that everything was presented, regardless of its relevance.
- Unnecessarily complex, and therefore, unproductive for the user.
Unlike my previous example, this one was caused by the granularity being too fine. It’s worth noting that further iterations were much better received; in the main because they hid this complexity behind facades, and managed the flow for the user.
One final reflection. Please note that I’m not advocating one option over the other. It depends upon the context, and why I advise the practical application of Goldilocks Granularity.
FURTHER CONSIDERATIONS
“SHIFT LEFT”
To Shift-Left is a popular phrase in modern software businesses. It simply means the practice of (sensibly) moving work items to earlier in the current flow. This practice allows problems to be identified, thus gaining valuable feedback that can increase business Agility (allowing you to change tack, pivot etc).
Examples of Shift-Left include:
- Cloud provisioning. In the old days, it could take months for a dedicated team to find the capacity to provision a new infrastructure. In these cases, developers were either forced to wait for access, or find ways to Circumvent the process. The Cloud has provided a facility to more quickly provision an environment (by lowering the representational gap), thus placing less dependence upon overworked teams.
- Embedding automated testing earlier in the development lifecycle. For instance, embedded web servers and Maven plugins enabled me to build software from more of a TDD mindset. This activity built in quality earlier, and increased my overall productivity. [1]
- Involving technologists/engineers in all aspects of the business, such as in early sales negotiations
with prospective customers. The value here is twofold:
- Technologists get early sight of the proposal and can support/influence it.
- It prevents sales staff from making unrealistic promises for the sake of a sale.
- Including non-functional testing in Deployment Pipelines. For instance, incorporating performance and security testing into the pipelines gives us early feedback and improves quality.
- Cross-Functional Teams. Arranging teams from people of diverse skills and experience allows more informed decisions to be made, sooner.
FURTHER CONSIDERATIONS
- [1] - However, whilst this means we can test sooner, I disagree with the principle that we can simply replace testers with development staff (testers bring a different mindset to a problem).
- Circumvention
- The Cloud
- Deployment Pipelines
ECONOMIES OF SCALE
Economies of Scale - the act of gaining competitive advantage (by increasing the scale of operation, whilst decreasing cost) - is often used to gain competitive advantage by:
- Protecting your assets from competitors.
- Reducing pricing through greater efficiencies and better bargaining power.
- Incentivising existing customers to buy more, at a cheaper price, than if those customers had to source them independently.
When one company acquires another, that business typically swallows up the other (including its employees, products, and customers). The acquiring business benefits in three ways:
- It may now offer these newly acquired products and services to its own existing customers.
- It now has a larger, more diverse, customer-base to offer its current products and services to.
- There’s one fewer competitor in the market.
One way to achieve Economies of Scale is to follow the Growth through Acquisition model.
FURTHER CONSIDERATIONS
GROWTH THROUGH ACQUISITION
While some businesses have succeeded in growing through this model (Economies of Scale), it’s a difficult one to sustain. I believe a key cause for this long-term failure relates to Technical Debt, and an unwillingness (or inability) to consolidate technologies.
Let me elaborate. With each new acquisition comes technical baggage (or debts if you prefer). They may take the form of incorporating in a multitude of systems (built to mimic that business’ bespoke practices), or non-standardised data-sets meant to capture similar but slightly different information, to how the acquiring business captures it. It could possibly be the inclusion of divergent technology stacks, Circumvention, or the thought processes and cultural ethos distinct to that acquired organisation. It’s rare that any sizable acquisition involving technology doesn’t come with these idiosyncrasies.
As the rate of business acquisitions displaces the business' ability to pay down the technical debt, we find some businesses forced to manage hundreds of discrete applications that often do the same thing, or are only slight variants on what others already do (i.e. they function in the same role, but capture different information, or use a slightly different implementation or integration model). They all make Assumptions about their operating environment. How many different ways of capturing customer information do you need?
THE RISE IN INTEGRATION PROJECTS
Many projects have been initiated solely to manage an integration of systems between two historically competing, but now merged, businesses.
A forceful growth through acquisition strategy can have consequences upon technology, leading to deceleration, cultural fatigue, and innovation stasis. One answer is the Acquisition / Consolidation Cycle.
FURTHER CONSIDERATIONS
GROWTH WITHOUT CONSOLIDATION
“It’s always easier to start something than to finish it.“
Over the years I’ve witnessed several failures in business strategy, caused by an unwillingness (or neglect) to consolidate technology, leading to poor business Agility, and subsequently, poor growth. They are:
- Failure to consolidate after undertaking a product replacement strategy.
- Failure to consolidate a product(s) after a merger or acquisition.
LACK OF CONSOLIDATION
One of my biggest concerns within some businesses I’ve worked with is the lack of Technology Consolidation. Rather than solving this problem, there’s a keenness to make another new thing, supposedly to replace the legacy. Yet the retirement work seems to almost always be overlooked (Value Contextualisation), or shortened, to make way for the next big thing, and consolidation never occurs. The result is a vast (and often unmanageable) technology sprawl.
Let’s discuss them.
1. CONSOLIDATION AFTER PRODUCT REPLACEMENT
Consider the following scenario. You work for an established business, providing services to a wide range of customers. The business’ current product has sold well, but it’s now aging and something modern is required to appeal to both existing and new customers. So... you start building a new product.
The business intends to migrate all customers from the old system across to the new one. However, there are two problems:
- Building the new solution will take years.
- Existing customers must still be supported; this includes functional change and extension on the old product.
In the past, I’ve seen monolith after monolith created to satisfy this business desire. Each monolith uses (at the time) modern technologies and techniques, yet the net result is the same. The products diverge to a point where the migration effort is unacceptable, and multiple products must be maintained forevermore. In the worst case, we may see these monoliths combined to form an aggregated monolith, and may even become a Frankenstein's Monster System.
There’s a fair chance that the business never performs the consolidation phase, so their customer base becomes strewn across multiple applications, causing (operational) management and coordination issues, and with each successive feature added, exacerbating any prospective migration plan.
2. GROWTH THROUGH ACQUISITION
Consider the following example. CoreTech is a business wishing to expand their presence into other regions, and thus become more profitable. They currently offer software products A and B, mainly to a core US market. In the following months they successfully broker a deal to acquire a smaller, European-centric business, called WolfTech, to bring their product (product C) and specialties under CoreTech’s umbrella.
CoreTech now has gained three key benefits:
- They have a more diverse product portfolio to offer customers.
- They have more customers, thus (hopefully) more profit.
- They now have a presence in another region (Europe) to sell their products/services.
Sounds appealing doesn’t it? But there’s some disadvantages.
The products on sale are software applications. We now have three products (good); however, some aspects of those products perform the same function, such as capturing customer details (bad).
As new customers are on-boarded, we find most only need parts of each product. Let’s say a prospective customer (propellor.inc) needs these features to form Product D: Users, Customers, Products, Portfolios, Ledgers, Carts, Discounts. See the figure below.
Note that these features touch all of CoreTech’s products. From a business perspective, this seems OK, so we offer them this solution (product D); why wouldn’t we?
The problem, however, is insidious, and relates to (system) dependency management. To use specific features of each product, we must also manage every one of that feature’s dependencies. For instance, all three products depend upon the existence of user and customer representations, regardless of whether it’s functionally useful, so we must provide them. Some might also comment that we're into the realms of managing a Frankenstein’s Monster System.
We must:
- Deploy everything (all products), to each environment. As each product likely runs on its own infrastructure, we must also manage that additional complexity.
- Wire them all together. A significant and entirely unsatisfying burden, mainly enjoyed by masochists.
- Manage data synchronisation across systems. This is a key challenge. We now have three customer representations (one for each system, but all doing the same job) that we must keep synchronised (possibly bidirectionally).
- Support and coordinate upgrades and migrations across four systems (the fourth being the aggregator product D). This may involve downtime, Lengthy Release Cycles, and (being legacy) probably also exhibits poor rollback support.
- Secure them. A commonly quoted security mantra is that "you're only as strong as your weakest link". Since there’s a plethora of products and technologies in this aggregated solution, and many are legacy, how do we remove these vulnerabilities and secure everything? Theoretically, we’ve widened our attack surface, and changing the “legacy” is often impractical.
Without consolidation, we find that this approach has forced a complex and risky coordination and synchronization problem onto the entire business (cue Atlas holding up the globe), and what’s worse, it’s probably one that most key stakeholders are unaware of, or cannot contextualise (Value Contextualisation).
THE TAIL WAGGING THE DOG
To clarify, this approach creates a role-reversal, and is a classic case of the Tail Wagging the Dog. There’s no useful business functionality being created. We’re satisfying the system, not the business here, and creating system-level dependencies that the business wouldn’t expect to have to manage.
With the increased complexity, comes:
- Additional staffing needs (i.e. reducing profitability), to manage all products, and to handle the necessary complex integrations. Projects may be initiated solely to manage the integration between these systems rather than building out useful new functionality.
- Additional TTM concerns. Additional complexity means additional care and due diligence is required; sometimes to the point of overthinking every change.
- Data Synchronization and integrity concerns. Spreading essentially the same data across different systems leads to consistency (and the obvious complexity) challenges.
- Poorer ROI. Everything takes longer, so is more expensive. Each change is discussed for far longer and we cause Continuous Deliberation.
- Brittle architecture and deployment/release strategy. If we depend upon legacy architectures and deployments then we may find our modern systems hamstrung by legacy constraints.
- Change control meetings. Representatives from each of the products get together to duke it out in one big Battle Royale. I’m not a big fan of these.
SUMMARY
Whilst it seems like I’m bashing the Growth through Acquisition model, I’m not. I’m attacking the repeated application of this model without a sensible consolidation strategy. Some of the problems caused by neglecting to consolidate are presented here.
When all is said and done, there’s also something to say on lost opportunities. If the business doesn’t acquire now, will it get another opportunity? Immediate acquisition may be pragmatic, and worry about consolidation a bit later. Like much in life, it’s about finding the right balance.
The Acquisition / Consolidation Cycle offers one possible solution to sustained growth.
FURTHER CONSIDERATIONS
- https://medium.com/@nmckinnonblog/technology-consolidation-8c572925b586
- The Acquisition / Consolidation Cycle
- Neglecting to Consolidate
- Value Contextualisation
- Tail Wagging the Dog
- Frankenstein's Monster System
- Continuous Deliberation
- Lengthy Release Cycles
- Data Synchronization
THE ACQUISITION / CONSOLIDATION CYCLE
The steps (as I see them) to long-term Growth through Acquisition are shown in the figure below.
The typical "growth through acquisition" cycle is:
- Acquire new business.
- Sell off (unnecessary) assets.
- Reduce (unnecessary) staff.
- Embed acquired technology and products into the parent product suite.
At this point, it’s very tempting to repeat this cycle, but I’d suggest - for long-term sustainability - you don’t (see my reasoning in the Growth through Consolidation section). You should now consider the consolidation phase; described next:
- Consolidate technology.
- Migrate customers to consolidated technology.
- Reduce unnecessary staff.
- Repeat at step 1.
Let's look at the steps.
1. ACQUIRE NEW BUSINESS
In this phase, agreements are made, due diligence is undertaken, contracts are signed, and the business is acquired/merged. We’ve now got a suite of new technology products to support.
2. SELL OFF UNNECESSARY ASSETS
Any products or services that aren’t deemed of value to the parent business are discontinued, or sold on to others. The remaining products are retained, and ingested into the parent company’s product suite.
The parent company can now offer a more diverse range of products (see later stages).
3. REDUCE STAFF OVERHEAD
An unpalatable one, but it’s pretty typical in acquisitions (and one I’ve been at the receiving end of).
The parent company identifies the necessary staff to support the retained products/services (they must retain some experts to manage that product), and discards the remainder. This is mainly about managing profits.
However, it’s worth mentioning that the parent company’s overall staff levels increase to maintain these products. And - if you’re like many technology companies - most of your outgoings are held with staffing costs.
4. EMBED ACQUIRED TECHNOLOGY INTO PRODUCT PORTFOLIO
In this stage the new product(s) are ingested into the parent company’s product portfolio and can be sold to prospective customers. Additionally, the parent company has expanded their customer-base/revenue from the customers already using the ingested product(s).
The manner in which the parent company now manages its solutions is critical to their long-term success. If solutions are composed from many other large, tightly-coupled (monolithic) applications, then we may have a technology sprawl (a Frankenstein’s Monster System) that can hamper sustained business growth (see earlier).
5. CONSOLIDATE TECHNOLOGY
The consolidation phase is one of the most important. Without it, we may suffer mass complexity, technology sprawl, duplication of effort, and a general delivery and cultural stasis.
THE PARADOX OF GROWTH (WITHOUT CONSOLIDATION)
There’s a potential paradox here. By attempting growth through acquisition, a business may have hamstrung itself with poor TTM, ROI, and Agility, and no longer support good business practices, like reacting quickly to the changing needs/tastes of customers, or building disruptive products. If a business isn’t lean, in terms of technology sprawl and staffing, how can it react to both growth demands, and the need to continually delight existing customers?
WAYS TO CONSOLIDATE
Consolidation isn’t easy, quick, or its value easily contextualised, which is why it is often overlooked. The key thing we’re aiming for is a smaller, cohesive footprint (i.e. less to manage), looking to identify features that perform similar functions, and then finding opportunities to only use a single one.
6. MIGRATE CUSTOMERS TO NEW PRODUCTS
We've now consolidated the technology/product(s) to create functionally equivalent solutions, so we can now migrate the customers on one system to the desired one. Once that’s achieved, we can now retire parts of the old system.
7. REDUCE STAFFING OVERHEAD
Sorry, but this is business, and businesses care about profit. By migrating those customers from the external system onto a consolidated product, we need not support the other products, and thus, we don’t need the staff maintaining them. We can either utilize those staff in other areas of the business, or (legalities aside) let them go; this can represent a significant cash-flow saving.
8. REPEAT
We repeat this cycle. Acquire another business. Sell some products, embed the others. Tidy up. Remove waste. If we’ve been cautious, we’ve minimised debts, and supported sustained growth.
SUMMARY
The cycle infers some pauses after each merger/acquisition in order to pave the way for more, or simply to keep the business in good shape. Without consolidation, you may find your systems getting increasingly complex (Complex System), suggesting a larger (than necessary) workforce, an increase in long-winded, committee-based decisions, and a general cultural stasis.
FURTHER CONSIDERATIONS
NEGLECTING TO CONSOLIDATE
Neglecting to consolidate may cause the following issues:
- A duplication of features to manage; i.e. poor ROI.
- Additional complexities and thus, confusion. Upgrades become a nightmare, so don’t get done.
- An unnecessarily large technology workforce; i.e. eating into profits.
- Resilience issues. Too many dependencies to comprehend (or test) the effect of a change, or a downstream failure.
- Higher ongoing costs. Each change must be discussed in minutia.
- Higher operational costs. Each application needs its own infrastructure. This could also cause branding issues if you don’t correctly scale each system correctly.
- Poor TTM. Additional complexity means additional care and due diligence is required; sometimes to the point of overthinking every change.
- Change Friction. Mainly due to an unwillingness to make a change due to poor stakeholder confidence (e.g. “last time we changed this, it was down for three days, and cost us ten million dollars...”).
- Technical Debt.
- Lack of Innovation. The existing systems suck in all resources, to the detriment of innovation. Additionally, if an earlier incident caused regulator involvement, that involvement can also impact your ability to innovate.
- Uncompetitive. Change takes too long and is too painful. No innovation is being released to the market.
- Cultural Stasis. Difficulties in changing the culture (e.g. an unnecessarily large workforce may increase resistance, or ability, to change).
- Regulator or governmental initiatives (e.g. GDPR-style projects) affecting all systems due to feature duplication; i.e. terrible ROI.
- Security concerns. You’ve a far wider set of technologies to secure and keep secure, across a plethora of different technologies/infrastructure/hardware. Do you have such a diverse range of skill-sets to support them all, or must you employ others (impacting profits)?
- Additional staffing needs (i.e. reducing profitability), to manage all products, and to handle the necessary complex integrations. Projects may be initiated solely to manage the integration between these systems rather than building out useful new functionality.
- Data Synchronization and integrity concerns. Spreading essentially the same data across different systems leads to consistency (and the obvious complexity) challenges.
- Poorer ROI. Everything takes longer so is more expensive. Each change is discussed for far longer and we cause Continuous Deliberation.
- Brittle architecture and deployment/release strategy. If we depend upon legacy architectures and deployments then we may find our modern systems hamstrung by legacy constraints.
- Change control meetings. Representatives from each of the products get together to duke it out in one big Battle Royale. I’m not a big fan of these.
- Poor long-term growth. A combination of all my previous points.
FRANKENSTEIN’S MONSTER SYSTEMS
"I had gazed on him while unfinished; he was ugly then, but when those muscles and joints were rendered capable of motion, it became a thing such as even Dante could not have conceived." - Frankenstein, Mary Shelley.
Mary Shelley's classic horror novel, Frankenstein, tells the tale of Victor Frankenstein, a scientist who tried to play God, and who consequently suffered great anguish and torment from his own designs. His creation is freakish and unnatural, stitched together haphazardly from spare body parts, and animated into being:
"I collected the instruments of life around me, that I might infuse a spark of being into the lifeless thing that lay at my feet."
Up until the creature's terrifying arrival, Victor's belief in his purpose is unshaken - he will peel back the very fabric of creation:
"...soon my mind was filled with one thought, one conception, one purpose. So much has been done, exclaimed the soul of Frankenstein—more, far more, will I achieve; treading in the steps already marked, I will pioneer a new way, explore unknown powers, and unfold to the world the deepest mysteries of creation."
Yet, as the creature awakens, Victor finally grows alarmed, as the magnitude of his error begins to dawn on him:
"...but now that I had finished, the beauty of the dream vanished, and breathless horror and disgust filled my heart."
However, it’s not until later in the narrative that he truly appreciates the horror, as it systematically takes everything he’s ever cared for from him:
"Yet you, my creator, detest and spurn me, thy creature, to whom thou art bound by ties only dissoluble by the annihilation of one of us."
Ok, so whilst dramatic, I feel there’s some similarities to what I say next.
Businesses that have pursued the goal of either Growth through Acquisition, or simply of modernisation, yet neglected to Consolidate, may run into Frankenstein’s Monster Systems.
Like the monster, Frankenstein’s Monster Systems may be freakish and unnatural, stitched together haphazardly into some form that whilst alive, may cause considerable distress, and (if not initially, will eventually) be detested by the overarching business.
WHAT FORM DO MONSTERS TAKE?
In the acquisition sense, Frankenstein’s Monster Systems may have grown up to meet the needs of the (acquired) organisation, may well be monolithic, highly bespoke, and never meant to function as a system within the acquiring business. They’re also likely to be written in a language, or platform, different to the acquirers stack.
The Aggregated Monolith (or Monolith of Monoliths) is a good representative candidate. It’s an approach I’ve seen on at least three occasions, and also a situation some larger organisations have found themselves with.
Let’s consider a case where the business has two existing software applications, and has acquired a further one. Let’s also suggest that all three of these products are established legacy (serving the businesses for at least a decade). As such, they’re Antiquated Monoliths (they need not be, but this is the simplest scenario). Because each application models the overarching business we find many Assumptions made that tightly-coupled components together. This leads to functional duplication across those three applications (such as capturing customer details). See below.

Let’s say we’re merging the businesses into one (in a modernisation project we might also be merging customer bases rather than businesses). We have customer bases in all three applications that we want to offer a new service to (let’s say it’s a stocks-based solution), expecting a large number of these customers will want. We can’t simply migrate all customers onto a single platform due to a lack of Functional Parity (each application offers distinct functionality that the customers are using).
So, we form a new product - Product D - requiring the following features: Users, Customers, Products, Portfolios, Ledgers, Carts, Discounts, Transactions, and Stocks. See the figure below.
Note that these features touch all three existing products, so we must include them all.
Some large corporations have tens, or possibly even hundreds of these subsystems linked together to form one massive one. Which leads me into a discussion around Control.
CONTROLLING THE MONSTER
Frankenstein’s monster could not be trusted, or controlled. Something that can also be true of Frankenstein’s Monster Systems (Complex Systems). The wide variety of technologies and solutions in play can’t be entirely understood, so much so that any unorthodox activity may cause an accumulation of events (a snowballing), that cannot be easily stopped or controlled, and lead to catastrophe.
Businesses that attain new systems (through either model), yet fail to consolidate, may find themselves glueing existing systems together to form an increasingly complex form of Frankenstein’s Monster, to the point that it’s not understood, appreciated, or controlled, with inevitable long-term results. There’s so much choice that it's extremely enticing to reuse any and all systems, rather than applying the Sensible Reuse Principle.
Let’s look at some of the issues.
SATISFYING THE SYSTEM
When you build a giant aggregated solution from lots of other bits, and stitch them together, you’ve still got to satisfy the needs of each sub-system. That involves populating a tree of dependencies (which likely need satisfied in a specific order), first for each subsystem, then for the overall solution.
LEGACY MEANS ENTROPY
Many of these subsystems may be legacy, and Entropy has already set in long ago. Legacy systems come with their own set of baggage (the constraints) that may bleed into the overarching system, polluting delivery capabilities and polluting the business’ culture (see next).
CULTURAL STASIS
If the subsystems pollute the overall solution, then we may find everything we do is brittle and takes forever. In these circumstances, we find people becoming disenfranchised (which may lead to high rates of attrition) and Stakeholder Confidence disintegrates.
Due to the brittle architecture, we may find a small change in a subsystem has a rippling effect on the entire solution (Complex System), and Brand Reputation may be tarnished.
So we stop making changes (it’s just too painful), and slip into a downward spiral, finding it increasingly difficult to compete with highly nimble “startups”.
INTEGRATION MASOCHISM
Integrating is in - Frankenstein parlance - a stitching together of systems. Whilst integration certainly isn’t a bad activity, you should consider what you’re stitching together, and why (Sensible Reuse Principle).
Stitching together dead or defunct legacy systems into the fabric of modern systems may create more problems than they solve, yet it might not seem initially obvious. It’s a question of short-term (tactical) over long-term (strategic) thinking.
SECURING THE SYSTEM
Two commonly used security mantras are particularly relevant here:
- "You're only as strong as your weakest link." Since this aggregated solution contains a plethora of products and technologies, and many are legacy, how do we remove these vulnerabilities from the subsystems to harden the overarching system? Changing the “legacy” is often impractical, and theoretically, by incorporating a legacy subsystem with vulnerabilities, we’ve widened our attack surface.
- "The most secure software is software that doesn't exist." Or restated, software that contains bugs/deficiencies is software that contains weaknesses. And weaknesses can be exploited. Therefore, the best way to prevent buggy or insecure software is not to have it in the first place. Yet, Frankenstein's Monster Systems may expose an undesirable (and unnecessary) amount of accessible/executable code (due to the large Functional Intersection), thus increasing risk.
SUMMARY
Frankenstein's Monster Systems can be symptomatic of Neglecting to Consolidate. These systems can be:
- Slow to change (in many ways).
- Difficult to Control.
- Insecure.
- Brittle, in their architecture and unnecessarily complex (Complex System), possibly creating an accumulation of unstoppable events that leads to a catastrophe.
FURTHER CONSIDERATIONS
ANALYSIS PARALYSIS
Analysis Paralysis relates to an individual, team, or even a business, being paralysed into Continuous Deliberation, and unable to progress, with no sensible path to liberation.
It may be caused by:
- An attempt to over-analyse a problem, especially when that problem is too complex to solve solely through analysis (Cynefin).
- When the outcome is feared.
- When making a wrong decision can lead to a poor outcome.
- When a Paradox of Choice exists, burdening the decision-maker with so many choices that no decision can be made.
- When there are multiple believable decision-makers with opposing views who must be satisfied, typically by analysing all their suggestions.
FURTHER CONSIDERATIONS
- Continuous Deliberation
- Cynefin Framework
CAPEX & OPEX
CapEx and OpEx are two different expenditure models. Capital Expenditure (CapEx) relates to the purchase of (significant) assets that are anticipated to be used in the future, and is seen as an investment by the business. In the UK, CapEx must be recognised on the business balance sheet. Operational Expenditure (OpEx) relates to ongoing operational costs for running a business.
Historically, software projects have utilised hardware, systems, and databases using (predominantly) the CapEx model. In this model, project inception requires the business to either find the necessary kit from an existing source, or to purchase it. Purchasing carries some risk though, because:
- It typically has a high investment cost, and a long (if any) return on investment.
- The people who really need it must wait for its delivery (this could be months).
- Many assets depreciate in value. It’s market value in a year's time will be noticeably less than its purchase price.
- Further (fast) scaling requires us to repeat these steps, causing further delays.
The CapEx model can be both restrictive and wasteful. The lengthy cycle times and setup costs can hamper Innovation. Many start-ups simply don't have the capital to make this type of up-front investment, particularly if that large investment is taken on a bet (any idea that hasn’t yet been proven is a form of betting). It’s a risky venture when you consider ~90% of start-ups don’t survive the first year.
One of the key tenets of the Cloud is to turn all this up-front CapEx investment on its head. Cloud vendors recognise the inhibitive nature of the CapEx model on (overall) Innovation, simply because many businesses can’t necessarily afford a significant one-off investment. However, most can certainly afford to rent hardware and services on a month-by-month basis. This is the OpEx model.
The businesses never own the asset, but receive other benefits, including:
- (Almost) immediate availability of infrastructure and other services. No delivery or installation period is required.
- No requirement for a long-term commitment. Services are rented for a short, extendable period, or stopped. This model offers a lot of flexibility.
- Palatable (at least, initially) investment costs. Payments are made monthly, and can be quickly stopped (or paused) if things don’t work out.
- The low setup time and costs promotes experimentation and Innovation.
- No physical storage or electricity costs for the business.
- Specialist skills to support the services becomes the Cloud vendor’s problem, not the business’.
- The depreciation cost of the hardware becomes the Cloud vendor’s problem, not the business’.
FURTHER CONSIDERATIONS
INNOVATION V STANDARDISATION
Innovation is about rapid change and working through unknowns. Standardisation is more about alignment and creating something shareable from a Known Quantity. They are two competing factors and may need to be treated differently.
NON-REPUDIATION
Non-Repudiation - a party's inability to repudiate an action or agreement - is an important aspect of many transactional systems, and prevalent within legal or financial settings.
Many actions we undertake in life have consequences. Taking out a mortgage, moving funds between bank accounts, signing a minimum-term contract for a gym, or TV subscription package. All of them form some kind of legal contract (or agreement) between one (receiving) party, and another (providing) party.
LOSS AVERSION
Loss Aversion plays a key part in these contracts in that whilst a service is prepared to be offered, at least one party (typically the provider) is averse to the potential loss the other party could incur upon them.
Difficulties arise if one party breaks the contract, causing the other (financial) burdens. The victim may be unjustly affected, so legal proceedings begin. Yet, the contract cannot be binding if one party can successfully refute the agreement (the “I never signed that, where’s your proof?” argument) - i.e. repudiation. Good Non-Repudiation mechanisms make it impossible for one party to refute the authenticity of their action.
ANALOGY
A vehicle Dash Cam (Dashboard Camera) is one real-world example of non-repudiation. If you were involved in an accident with another vehicle, but neither party admits fault, then some other form of evidence can be useful. A Dash Cam makes it very difficult for a party to repudiate the evidence.
From a systems perspective, an API Gateway, Edge Service, or an Intercepting Filter are all good (system) mechanisms to capture non-repudiation proofs; being executed at the gateway to the underlying system or resource. Digital Signatures, Certificate Authorities (CAs), and Blockchain also offer approaches to verify authenticity for non-repudiation.
FURTHER CONSIDERATIONS
- API Gateway & Edge Services
- Intercepting Filter
- SLAs
- Loss Aversion
- Blockchain
SPIKES & DOUBLE INVESTMENT
“Let’s do two spikes in parallel to decide which one is better.”
The premise here is that two spikes are better than one, and that by undertaking both in parallel, we’ll gain twice the understanding. But that’s not always the case, neither is it always appropriate.
Doubling down on spikes to support a decision around Innovation (“is this approach better than that?”) is sensible, but duplicating effort to find the most innovative solution on a conformity project, or an ephemeral solution (we often have to build tactical solutions with limited lifespans when dealing with legacy systems) is needlessly wasteful. In these circumstances, select the best one (based on your current understanding) and only run the other spike if the first produces a substandard result.
FURTHER CONSIDERATIONS
NEW (!=) IS NOT ALWAYS BETTER
A trap I see many technologists fall into is always equating new with better. Whilst it’s often true, it isn’t always true, and swallowing the propaganda of the “new” (e.g. Marketing Magpies) can store problems up for the future.
TERMINOLOGY
I’m describing a multitude of “things” here, including technologies, techniques, and methodologies. However, for brevity’s sake, I’m going to generalise all these concepts under an umbrella term of “tool”.
Firstly, let’s talk about “better”. What is it? How is it measured? And what are we comparing it against? Of course, we could associate "better" with many qualities (e.g. faster development, faster integration, reduced complexity, or standardisation), but the one I’m most comfortable with is how it performs against a set of common “fragility factors”.
If we compare the fragility of two tools, then the one exhibiting less fragility is probably better. To my mind, less fragile tools display these three characteristics:
- The entrenchment factor. It has seen high exposure and extensive use across a wide range of industries, domains, and diverse groups of people.
- It has stood the test of time. This also infers that the tool has vanquished many other competing tools that were less good (more fragile). It's resilient to competition.
- It continues to be championed.
Note also that any tool exhibiting only two of these qualities is not (yet) proof of its superiority. There’s plenty of tools that gained early traction, but were extinct within a few years. There’s also long-standing tools that never received high exposure (becoming the mainstay of only a single domain or industry), and can’t necessarily be considered superior outside of that domain (although that may be of little concern to those domains making good use of them). And something that is deeply entrenched and seen lengthy use may no longer be championed.
A tool that satisfies all three criteria is one that still stands tall, having faced the worst that could have been thrown at it. That’s both sustained “normal” use, and the occasional outlier event that shakes the foundations of an industry (like the Internet, or the Cloud). A skyscraper that withstands inclement weather, sees sustained use by tenants, and is still highly-esteemed, is good, but certainly not exceptional. However, one exhibiting all these qualities and having survived (intact) a significant earthquake is a blueprint for success. A retail business that can scale up and sustain their distribution channels during an epidemic (such as COVID-19) is rather resilient, not so much to failure, but to extreme success.
Some examples:
- SOA & ESBs. As a nascent practice, SOA was lauded as a technological revolution. It certainly had merits, such as the greater alignment of business and technology, and service-focused solutions. It also helped to pave the way for XML to be treated as the defacto data transfer mechanism. Yet nowadays SOA (generally) has derogatory connotations. As do ESBs (Enterprise Service Buses), popularised by the rise of SOA, and now demonised as incohesive, single-points-of-failure.
- Waterfall was once widespread but it’s rarely championed in the software projects I’m involved in (and I suspect many others feel the same). Whilst it was once widespread and championed, it didn’t fully survive the rise of Agile, and then DevOps. One quality Waterfall has certainly passed is the test of time, being ubiquitous for many decades (but then there were few real alternatives).
- Agile has stood the test of time, is entrenched, widely practiced, and continues to be championed.
- DevOps is in some ways the next logical extension of Agile - so is founded upon many proven techniques. Although the signs are promising, only time will tell.
- Java Server Faces (JSF). I really liked this (component-based, web application) framework, but it never got the traction I expected it would. Indeed, its older sibling technology - JSPs (Pages) - may outlive it.
- The Spring framework. As an alternative to the J(2)EE framework, it has gained increasing traction and widespread industry adoption (particularly after the introduction of the extremely good Spring Boot and Cloud frameworks). I still see this as a great option for Microservices, although Cloud adoption may take a bite out of that cherry.
- HTTP has seen a few major iterations, but it’s widespread adoption, entrenchment, flexibility, and continued championing have ensured it remains.
- Adobe Flash & HTML. Heralding in a new era of rich internet applications, Flash was powerful and relatively easy to develop, but found itself being squeezed out by resurgent HTML (5) technologies, and its widespread adoption by many (browser) platforms.
- Microsoft Silverlight is a framework for rich internet applications, and offered an alternative to Flash. It has now been deprecated (losing support in 2021). [1]
- Many aspects of Microservices are not new concepts. Whilst it has many redeeming qualities, they also increase manageability costs, may nudge you down a (previously untraveled) Eventual Consistency model, and (if not carefully managed) can cause Technology Sprawl. Their additional complexity causes some startups to pursue a monolith to prove out a business model.
- NoSQL databases had a surge of interest a decade ago. Whilst they’ve made steady progress (most notably MongoDB), I’ve also seen a backlash (and experienced certain vendor-specific limitations that I’d assumed were available), causing some to return to the more conventional (exoteric) relational solution. I have provided some rankings below - note at the time of writing that four of the top five are relational. [2]
Some of these technologies have seen great success, some may even have been viewed as “technically superior”, but that isn’t necessarily “better”.
Another danger of the new is when it's not new at all. It’s relatively easy to make something old seem new, when in fact it’s the same thing with a new veneer (e.g. Aesthetic Condescension is one way to falsify its subject matter), but repackaged into something else and resold.
NEOPHILIA
Some of my favorite examples of this neophilia come in the form of frameworks and products that promise “high productivity at zero cost”. Sorry, but everything has positive and negative aspects (No such thing as No Consequences). Some promote (mainly poor) practices like direct interactions between UI and a backend database, and throw up all table fields to the form for display. It’s certainly rapid development, but is it right? How do you support a new mobile strategy with this solution? Duplicate the approach and create two divergent codebases?
APIS - NEW ISN'T ALWAYS BETTER
Many years ago I remember using Java Servlets to build web service APIs, long before SOAP, and then REST, became fashionable. They were (relatively) easy to build and to integrate with, and overall, were a good solution.
When SOAP started gaining industry traction, we reassessed our API strategy. Although the servlets approach was highly convenient and good (albeit it lacked some consistency), we were pressurised (mainly by external market forces) to shift our API standard to SOAP. There were many reasons for this, and most seemed reasonable at the time, so one should resist Hindsight Bias.
“Simple” it was not (the ‘S’ in SOAP was meant to stand for simple), and soon enough we saw a new contender (REST) rise, with the promise to right all the wrongs of SOAP. We almost found ourselves coming full circle, implementing something very similar to what we had a decade ago, but after considerable time and investment. New isn’t always better.
Ok, but if my idea of “better” is established and far-reaching tools, how can we innovate? That’s the tricky part, and partly why businesses often couple themselves to tools that don’t survive. Whilst being at the forefront of technology allows you to reap all of its benefits, that assumes the tool is successful; you suffer the consequences if it is not. It’s a balancing act - wait too long and lose some of the benefits, go too soon and you risk introducing failure into a business that is hard to extricate. It is also driven by your appetite for risk. Anything that is mimicked by others (particularly the backing of large technology corporations) is probably not a flash in the pan (e.g. the serverless vision has successfully embedded itself into all major Cloud providers), but it's by no means a guarantee. It’s the agony and ecstasy of working with technology.
SUMMARY
The quest for ever-faster TTM can drive poor (and unchallenged) decisions. Some people get so hung-up upon the speed of change that longer-term consequences are forgotten or ill-considered. It's hard to describe (or contextualise) what the potential consequences could be of a decision in five years' time, when it's very obvious what the short-term consequences are. We’ll naturally favour (bias) satisfying known short-term consequences over some longer-term, nebulous consequence. This bias can pave the way for the adoption of new tools, regardless of the implications. We attempt to treat the patient without diagnosing their malady, or the consequences of their treatment.
Our industry is littered with examples of tools that were once lauded but are now defunct or demonised. New tools can introduce just as many anti-patterns as the old tools they’re meant to replace, yet you’ll rarely hear that from their marketing teams (and the magpies who follow them), who play up their benefits whilst hiding, downplaying, or even being ignorant of their disadvantages. There's always consequences (No such thing as No Consequences).
Whilst new is often better, that isn’t the same as always.
FURTHER CONSIDERATIONS
- [1] - Silverlight: https://en.wikipedia.org/wiki/Microsoft_Silverlight
- [1] - Silverlight: https://w3techs.com/technologies/details/cp-silverlight
- [2] - Database Trends: https://db-engines.com/en/ranking_trend
- [2] - Database Trends: https://db-engines.com/en/ranking
- No such thing as No Consequences
- Marketing Magpies
- Aesthetic Condescension
“SOME” TECH DEBT IS HEALTHY
Now for something a bit contentious... I regularly hear technologists greet Technical Debt with such contempt that they expect all forms of it to be extirpated. Some technologists will take pains to remove even the most innocuous and unimportant technical debt in an effort to cleanse the system of all evil (a technical debt exorcism). I follow the motive, but not the rationale.
To put it bluntly, I’d be worried if a business didn’t have some technical debt. Surely it would indicate that its technology staff had stopped adding value for the customer, and shifted focus solely on to system health and hygiene (what those engineers felt was important)?
Caveat Emptor. I know of no valid excuse not to clean. You should still address Technical Debt to protect systems and the overarching business from Entropy. A healthy business though always has friction between building value for the customer, and system hygiene (to keep the business nimble). If you’re spending all your time building nothing but customer value, then you’ll eventually fail as the technical debts accrue; yet if you invest all your time addressing technical debt, then do you actually have a viable business?
“SOME”
Of course the definition of what “some” technical debt is highly subjective. I’ll leave that one with you.
FURTHER CONSIDERATIONS
CONSUMER-DRIVEN APIS
APIs (Application Programmable Interfaces) are one of the most fundamentally important of business technologies, being a main interface for the flow of information and services between a business and its consumers (including other businesses). APIs therefore deserve respect, and should be designed and built with that respect in mind.
Poorly designed (or constructed) APIs can:
- Limit your business' reach and accessibility.
- Present your business in a poor light. For instance, the use of antiquated API technologies (and documentation) may indicate business stasis and lack of innovation; a lack of consistency may indicate a fragmented or disjointed technology strategy.
- Alienate, or discourage, prospective customers.
- Infuriate and disengage existing customers.
- Lead to poor Stakeholder Confidence.
- Increase costs (thus reducing profits). For instance, poor APIs make for lengthy and error-prone integrations, resulting in unexpected delays (TTM), and additional (unnecessary) support costs.
- Non-functional failings (e.g. security, scalability, availability) that impact Reputation.
- Prevent technical and (thus) business evolution, typically by tying powerful and unyielding consumers to poorly designed or evolvable APIs, and thus tying your business' evolutionary cycle to the worst consumer performer's evolutionary cycle.
- Adds (avoidable) complexity to an API integration.
- APIs affect perception and therefore Reputation.
There's a common API-design anti-pattern, known as Bottom-Up API Design. It typically exhibits some of the following characteristics:
- APIs are complex and difficult to understand.
- APIs use flat structures that mirror the flat internal table structures (the data model) they represent.
- APIs reflect back internal (illogical) naming conventions to the consumer. See my previous point on complexity.
- The API flows mirror the navigation routes through the internal model (tables); i.e. we don't design the flow for how our consumers should use our APIs, we just mirror internal data model flows directly to our consumers.
- APIs fail to combine similar responsibilities together into a sensible response, expecting consumers to do all the leg work. There's no aggregation of data to reduce complexity and resilience.
DON'T EXPOSE YOUR PRIVATES!
In my article on API design [1], I describe the importance of the “Don't Expose your Privates” practice. In this case, an API exposes unnecessary details to external consumers, who become tightly coupled to those details.
Some Rapid-Application-Development (RAD) tools (indirectly) advocate breaking fundamental encapsulation techniques for the sake of TTM and efficiency. Be wary of any tools or practices (I also see this approach used regularly where no tools are involved) that advocate directly exposing internal (data or navigation) models. It will, of course, be quicker (that's what makes it so appealing) in the short-term, but balance that against the longer-term costs of complexity and the inability to evolve.
To further elaborate, I regularly see this practice used within Microservices which manage data using an Object Relational Model (ORM) framework. It's convenient and quick to reuse the same persistable entities for multiple purposes - to persist data and to represent an API request/responses (which is the realms of DTOs) - but it's a dangerous practice because:
- You may tie the consumer to an internal model, reducing Evolvability.
- You may expose more information than anticipated (or necessary), simply by forgetting to annotate a sensitive field.
- Mindset. Possibly the most concerning aspect is that this practice suggests an inclination towards bottom-up API design, rather than top-down, consumer-driven design.
As I've inferred, API malpractice can have very serious business evolutionary challenges, particularly when consumers are other businesses (i.e. the Business-to-Business, B2B, model). If you think it's difficult to make internal evolutionary changes, wait till you attempt it with external integrators!
Every business has a discrete, individualized evolutionary life-cycle, which may be at odds with the life-cycle of your own business (indicating we have different levels of Control over the evolution of other businesses). There may be hundreds of these integrators; all evolving at different rates and with different expectations. Some may own a greater market share, and have more financial clout than your own business, creating a situation where some consumers will dictate your evolutionary abilities. The moral of the story? If you get your APIs wrong, you may be stuck with that decision for a long time.
CONSUMER-DRIVEN MEANS BIDIRECTIONAL INFLUENCE
It's worth noting that building quality Consumer-Driven APIs isn't solely about what API owners think the consumer wants. It's also about empowering consumers to suggest how those APIs should work. I've witnessed situations where both the API owner can't (or won't) support consumer requests and where the consumer is unwilling to broach the subject of change with the API owner (I've even seen this with internal teams). Whilst it's not always possible for the right party to evolve an API, that doesn't mean we shouldn't try.
If owners won't countenance sensible changes within sensible timeframes, consumers may get frustrated (and shop around for alternatives), or be forced to implement unnecessary workarounds, adding complexity to the overall solution. And increased complexity typically indicates reduced reliability, affecting Reputation.
Whilst API owners may disclaim any responsibility for problems that surface due to this complexity (the complexity was all on the consumer side after all), its rarely that simple. If your consumer suffers a branding faux pas, financial loss, or uncertainty due to an unreliable system, stemming from your APIs, or an exclusionary culture, why would there not be some repercussions within your own business (No Man is an Island)?
Sometimes the reluctance to change isn't cultural but a problem with the system as a whole. In these cases, the system may not support a mechanism for API owners to establish who an API's consumers are, and how they use it. This is a form of Change Friction - we simply cannot risk a change without knowing its impact.
SUMMARY
Some final thoughts for this section. Don't drive API design from the bottom-up, but from the top-down (i.e. consumer-driven). Where possible, let consumers drive flows, and external structures. Consider the need, name, and purpose of every data field before exposing it.
FURTHER CONSIDERATIONS
- [1] - https://medium.com/@nmckinnonblog/api-integration-manifesto-8814dbc7261a
- Change Friction
- Control
- Microservices
- No Man is an Island - https://www.goodreads.com/work/quotes/6791114-no-man-is-an-island
- Stakeholder Confidence
MVP IS MORE THAN FUNCTIONAL
One mistake I’ve seen some businesses make is assuming that a MVP (Minimal Viable Product) is solely about delivering functionality. It’s not.
The word “viable” offers a clue. The purpose of a MVP is to prove the viability of a solution (and to reduce business risk) - both its functional viability (does the customer want these features?), and its non-functional viability (is the solution technically viable?). You can’t do both if your only focus is on functionality (Functional Myopicism).
FURTHER CONSIDERATIONS
THERE'S NO SUCH THING AS NO CONSEQUENCES
“You can't have your cake and eat it.” - English Proverb.
Everything we do in life has consequences. Let no one deceive us of this. Every decision (or lack of decision) has some effect - either positive or negative - on a system.
The challenge of technology (or any Complex System) under these circumstances, is that the outcome (consequences) of a decision is not always noticeable, easily understood, or quickly seen.
CONSEQUENCES
The implications of a poor decision on a Complex System may not be seen for many years, potentially long after the people who made it have left (some studies suggest the average retention time for technologists is around two years). [1] Yet, your business may own and maintain these systems for decades.
I hope that what I've presented so far helps to illustrate my point. Each technical quality is tightly linked to many others (and to other business qualities). Applying a positive force on a quality in one area will have a detrimental effect on others. It's not possible to get the best of everything - something must be sacrificed to the gods.
Let me offer some examples:
- New Isn’t Always Better.
- Selecting one vendor over another is a delicate balancing act. Choose one Cloud vendor, and you'll receive all their benefits, but you may miss out in strong offerings from other vendors.
- Security v Useability. There’s always been a great rivalry between these two qualities. Introducing too many security controls can hamper user experience (Useability); but too far in the opposite direction can introduce an unhealthy risk.
- Indirection v Performance:
- “All problems in computer science can be solved by another level of indirection.” - David Wheeler
- “Most performance problems in computer science can be solved by removing a layer of indirection” [unknown]
- Each Technical Debt that is deferred adds mounting pressure upon a business that must (eventually) be paid, or suffer the consequences. It might not happen immediately - as it’s (often) unseen and insidious - but the day will come.
FURTHER CONSIDERATIONS
- [1] - Employee Retention - https://www.businessinsider.com/employee-retention-rate-top-tech-companies-2017-8?r=US&IR=T
- Complex System
- New (!=) Is Not Always Better
- The Cloud
- Technical Debt
- Indirection
WHY TEST?
Why do we test? Yes, I saw that quizzical look you gave me! Surely it’s obvious?
The stock answer is that testing verifies quality (e.g. product quality), and that protects other important characteristics, like customer satisfaction (and thus, Brand Reputation). Testing teams are - after all - often regarded as Quality Assurance (QA). But that’s not the whole picture, and one that’s easy to lose sight of.
Testing can also:
- Increase Stakeholder Confidence. At first glance, you might not give this much credence,
but consider the second-order outcomes of increased confidence. It may enable:
- Sales teams to focus on selling, and stop worrying about whether a product will meet customer expectations, or if their demo to an important customer runs smoothly.
- Developers to focus on developing new features and innovating, without worrying about introducing flaws.
- Testers to spend more time finding aberrant bugs, or undertaking other types of important testing (e.g. exploratory).
- Operational staff can correctly provision resources, knowing they will be capable and cost-effective.
- Stimulate Innovation. By widening the Safety Net with increased test coverage, we enable staff to solve problems in more unique and innovative ways.
- Staff retention. People are happiest if they are kept engaged (i.e. in “flow” [1]), and that is most likely to occur when they are pioneering. They may achieve this - at least in part - with a Safety Net.
- Increase TTM. Whilst this is not necessarily true of the first release (testing may slow an initial delivery), it often helps to make every subsequent delivery faster. This has great merit if we consider that 40%-80% of time is spent maintaining existing software.
- Better longer-term ROI. Note my emphasis on the longer term. Testing (and tests) is an investment in time and money. You won’t necessarily make a good return from the initial change (although it may protect your reputation), but each subsequent change is easier, and they all add up to a decent return.
SUMMARY
The later that we check for quality, the costlier a breakdown in quality is. Both monetary, and time. Additionally, a lack of (sufficient) tests/testing may also risk reducing business Agility, and impede our ability to Innovate.
Aside from the financial aspect - which may be significant - both of these failures can lead us away from producing other types of value. This wasted time could be the difference between a business built on mediocrity, and one that finds its fortune with a disruptive technology.
FURTHER CONSIDERATIONS
- [1] Flow - https://en.wikipedia.org/wiki/Flow_(psychology)
- Stakeholder Confidence
- Safety Net
- Innovation
BULKHEADS
The idea of (system) bulkheads is not a new one. The Chinese have been building ships using bulkheads (compartmentalising) for many centuries (Chinese junks contained up to twelve bulkheads), for several reasons:
- To prevent goods contamination.
- To harden ships (i.e. increase structural integrity).
- To reduce the likelihood of sinking, by creating watertight compartments that will fill, but won’t let others; i.e. when one part of the ship floods, compartmentalisation ensures that other parts don’t flood, keeping the ship afloat. [1]
Consider the figure below, showing a schematic of the RMS Titanic.
 Bulkheads in RMS Titanic [source: Wikipedia]
Bulkheads in RMS Titanic [source: Wikipedia]
You might wonder why I chose to present the RMS Titanic; it is, after all, notorious for its tragic failure. However, it failed not because of the compartmentalisation technique, but (mainly) due to its poor implementation (and some pure misfortune). It's also a good example of how poor (or no) compartmentalisation can have disastrous outcomes. Once the water flowed over one bulkhead it would then flood the next, in a cascading fashion, until sinking was the only outcome.
Contamination is another interesting one, and plays into Domain Pollution. The Chinese didn't want a catch of fish contaminating other perishable goods, such as grain, so they kept them isolated and prevented their intercourse.
These shipping analogies are also good parallels for how to build software. We too want to prevent the flooding of our systems (Flooding the System), and no part of a system should bleed responsibilities, data, or performance expectations into another domain, else we contaminate that domain (with productivity, evolutionary, and data integrity challenges). System Bulkheads - such as queues (Queues & Streams) - help to isolate distinct parts of a system(s), enabling each to move at a pace appropriate to it (and not be dictated to by others), or even to fail, recover later, and still achieve the system’s overall goal (Availability). Bulkheads have another redeeming feature - they create autonomic (self-healing) systems that need little to no manual intervention to recover.
BREATHING SPACE
By placing intentional barriers between distinct domains, we ensure one can’t flood another, giving us time to pump out the water (or messages) when convenient.
FURTHER CONSIDERATIONS
- [1] - In fact, there were cases where they intentionally flooded parts of the ship to balance it.
- Flooding the System
- Queues & Streams
THE PARADOX OF CHOICE
Choice is a wonderful thing. Isn't it?
We hold a certain bias towards an abundance of choice, often painting it in a positive light; e.g. “Thank goodness we have many ways to solve this problem”, “Which pricing model should we offer our SAAS customers?”, “Which vendor should we deploy our new solution to?”, “Which of these ten languages should we use for this solution?”, “The CTO has promised that I can select my own team from our hundred employees, which ones do I choose?”, “In which sequence should I re-architect domains in our existing monolithic application to modernise it?” You've probably faced some of these choices yourself.
Choice overload though, can actually stifle decision-making, causing procrastination, confusion, and paranoia (we become overly concerned about making a poor selection). In the technology world, this may lead to Analysis Paralysis, and protracted solution delivery.
Whilst it’s easier said than done, one simple solution to this problem is to reduce the amount of choice. Alternatively, if finding the optimal path on the first pass is impractical (and not always necessary), just choose one to bet on, being cognizant that it may not be optimal, but it will break the paralysis and enable the team to either reduce their choices, or now identify the optimal path. This approach can act as a stepping stone to the next best thing.
MAKING SENSE OF IT
You may also use sense-making frameworks (like Cynefin) to help guide your decisions. Once you get a sense of where you are, you can - for instance - clear the way by investing in further analysis, or alternatively spend that time trying something and then deciding what to do next.
FURTHER CONSIDERATIONS
TWELVE FACTOR APPLICATIONS
Twelve Factor Applications is a methodology for building software applications that helps to instill certain qualities and practices into software. Software that exhibits these qualities is often more evolvable (Evolvability), resilient (Resilience), testable (Testability), maintainable (Maintainability), releasable (Releasability), and manageable (Manageability).
I won’t name all twelve factors here (see this page [1]), but I will describe some of the factors that I find particularly enlightening:
- Strictly separate build and run stages.
- Dependencies. Explicitly declare and isolate dependencies.
- Disposability. Software can be destroyed and recreated with ease.
- Dev/prod parity. Ensure all environments remain aligned.
I discuss them next.
SEPARATE BUILD & RUN STAGES
Separate build and run stages
A software change typically has three stages:
- Build. Check the stability, quality (e.g. gather source code quality metrics), and the functional accuracy of the source code being transformed into a software artefact. This should be done once per release. The output is typically a packaged software artefact (if successful), which is uniquely identifiable, and stored for future retrieval.
- Release. Combine a specific configuration with the software artefact (built in the previous stage) to enable it to run in the target environment (i.e. contextualise it for that environment). The software is now ready to be run.
- Run. Run the software in the target environment.
BUILD V DEPLOY & RUN STAGES
The build stage is responsible for packaging up a software application and storing it for access in subsequent stages. We may initiate the release and run stages many times, but we only require a single build stage.
By separating each stage and treating it as an independent stage we:
- Minimise Assumptions. Unnecessary assumptions hamper Reuse, Flexibility, and Evolvability - to name a few. Separating responsibilities into focused (cohesive) build and run stages therefore enables their use within different contexts.
- Improve Flexibility and Reuse. Finer grained stages can be combined and reused in a wider variety of ways.
- Enable a fast rollback facility. If the current release version fails, we simply revert to a previously known good state (using a release version).
- Pressurise Circumvention. Circumvention - e.g. the manual hacking of a production environment to make it behave as we expect - is something we want to avoid (it affects both Disposability and Dev/prod parity) if we want repeatability. Circumvention can create environmental variability and inconsistencies.
- Fast initialisation (and destruction) times for the spawning of new instances.
IMMUTABLE, IDENTIFIABLE & AVAILABLE
Note that the created software artefact should be immutable, identifiable, and available. Any new change to the source code requires the creation of a new artefact version (this also protects against Circumvention).
ONE-TIME BUILDS ARE A MEASURE OF CONFIDENCE
It's quite possible to rebuild the same source code, yet get different results, and thus inconsistent artefacts. This is dangerous and why we should avoid repeated builds of the same code for the same purpose.
By executing the build stage once (and only once) per release, we gain confidence in the artefact's consistency across all deployments, which is then stored - as an immutable artefact - for future deployment.
DEPENDENCIES
Explicitly declare and isolate dependencies
This factor has two key points:
- Each and every dependency - including their version - is explicitly declared.
- An application’s dependencies are isolated from another’s.
Software is not an island. It requires the support of many other software artefacts (libraries, frameworks) to form something useful. Yet software and its dependencies change. Classes are deprecated, packages move, implementations change, flaws are patched etc etc. Any change in a dependency creates a potential friction in your software. Some may be readily apparent (e.g. compile-time failures), some may not (e.g. runtime failures). Feedback, surety, and confidence are lost with implicit dependencies. It's quite possible to successfully develop and test a feature, only for it to fail in LIVE due to a different dependency configuration.
Secondly. Not only must we be explicit in our dependency management, but we must also isolate those dependencies from the pollution of others. One application, one set of dependencies. There should be no sharing or centralising of dependencies as:
- It increases complexity. You can’t (easily) distinguish which dependencies are used per service.
- You lose Control. How dependencies are linked may be at the whim of a class loader, not your application. Multiple versions of the same library may not play well together.
The downside to this approach is one of duplication, resulting in increased storage needs. Whilst this certainly used to be a problem, it isn’t really nowadays with storage costs so low.
REAL-WORLD EXAMPLE
I still remember one of my earliest forays into Java web development. At that business, several web apps were deployed into a single web container, using a shared library model. Storage was more expensive in those days, and it seemed sensible to share dependencies, but Control was a real problem.
Each application used a mixture of: distinct libraries, the same (shared) libraries, and different versions of the same (shared) libraries - all held within one directory and class-loader. It became impossible to associate the correct version of a shared library with the application that used it, it being left to the whims of the class-loader’s ordering strategy. This was unsustainable.
The use of packaged .war files - and later Maven - was a revelation. By explicitly declaring the library/version, and isolating them, there was no pollution and the correct dependency was always linked.
DISPOSABILITY
Maximize robustness with fast startup and graceful shutdown
There’s a well-known metaphor in modern software delivery - software applications should be treated as “Cattle, not Pets” [1].
Treating software as a pet places the wrong onus on it - one of attachment. In this model, considerations such as the time/effort invested, manual configuration, and even Circumvention create an unhealthy attachment (a Disposability Friction). What’s occurring is an Attachment Bias - our decisions are shaped by our attachment to the software, rather than (necessarily) to the overarching business’ needs (e.g. resilience, recovery time, scalability). When our software sickens, we rush to the rescue, further exacerbating our attachment as we invest more into the workarounds that keep them healthy.
DISPOSABILITY & MONOLITHS
I’ve seen this attachment model with Antiquated Monoliths and Lengthy Release Cycles where:
Monoliths also contain (many) more Assumptions than a typical domain-driven component (e.g. microservice), again challenging disposability and increasing our Attachment Bias.
- The configuration effort was highly specialised and significant.
- Containers were slow to initialise (e.g. 10-15 mins) and destroy, making the thought of restarting them (let alone redeploying them) unappealing.
- Deployments were atomic and contained many sequential activities.
To my mind, this attachment bias actually creates a reliability paradox. By attempting to protect software against all comers we may build less resilient software (sacrificing Resilience in a vain attempt to protect Availability), such as:
- Allowing Circumvention to take place ("we just need to do it once, honest!").
- Increasing protective controls. More controls, more moving parts. This increases the complexity of an already Complex System, in an attempt to always protect Availability.
- Creating an expectation that someone is always available to nurse the software back to health. The complexity (and highly contextual nature) of some systems makes it difficult to write automated resolution, so manual intervention is required.
Ok, so how does all this relate to disposability? There are two qualities I consider when viewing disposability:
- Resilience - the ability to recover from a failure, ideally autonomically. Software shouldn’t rely on someone being available to configure, deploy, and verify it. Declarative platforms with observable and autonomic qualities should be used where practicable.
- (Rapid) Scalability - the ability to rapidly scale out services to meet demand. The time element is important here.
Disposable software should:
- (Ideally) Take seconds to get running (or stop). This should also be true if a rollback is required.
- Be graceful to the application (and target environment) state in any starting, stopping, or termination activities. This should also be true when used in conjunction with techniques such as Blue/Green Deployments and Canary Releases - earlier versions of applications can be disposed of, without affecting the new application state.
- Ensure application state is not stored in the running application (it is stateless), but in “backing services”.
REAL-WORLD EXAMPLE
Off the top of my head I can think of several instances of software failing the disposability factor. In one case I witnessed the spawned application being initialised by reading many GB’s of data from a datastore before storing it in a local cache. Initialisation took around 15 mins, during which time the service was unavailable.
It failed the disposability factor on at least two accounts:
- It took too long to initialise (seconds is acceptable, but not minutes). Anything that takes so long to initialise creates some attachment bias; it also limits (rapid) scalability.
- It depended upon embedded state (not a backing service).
DEV/PROD PARITY
Keep development, staging, and production aligned
Picture the scene. Your business is building an important software feature to be released to the market. The marketing team has already sent out press releases and there has been great interest. Everything seems to be going well - the feature has been successfully developed and tested and it's now ready for production release. The fateful day arrives - the software is released to production with some fanfare. Shortly after though, the customer care department begins to receive a flood of complaints from existing customers. Something is terribly wrong. The production environment is rolled back to the previous (stable) release, resolving the customer issues; however, the press release is a disaster and reputational harm is done.
What went wrong? After a deeper investigation it turns out that the production environment was configured differently to the other (development and test) environments, creating a disparity. It seems that Circumvention was at play. The previous product release was manually configured to get it working, but that change was never transmitted back into previous environments - had it been, then this problem would have been quickly caught and resolved, and no harm would be done. We wish to avoid this disparity.
IS FEATURE X LIVE YET?
It's sometimes possible to infer a disparity between production and other environments, for example, with questions like: “is feature x in live?”
What this suggests is that there’s a substantial gap (temporal probably) between a feature being built, tested, and finally put live. The person asking this question can’t determine where that feature is, due to the unpredictable time gap between when a feature is completed development and when it is released to production.
This disparity may originate from:
- Temporal disparity. There’s always a time gap between the current state of production and what’s currently being created by developers. The longer this gap, the greater the likelihood that a disparity causes a bigger issue (see Entropy). We can minimise this temporal disparity with “continuous” techniques.
- Personnel disparity. A disparity in roles, skills, and responsibilities (e.g. developers v operations) can create knowledge, ownership, and accountability gaps. This can be alleviated with Cross-Functional Teams - the team that built the feature is the team that runs it.
- Tool/technology disparity. A disparity exists when a different tool, technology, or version of a tool/technology is used in production that is not in the development/test environment. This might occur if:
- It's difficult to install a particular technology in a non-production (e.g. development) environment so a lighter-weight equivalent is used.
- The production environment uses a technology with a high licensing cost and it's (financially) impractical to align developer/test environments in the same way.
- A partner service you depend upon (e.g. SAAS) uses a different configuration in test than production. I’ve seen cases where the SAAS provider’s environments are distinct enough to create friction in both feature and non-functional testing.
- Expediting. Some remnants of a previous release may be retained in an (test) environment that aren’t promoted to production. Developers may assume (Assumptions) this change is now available to them and leverage it for their own change. These changes may allow a build to succeed in the test environment but fail in production.
- Circumvention. As I described earlier, circumventing good practice to meet a deadline often causes that change to be forgotten, and never established in earlier stages of a software release. Other factors (in Twelve-Factor) tackle this problem.
- Other pollutants. A shared model can also cause disparities that make the production environment behave differently to how a feature was successfully tested. For instance, I’ve witnessed a shared test environment (e.g. the same database) configured to allow multiple testers (tenants) to run tests in parallel, but actually creating a condition where tester A passed a build based upon tester B’s configuration settings, making those tests redundant but also risking the stability of the production build.
EXPEDITING & CIRCUMVENTION
Expediting is a common pitfall in (particularly reactive) businesses; it occurs when a feature is deemed more important than the others already in the system, so is given priority. Expediting typically involves Context Switching; work stops on the current work items, the system is flushed of any residual pollutants from those original work items, and then work begins on the expedited work item.
Expediting can also lead to Circumvention. Established practices are circumvented to increase the velocity of a change (expediency), or so we hope.
We expedite and circumvent mainly from time pressures. We can reduce those pressures through efficient and reliable delivery practices.
FURTHER CONSIDERATIONS
- [1] - https://12factor.net/
- [2] “Cattle, not Pets” - https://www.theregister.com/2013/03/18/servers_pets_or_cattle_cern
- Antiquated Monolith
- Assumptions
- Blue/Green Deployments
- Canary Releases
- Circumvention
- Complex System
- Control
- Cross-Functional Teams
- Entropy
- Expediting
- Lengthy Release Cycles
AUTOMATION ALSO CREATES CHALLENGES
Imagine that you work in a factory creating caramel shortbread (one of my favourites). The factory sells to a number of retail customers, who then resell them on to their customers for another profit.
The factory can produce 10,000 bars a day, costing them around 15c per bar (in ingredients/electricity/employment). They sell each bar to their retail customers at 80c, who then sell it to their customers at $2. The factory runs ten hours a day, producing an average of 1000 bars an hour.
There’s many stages from pot to shop, and many things can go wrong, such as:
- The batch is poor, or is polluted in some way.
- A machine breaks down.
- There is a power cut.
- A machine is misconfigured to the wrong heat, causing the caramel to congeal.
- The caramel or chocolate is too gooey at point-of-packaging, causing a sticky mess to attach to the packaging.
- There’s insufficient quantities of packaging for what’s produced.
Now, I’m not an expert on the productionisation of caramel shortbread, but I suspect that many other things could go wrong on a production line. The point is, not all problems are immediately visible, but they can all cause problems in either the quality of the end product, or create unnecessary waste.
Let’s say a batch gets polluted soon after the initial bake. To counter this, the factory puts a “taste test” control in place, verified every five minutes. However, the factory can process a decent number of bars in five minutes (of the order of 83 bars - 1000/60 * 5). That's $12.45 + $54 in lost profit for that five minutes. [1]
Not too bad considering though? Ok, so let’s up the stakes. Let’s reduce the “taste testing” control to once every hour and also increase factory output from one to ten thousand bars per hour. (Conservative) Estimates now put the loss at $8000 ($1500 in waste and $6500 in lost profit), and that’s assuming no additional surrounding waste. We see a marked increase in the cost of a failure as (a) the number of units increases and (b) the time between verification expands.
If we were to revisit this concept on a smaller, less autonomous, scale (e.g. a local bakery producing their shortbread by hand, and selling it on directly to their customers) we’d find the same contaminant failure risk had much lesser consequences (it might only cost a few hundred dollars).
What I’m trying to demonstrate with this analogy is that whilst automation has great merit (automation is often key to sustainable business Agility, scalability, growth, and Economies of Scale), failure can be costly. [2] In the software world, data is (often) “king”. Data about a person, transaction, event, or something that is used to make an important decision (e.g. who to offer insurance to, stock trading, or diagnosing a disease) must be accurate. However, the consequences of an automation failure may be much greater (affected records), and may even lead to severe financial penalty. Of course the same problems can occur due to manual intervention, but they tend to have a lesser impact as fewer records can be visited in the same period.
The impact of automation failures can be alleviated through several mechanisms. The first thing to consider is how to stop exacerbating an identified problem. This is achieved using a context-specific Andon Cord - i.e. a switch-off mechanism. Secondly, consider keeping a data history to provide a means of both fast comparison, and rollback. Whilst a regular data backup (archiving) may provide a reliable history, it's not always immediately available, easily accessible, or fast. You may also wish to consider how to rollback to an earlier point in time (e.g. versioning) if an additional (correct) change is stacked upon an incorrect one. You probably want to keep the correct change but revert the one it's built upon.
Other useful approaches include:
- Ensure the automation rules are built with the involvement of any users who currently use the equivalent manual flow. It seems obvious but worth being explicit.
- Show caution in the initial use of automation until you’re sure it's correct. For instance, you might intentionally throttle capacity to lower numbers and only increase pace once you have confidence in the process.
- Regularly send automation results to an expert (e.g. SME) to verify their accuracy - this is the equivalent of our “taste tester”. Find the right balance between regular verification and unnecessary intrusion, to get regular feedback without frustrating users.
- Communicate changes with the potential to cause problems to any teams who rely upon the automation, or who verify it. Knowing when a change was released is a crucial piece of information for tracking down a root cause.
FURTHER CONSIDERATIONS
- [1] - Of course there’s also the time between identifying the failure and disabling the production line, and the cost of not delivering certain quantities in time - e.g. what's the impact if the production line is out for four hours?
- [2] - e.g. epic fails at fireworks displays where the entire display is triggered instantaneously.
- Andon Cord
- Economies of Scale
DECLARATIVE V IMPERATIVE
What’s the main differences between the following approaches:
- “Ok, do it like this, then do that, and then do this. No, not like that, like this.”
- “Ok, this is how it should look, can I leave it with you to figure it out?”
The first approach is all driven by one person telling others exactly what to do and the order to do it in. That person is deeply (inextricably) involved in both the what and the how of reaching the outcome. The second approach focuses on defining the end state, but letting others figure out how to reach it. That person is only involved in the what, and has little involvement in the how.
This model may be applied to container management platforms, automation frameworks, programming, and even leadership. Kubernetes - an open-source container orchestration platform - supports the declaration of objects in both imperative and declarative styles. Aspects of functional programming (e.g. map(), filter(), reduce()) are more closely associated with declarative than the historical imperative mode of many programming languages.
The imperative mode - being instructive - is quite detailed and offers fine-grained control. This is useful if a declarative model doesn’t (or can’t) provide sufficiently detailed control. Whilst steps in an imperative model may be easier to read, its benefits are countered by the need to write (often far) more written instructions than its declarative counterpart, making comprehension over the whole harder. This also makes the imperative model harder to scale. Finally, being more detailed, and contextual, we may find there are more assumptions (Assumptions) embedded in imperative scripts, thus reducing reuse (Reuse).
With the declarative mode, we simply tell a framework/platform what our end state is and let it figure out how to get there (declarative uses, but doesn’t define the steps). It uses a layer of abstraction which often reduces complexity because (a) implementation details remain hidden, (b) there’s less code to understand, and (c) it can help to reduce duplication. Assuming the abstraction already exists, then the declarative mode can also reduce the time and effort required to solve a problem.
FURTHER CONSIDERATIONS
WORK ITEM DELIVERY FLOW
The “ticket” is a fundamental delivery management mechanism for software delivery. It typically represents a user story, which (usually) represents the partial delivery of a software feature. Accompanying the ticket on its travels is a work item (the software of value) - together they transition through a number of different stages until completion. Ticket flow may differ slightly per organisation, but in the main it follows this flow.
The stages are:
- Ready. Discovery is complete - e.g. Example Mapping is done, the acceptance criteria is defined, and a Three Amigos has been undertaken.
- Development. Software is built (or integrated), deployment pipelines built, and fine-grained testing is undertaken.
- Peer (Technical) Review. Software is verified it meets a certain standard. This stage also provides a means of extending knowledge beyond the original developer.
- Deploy to Test. The software is deployed to the test environment so that it can be tested.
- Test. The software is tested for functional correctness by ensuring the acceptance criteria is satisfied. There may be other criteria (e.g. scalability), but let's keep it simple for now.
- Product Review. A product representative confirms the feature behaves as expected.
- Release to LIVE. The feature is released to the production environment for use.
- Done. The ticket is complete.
Make sense? Ok, so I fibbed a bit, sorry... Whilst the above flow represents the main stages, it doesn’t necessarily present a true practical picture. The true picture changes based upon the chosen form of engagement (Indy, Pairing & Mobbing); however a standard (Indy) flow looks like this.

A bit more rambling - and repetitive - than the first flow isn’t it? The key difference is all of the waiting stages - which we often find sandwiched between the doing stages - a problem common to any form of manufacturing, not just software, and one that LEAN principles take into account (e.g. The Seven Wastes).
FURTHER CONSIDERATIONS
SHARED CONTEXT

Software is but one representation (or implementation) of the ideas that flow through a system (a system in this sense being an “idea system”). To me, there are two qualities I think important in the (software) implementation of an idea:
- It provides customers with value.
- It is sustainable (Sustainability) to the business.
Whilst I shall assume the first, the second requires something more fundamental than software; it requires a Shared Context.
New software is (still) often written by an individual. And whilst that’s not necessarily an issue, it does raise questions about how we (a) maintain it if that individual is unavailable (they’re too busy, on holiday, or have left the company), or (b) increase support capacity to it when the business must scale up in that area. The sharing (and retention) of contextual information about the ideas we build (a shared context) is vital.
Consider how work items are managed (Work Item Delivery Flow). It's extremely rare for software to be released (or built for that matter) without also releasing contextual information (e.g. the why, who, what, how) alongside it. At each stage, there’s context applied or shared with others. A Shared Context may be used to:
- Align different stakeholders around a change.
- Communicate more effectively; e.g. using common terms.
- Support better decision-making. Knowing specifics enhances understanding, allowing for more informed decisions.
- Understand when to apply quality (and to what extent), and when not to.
- Identify a solution’s strengths and weaknesses.
THE WHATS, HOWS & THE WHYS
Whilst software can provide the whats and hows, it can’t provide the whys. Nor can it always provide the reasoning why one approach was selected whilst another was discarded.
WORKING SOFTWARE OVER COMPREHENSIVE DOCUMENTATION
Note that I’m not suggesting we ignore the Agile Manifesto’s principle of “Working software over comprehensive documentation”. Shared Context is less about documentation and more about communication and the sharing of ideas.
A loss in shared context may create:
- Single Points of Failure. A single person may become so knowledgeable about a specific context (e.g. domain) that they are deemed irreplaceable (which comes with its own issues), and every change must go through them (bottleneck).
- Slower deliveries. We must either use our single point of failure (who may already be a bottleneck), or investigate and resolve it ourselves without the context.
- A poor (team/business) flex in capacity. Scaling up, or transitioning to another important feature is difficult due to too much specialism and too little shared understanding.
- More complex capacity planning. It requires more tetris-style planning activities - we can only fit certain individuals to certain tasks - which must be undertaken sequentially. This is a thankless task.
- Poor morale. Staff with expertise in one area are withheld from more interesting work elsewhere - their only crime being to become so proficient in one area that they can’t be risked elsewhere.
- Attrition. This one is linked to the previous point. Staff who are pigeonholed get fed up being the only expert, and unable to progress their career, so they move on.
“So, let’s just remember to share more.” The problem with this statement is that contextual information is delivered through many different communication channels (written, using numerous tools, verbal), and communication can be lossy. See below.

Ideas (in the idea cloud) are realised through software, and the work undertaken produces a Shared Context. Whilst all aspects of the software is retained, the shared context information splits into two paths:
- Information (context) that’s widely shared and retained and then fed back into our aggregation of ideas (the main ideas cloud). This is good.
- Information (context) that’s lost. This information was once known but is now nebulous. Assumptions are created around this lost information. This is bad.
WHAT ASSUMPTIONS DO
When we’re unsure of how something works we can:
Decision-making founded on assumptions is a game of risk. Incorrect assumptions may lead to unnecessary work, late learning, and failed outcomes. Even an assumption that is correct is still an assumption, creating uncertainty (e.g. Analysis Paralysis).
- Ask someone to explain it. This isn’t always possible.
- Investigate it ourselves. This may be possible, but takes time.
- Assume how it works.
Shared Context is shared through communication, but communication depends upon many aspects:
- Time. Things change over time. The longer it takes to share information, the more likely it's incorrect, and one reason to prefer JIT Communication.
- Availability. Are all stakeholders available to collaborate? When will they be? It can take days (sometimes weeks) to bring people together if they’re not sharing goals. The geographical distribution of teams across multiple time zones also creates challenges.
- Level of experience. How do we communicate with people of varying skill-sets and experience? Do we use a lowest common denominator, or assume a certain level?
- Subjectivity, perception and bias. People see things differently. Some only see the things they wish to see and ignore everything else, will only ask questions in their area of expertise (Rational Ignorance), or may focus on irrelevancies (Bike-Shedding).
- Memory. The memories you retain.
- The strength of a relationship(s). People with strong relationships try harder to share information than the ones without them.
- Communication style. The style of communication (e.g. dry, relaxed, reserved) can affect audience participation and retention.
- Retention strategy. Even if you record every detail, will it be found, be searchable, and will people go looking for it? For instance, how many of you regularly return to view a JIRA ticket after it’s marked as done?
- Communication medium. How is the information conveyed? Is it verbally, written, presentations, whiteboard drawings?
- Is the speaker extroverted or introverted?
- The audience size. Getting the balance right is important - too few and context isn’t shared widely enough, too many and we may be overcome by differences.
- Cultural and language aspects. Some cultures are more willing to question an approach than others. Some information gets lost in translation.
- Politics. Do others have different motivations?
No wonder it’s so difficult to communicate so effectively, yet the benefits of getting it right are vast, including increased (business) flexibility, (team/business) agility, (business) scalability, morale, and fewer Single Points of Failure.
REACTIVE OR PROACTIVE
Arguably software delivered without a Shared Context follows a more reactive model, whereas consideration of a shared context is a more proactive (and sustainable) model.
To my knowledge, there’s no recipe, nor any standard measure of either shared understanding or idea retention. In an ideal world every stakeholder gets the context they need, but reality is often different. Several approaches can help:
- Adopt aspects of BDD - a way to improve communication. Many of the discovery aspects of BDD - such as Example Mapping - promote the collaboration and alignment of diverse stakeholder groups, thus creating a degree of Shared Context. Another useful output from BDD are the feature definitions, written collaboratively using a common language (Gherkin), that both lowers the representational gap (LRG) and also acts as a form of Living Documentation.
- Use JIT Communication whenever possible to reduce stale information, and avoid unnecessary cognitive overload.
- Use more collaborative implementation techniques (discussed in the Indy, Pairing & Mobbing section).
FURTHER CONSIDERATIONS
- Work Item Delivery Flow
- Assumptions
- BDD
- Single Point of Failure
- JIT Communication
- Rational Ignorance
- Bike-Shedding
- Analysis Paralysis
- Indy, Pairing & Mobbing
DIRECT TO DATABASE
Direct-to-Database is an appealing pattern that I see again and again, mainly but not exclusively, on legacy systems. Except for the odd case, I’d generally classify it as an anti-pattern.
The premise is simple. By interacting directly with a data store - and avoiding building any intermediaries - we can share information, and build things, much faster. The consumer may be the user of a user interface (UI), or indeed, another system needing access to the data to perform some useful function. We’ll briefly visit both scenarios, but let’s start by looking at the user (interface) scenario. See below.
In this case a server-side user interface (UI) fronts a backend database, offering users the ability to perform a function and then persist the result back to the database. Initially, it's really just a thin veneer onto the database, with nothing between.
Things go well. New forms can be swiftly created, exposing data with minimal fuss, users are happy, and the business sees fast turnaround (TTM) with minimal spend (ROI). What’s not to like? Unfortunately Aesthetic Condescension has us in its grasp and we have lost our impartiality - “I can see it right there,” says one executive, jabbing a finger at the screen and declaring, “there’s nothing more to do...”. It's a very powerful argument, and one that is hard to counter. So, between the disquieting rumours that something isn’t quite right, we find this approach gaining more and more traction.
Of course, before long there’s a need to write business logic - and being nowhere else to put it (ignoring stored procedures), it must go into the user interface code. We also find a need to create a second (and third) UI to support other clients as they learn about the new tool. See below.

BESPOKE UI’S
Another problem I regularly see relates to the client services business model, and bespoke user interfaces. It often seems easier to duplicate a UI and then modify it for bespoke needs, than to create a generic solution and add branding. However, this is a mistake - business logic must now be repeated in two places, as must any bug fix or vulnerability patching.
The UI becomes bloated and we begin to see a pollution of responsibilities (due to a poor Separation of Responsibilities), thus increasing complexity. There’s also a duplication of effort, as the team makes the same change across the (three) UIs. This creates Change Friction, leading to an increase in delivery times. The team begins to complain about their workload and lack of staffing, and the business (incorrectly) rushes to recruit more staff (they should assess the underlying cause, which is less about needing more staff in the extremities, and more about applying them in the right areas).
FUNCTION SHAPES & SIZES
To my mind, this rhombus shape (below) nicely models the relative sizes of the three main functions comprising the three common application tiers:
- UI - a relatively small function that integrates with back-end applications.
- Business Tier (Applications & Data Engineering). Where most of the action is, and therefore the staffing needs. The business tier is (almost always) the most complex, and therefore requires the highest number of staffing, and thus, why it typically dwarfs the other two functions.
- Data storage (I mean administration, not data engineering). A relatively small function responsible for ensuring the databases are healthy.
It's now quite common to find all three representatives embedded in a single team.

My point? If there’s too much focus on the extremities (UI, or DB), then it might be worth considering why that is? A sudden spike of effort in one extremity may suggest a problem with focus (or strategy), rather than staffing needs.
Unfortunately, our problems don’t end there. By modelling the UI almost exclusively on the database model, we're also finding that our user experience suffers. Forms become glorified representations of the underlying database table (Don’t Expose Your Privates), and the user flow (journey) is heavily influenced (modelled) by how the internal data model relationships are navigated. We’ve forgotten to drive a top-down user experience.
And finally for the coup de grâce... One of the most changeable aspects of any software product is the user interface. What is modern one day, is tired only a short time later. There are many good reasons to modernise a UI, including Aesthetic Condescension on the part of your customers (new means good to many), internal stakeholder Bike-Shedding (they can't necessarily offer their opinion on system internals but they sure can on its UI aesthetics!), shifts in UI technologies, and more focus on mobile devices. A business regularly needs to modernise its product UI to present modernity to the market, increase sales revenue etc. In our case though, that opportunity is long gone - there’s too great an investment in the existing user interface to simply recreate it. This Change Friction has created a very serious Agility issue.
So, how does this happen? Well, the middle tier (e.g. service) is traditionally the hardest (longest) to create. Given the choices described earlier, some business leaders might ask why bother? e.g. “I can get the same functionality in half the time, simply by linking the UI up to the database.” This is certainly true, but caveat emptor! It’s a form of corporate Circumvention which may cause us to fail to adequately represent some very important qualities:
- Reuse. A (middle) business tier creates reuse opportunities for the same functionality across a range of UIs. It's common to make a product seem modern, simply by wrapping the existing business tier with a new UI veneer.
- Scalability. A (middle) business tier can manage workflow orchestration, caching, horizontal scaling etc, but there’s fewer opportunities to do this in our case.
- Manageability. A middle tier places seamless software upgrades within our grasp, through the use of techniques like Blue/Green Deployments, Canary Releases.
- Resilience. It may still be possible for users to use the system, even if some of the middle tier services are unavailable.
- Maintainability. Our example had three copies of (pretty much) the same UI application, built for bespoke clients. This creates a duplication of (the same) activities, across all clients, for every improvement or bug fix.
- Security. A (middle) business tier adds an additional layer of protection between attackers and the database.
- Usability. Direct-to-Database tends to cause “bottom-up thinking”, not top-down. Developers ask “How do I expose this table to the users?”, rather than “How do my users want to use this product, so how do I link that experience to the data model?”
- Evolvability. Encapsulation is a very important principle that - believe it or not - it's often ignored. There’s little opportunity to evolve anything if clients are tightly coupled to that technology.
SUMMARY
Direct-to-Database may well solve immediate TTM and ROI needs, but - to my mind - it’s often just a form of (corporate or technical) Circumvention, offering little in the way of Agility (e.g. difficulty in rebranding your product, or scaling up your business), nor a viable route to Sustainability.
There’s a reason why Three-Tiered Architectures and (more recently) Microservices have been so successful. They’re a conduit between the user (UI) and the data (database), adding an important (some might argue vital) ingredient. Circumventing an entire layer - for the sake of immediacy - is just a problem waiting to happen.
Whilst I see this approach used less with modern solutions, it still happens, generally as a response to TTM pressures, or due to some habitual use of the practice (the “they did it before me, so it must be ok for me to do it” argument - 21+ Days to Change a Habit). For instance, I commonly see legacy systems built to shift data to many other consumers using ETLs (ETL Frenzy), directly coupling the (E)xtract piece to another party’s dataset, data model, and responsibility. This is a form of Domain Pollution, often hampering Evolvability, and in more severe cases creating a large Blast Radius for even the simplest form of change (Change Friction and Stakeholder Confidence). Tread carefully...
FURTHER CONSIDERATIONS
- Circumvention
- Aesthetic Condescension
- Blast Radius
- Change Friction
- Bike-Shedding
- Blue/Green Deployments
- Canary Releases
- Domain Pollution
- Microservices
- 21+ Days to Change a Habit
- Stakeholder Confidence
THE SENSIBLE REUSE PRINCIPLE (OR GLASS SLIPPER REUSE)
The Sensible Reuse Principle is my response to something I see far too often in software development - the inappropriate shoehorning of a new function into an existing feature that isn’t designed to fit it.
GLASS SLIPPER REUSE
What better way to start a section than with a fairytale? In Cinderella [1], we find Prince Charming, enamoured by his chance meeting with a mystery girl at a ball, and utterly determined to find her again. His only clue to her identity is her one glass slipper, mislaid as she rushed away. Charming’s ingenious solution is to have every woman in the kingdom try on the glass slipper - the one it fits is his true love.
The slipper travels across the kingdom, and is tried on by every woman, even Cinderella's villainous stepsisters. Determined to be queen, they try every trick in the book, from trying to squeeze into it, to reshaping their feet to make it fit, to forcing their foot in, all in vain. The glass slipper was made for one, and only fits one foot - that of Cinderella.
The idea of reuse based on fit isn’t always what happens with software. When we see a potential opportunity for reuse, some are very quick to attempt to force or squeeze that solution into an existing model. Merton labelled this the “imperious immediacy of interest” [2]. This works well when they are closely aligned (e.g. similar benefits, behaviour, data models - think of a close intersection), but may be more trouble than it's worth at the other end of the spectrum, polluting the original, creating maintenance and comprehension challenges, or simply creating a Frankenstein's Monster System. Reuse should not be employed solely for the sake of it, but to offer some (preferably sustainable) benefit.
Poor reuse reasoning tends to occur for one of the following reasons:
- There’s a driving force making the reuse seem extremely attractive. This may be a delivery schedule (TTM), a spending cap (ROI), capacity limitations, or even political gain (see later).
- There’s no deep appreciation for the existing state, whether it truly is a close match for the new function, or for the second and third-order consequences of the decision (Merton’s “imperious immediacy of interest” [2]). In the Cinderella analogy, it's turning a blind eye to the obvious misfit of the stepsisters and allowing one of them to marry the prince.
- Bias, face-saving, or political gain. We often see execs/departments vying with one another for the business’ affections in order to get the best (most interesting) projects, or to advance careers. An opportunity to reuse (seemingly) benefits both the provider (offering the service) and the purchaser (business). This is psychology of the kind “We’ve already got this solution (since I was the one who requisitioned it), so we’re going to use it, regardless of its appropriateness.”
SENSIBLE REUSE
Sensible reuse is the ultimate form of TTM, ROI, and Agility, whilst insensible reuse infers the opposite.
Reuse comes in many forms (some far better than others). For instance:
- Copy and paste the code from one class into another to use in another solution.
- The business tier in a Tiered Architecture typically has a longer life cycle than (say) the UI layer, and sees more reuse.
- A Microservice can be reused/combined to build something different.
- A single user interface (UI) can be duplicated into another and rebranded. This is reuse in a very loose sense (I explain in Direct-to-Database why this is generally a bad idea).
- Build out a shared library that many components can use. Whilst this is generally a good idea, there are some who would suggest the opposite (from a strict microservices sense it may not always be sensible).
- Reuse an existing monolith (Monolith) to compose a larger system - a Monolith of Monoliths. Described later.
- Reuse an existing data model and relationships. Described later.
- Reuse through iteration. We can repeat an action simply by wrapping the logic in an iterative manner (loop). Described later.
- Field Reuse. Using a single API or database table field for multiple purposes. Described later.
- Reuse through Inheritance. The power of Inheritance may be dissipated if the parent class attaches inappropriate behaviours - e.g. if Student and Lecturer classes both inherit from an abstract Person class, should we embed database connection lookup utilities in the base Person class?
Let’s look at a few examples.
MONOLITH OF MONOLITHS
A Monolith of Monoliths offers a great example of inappropriate reuse. A monolith is atomic. You get all of it, regardless of whether you want it, need it, or you’ve already got it elsewhere. If we find that our monolith doesn’t contain the feature we want, we look elsewhere. We may find that feature within another monolith, so we must find a way to sew it in (integrate).
The result is a binding of several (possibly even hundreds in extreme cases) monoliths to create one giant monolith (a Frankenstein’s Monster System) with many disadvantages, including the Cycle of Discontent.
REUSE THROUGH ITERATION
It's quite normal (and appropriate) to reuse code through iteration, simply by wrapping a single execution of a section of code (algorithm) within a loop, and thus enabling it to execute many times. This approach is powerful and quick to develop - thus rather appealing - however, it still requires some caution.
Consider a user interface (UI) making use of a back-end API to display content to the user. Let’s say it’s used to visualise a software system (e.g. blocks interconnected). See image.
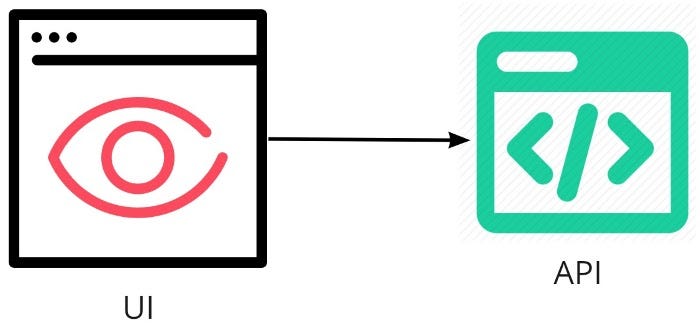
This works very well for a single remote interaction, but can create problems when (a) we approach this style iteratively and (b) that function is always assumed to be independent. The most notable concerns are:
- Potential performance (latency) issues. A single aggregated remote interaction can be an order of magnitude faster than the equivalent operation using multiple remote calls.
- User experience issues; e.g. the constant nagging of a proliferation of information/error dialogs presented to the user. Described later.
- Resilience. Is the business transaction intended to be atomic (all-or-nothing), such that a single failure will invalidate its entire transactional worth, or is it recoverable?
Let’s briefly examine the second point. Let's say we now want to scale up our visualisation solution (mentioned earlier) to display a much larger system, or a system of systems. In this case, we’ll achieve this by wrapping the original remote call in a loop. See below.

What’s going on here? Well, we’ve wrapped a remote API call, so it's now executed many times (not necessarily an issue); however, some cases have met with failure (e.g. HTTP 404s or 500s). The common logic we execute (reuse) iteratively assumes that the user should be informed of a failure (something that makes sense for a single interaction) - thus it presents an error dialog to inform the user to intercede. This is fine if it's a single dialog, but not if it's hundreds - definitely not an intended consequence of this reuse.
DATA MODEL REUSE
A data model may also be reused. Let’s say the data model is:
| X | —> | Y | —> | Z |
In this case X may have one or more Y’s, which may have one or more Z’s. This relationship is strongly represented (i.e. tightly coupled) in a relational database, using referential integrity. We can’t have a Y without an X, nor a Z without a Y. The user experience to populate this relationship is shown below.
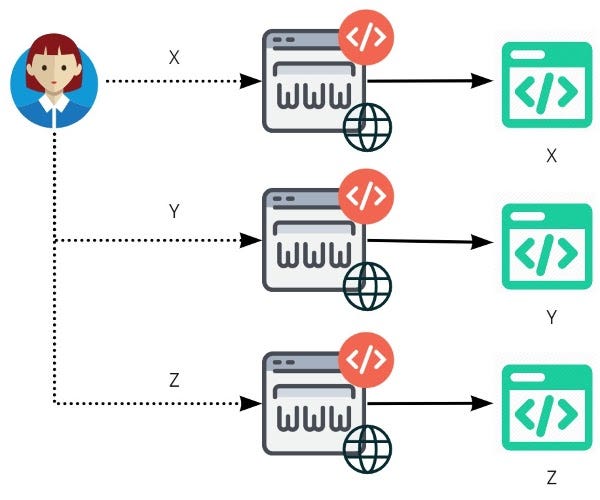
We model our APIs on this same business flow/relationship - the user completes steps X, followed by Y, followed by Z. This approach works well when all of those entities exist, but what happens if we now stumble upon a secondary business flow that only reflects Y and Z? See below.

Note that X isn’t modelled here, because the user doesn’t do it. This leaves us with a predicament - how can we model this (divergent) relationship?:
- Break the relational constraint to only allow Y and Z to be modelled. This may be appetising for this particular problem, but much less so for the already established business flow, APIs, model, and many persisted transactions. Change Friction - in this case - is probably high, since both the user interface and the corresponding APIs are already configured for the X -> Y -> Z relationship.
- Don’t reuse this model and implement something independently. Again, this suits this particular problem, but doesn’t necessarily suit the overarching business, who must now maintain two things that do (substantially) the same thing (e.g. two sets of APIs doing almost the same job).
- Rethink the entire model. Similar problems to above.
- Mock X with “fake” data, then populate Y and Z as normal. You could argue that this is the least invasive (it’s probably the easiest in terms of implementation), but it also creates issues around comprehension, coding, and then injecting that fake data into the UI and APIs at the appropriate time (remember, the user never adds this), and - of course - (not) reporting on that fake data.
- Use a looser-coupled model and/or a different technology, such that the relationship is more fluid. Again, we’re talking about significant change, which is rarely appetising.
Yep, there’s no easy answer...
PLAYING WELL WITH OTHERS
Some time ago, I proposed what I thought to be a decent alternative to an established product pricing feature. It had many positive traits, and I thought it would be eagerly adopted. The problem though, was that it came after an established solution. My proposal gained little traction, partly due to Change Friction, a large Blast Radius, and Domain Pollution from the existing solution.
The selected solution was a hybrid of both existing and new (my proposed) solutions, which was unfortunate, because my proposed feature lost some of its vigour as it became entangled in the current position, but entirely appropriate from the perspective of the product’s current state.
My point is that it doesn’t matter how rosy the future is if you must still consider the existing position (i.e. how the existing consumers will integrate with it). Never hold on to something that is excellent in isolation, but doesn’t play well with others.
FIELD REUSE
Data fields are used throughout software (from user interfaces, to APIs, to database tables). They are containers of data, typically of a certain type (e.g. string, integer, date time), and are often validated to meet certain business expectations. Combining them in different ways allows us to create more coarse-grained entities of almost infinite possibility.
So here’s the question. Would reusing a field, for an entirely different purpose (to have two purposes) be more, or less, prohibitive than introducing a new field instead? Still unclear? Let’s look at an example.
Assume that our example retailer - Mass Synergy - wants to offer its retail platform to clients. Those clients will create their own branded websites, but use Mass Synergy’s platform and services as a SAAS. Magic Cinnamon - an online cake-baking subscription service - wants a slice of the action (pun intended). During the sign-up process, a Magic Cinnamon customer can explicitly agree to receive a free magazine of recipes posted directly to their door. Of course this function is not catered for in the product (it has never even been considered).
This is a very specific (highly bespoke) requirement - and a typical problem for businesses who want both to build a generic product and still support bespoke client requirements. Mass Synergy doesn't want bespoke tailorings polluting their product, and thus limiting its reach and ROI, but they still want the custom. The business and technical leads from both sides get together to discuss their options, and eventually come up with the following solution.

Magic Cinnamon will continue to use APIs as-is, whilst the Mass Synergy team will introduce a new (bespoke) nightly extract process that identifies new registrations and sends them on to fulfilment. But how will they indicate a fulfilment request? During project inception, the teams found that Magic Cinnamon didn’t require all of the existing registration API fields. For instance, the giftedBy field typically holds the name of the person who gifted this item, but the concept of a gift doesn’t make sense here. The initial plan was to ignore (not send) this field, but they now agree to reuse it for recipe fulfilment (by supplying a value of “MAGAZINE” to indicate if a recipe book should be posted). See below.
{
"id": ...,
"surname": "Jackson",
"email": "supersuejackson889@zizzy.com",
"activationDate": "16/09/2021 15:09:34",
"giftedBy": "MAGAZINE",
...
}
The nightly extract job identifies any Magic Cinnamon customers that were registered on the previous day with a giftedBy value of “MAGAZINE”, and forwards them on to fulfilment.
Ok, so let’s discuss this approach. Firstly, would anyone really do this, and if so, why? Yes, it does happen. I’ve seen it used a handful of times [3]. The main cause is a lack of Control (typically over something others consume, like APIs), and a wish to avoid Blast Radius. You don’t want to (or can’t) change an API, model, or UI, but you still need to support a requirement never previously considered. Effort isn’t the only concern either - consideration should also be given to delivery timelines. Not everyone has Continuous Delivery Pipelines, automated Regression Testing, or regular releases. There’s many causes of Change Friction.
API CHANGE FRICTION
Without careful consideration, sensible SLAs, and Evolvability in mind, APIs can be horrendously difficult to change - mainly due to consumer life cycles. Any new version can be fought against (Change Friction) and requires persistent consumer coordination. Ideally this type of bespoke requirement would have already been considered (such as by attaching metadata), but it often isn’t (and not in our case), and leads us back to the initial reasons for avoiding change in the first instance (Blast Radius).
Let’s now consider our wins and losses. We’ve certainly saved ourselves the trouble of changing something that can be notoriously difficult to modify. But what’s been lost? Firstly, there’s increased confusion and lowered comprehension - for both parties. We’ve diverged from the intended use of the API, and created a couple of Knowledge Silos in the process. Secondly, where does it stop? Will this same approach be reused on other clients, for other bespoke needs? Thirdly, now that we’ve stuffed arbitrary data into a generic product location, we must keep the reporting team abreast of these specific requirements to ensure they don’t include this in generic reports. We’re building a product, but we’ve not (really) delineated between what’s a product, and what’s bespoke.
REUSE ABUSE
I’ve also seen a product identifier used for both a product, and to identify a discount code, hampering the client’s ability to modernise its database technology.
SUMMARY
This chapter was longer than I anticipated. I hope though that it demonstrates that not all forms of reuse are welcome, and some forms should definitely come with a caveat emptor. Sensible reuse is the ultimate form of TTM, ROI, and Agility, whilst insensible reuse infers the opposite.
FURTHER CONSIDERATIONS
- [1] - Cinderella - https://en.wikipedia.org/wiki/Cinderella
- [2] - Merton’s “imperious immediacy of interest”. The individual is so desirous of the intended consequence that they intentionally ignore any unintended effects of this course of action.
- [3] - I’ve also seen it used with dates (e.g. 01/01/1900) as an identifier.
- Unqualified Critics
- Change Friction
- The Curse of Duplication
- Blast Radius
- SLAs
- Regression Testing
- Frankenstein’s Monster System
- Cycle of Discontent
- Direct-to-Database
- Monolith
- Microservices
“DEBT” ACCRUES BY NOT SHARING CONTEXT
Debt in software manufacturing doesn’t just accrue from poor or incomplete software solutions, but also from an inability to share context (Shared Context). Context that is shared reduces Single Points of Failure, and increases Flow and Agility.
DIVERGENCE V CONFORMANCE
I’ll keep this short. A variation - or a divergence - from the norm creates specialisms, misalignment, and silos of expertise (Knowledge Silos). Uniformity - or a conformance - brings alignment and unity, as all representatives work from the same manual.
Conformance suggests “knowns”, produces similar results, scales well (more staff), and is easier to estimate (you’ve already done it multiple times). Divergence suggests “unknowns”, may produce unexpected results, scales less well, and is harder to estimate.
Divergence promotes Flexibility (choose whichever technology/approach you like) and supports Innovation, whilst conformance promotes Sustainability (choose from a wide range of staff) and makes that innovation a standard.
You need both in a technology business.
FURTHER CONSIDERATIONS
WORK-IN-PROGRESS (WIP)
Imagine that you work as waiting staff in a restaurant. Few customers visit before the peak times, so there's few “covers” (low WIP), and it's easy for staff to be attentive and offer a great service.
However, as the day wears on we see a big increase in the number of covers - often surpassing staff capacity - and the system begins to break down. Service slows, mistakes are made, food is produced too soon, or left too long and gets cold, the drinks order is wrong, staff are forced to Context Switch, and both customers and staff get irritated. Often, the deterioration is noticeable, so it's likely you’ve experienced it yourself.
Too much WIP creates concerns around Circumvention, Expediting, wait times, and isolated thinking:
- Corners are cut, from the more mundane (e.g. no ice in drinks, no garnish with your chicken, reusing table covers), to more serious ones affecting quality and possibly safety (e.g. a switch to microwave use, burnt or semi-cooked food being served).
- Wait times increase. A breakdown in quality may impede - rather than improve your position - as customers return unsatisfactory products (food).
- Self-defence mechanisms force staff to become more protective and insular. For instance, staff focus on their own efficiencies, but neglect the big picture. Tactics such as batching (e.g. cooking certain products in batches, which are then held up whilst the remainder of the “cover” is cooked) supplant strategy [1].
- Certain tables get prioritised regardless of any first-come-first-served approach; e.g. “The Richmond-James party is the wealthiest family in this town! So, prioritise their food...”. Be aware that the more work items in the system, the greater the chance of Expedited Leapfrogging.
- Specialisms and Single Points of Failure (Knowledge Silos). “But we always get Jeff to wait on us,” complains Mrs Richmond-James. “Jeff knows exactly what we like...” Sorry, but Jeff is too busy tonight. I think he’s coming down with something too! And yes, it’s unlikely that any stand-in for Jeff will satisfy Mrs Richmond-James, given they’ve been given no context.
- Difficulty in decision making, due to increased context switching (Buridan's Ass [2], The Paradox of Choice).
Whilst my analogies have mainly revolved around the hospitality sector, we see the same issues in software. Lots of WIP creates specialisms (e.g. Indy Dev), increases the likelihood of Expediting, increases wait times, thus reducing Flow, and facilitates Circumvention.
REVERT TO BATCHING
A system always has a bottleneck. In the hospitality analogy it might be the bar staff, the maître d', waiting staff, chefs, or the pot-wash. To be effective and offer a great service requires everyone across the whole system to work together - not just individually. This becomes increasingly difficult as WIP increases.
Batching is a common coping mechanism to pressure and isolation. For instance, if the kitchen receives three covers (totalling six Lobster Thermidor, two Chicken Chasseur, and one Fillet Steak), then there’s a danger of batching all lobster, meeting an individual commitment, but missing the goal (mistiming the remaining dishes in each cover).
Batching may increase WIP woes, not lower them, as products are discarded (due to timing), are returned for rework, or simply take forever to release value to the customer.
SUMMARY
Too much WIP pleases no one. Not your customers - who get a substandard service or product, and not your staff - who take pride in their work and don’t want to be under constant pressure.
WIP in any system (including software) should be carefully managed. It should be enough to satisfy demand, but not so much as to flood the system to the detriment of all.
FURTHER CONSIDERATIONS
- [1] - “The ultimate measure of a man is not where he stands in moments of comfort and convenience, but where he stands at times of challenge and controversy.” - Martin Luther King, Jr.
- [2] - Buridan's Ass
- The Paradox of Choice
- Circumvention
- Expediting
- Mobbing, Pairing, & Indy
- Single Points of Failure
"CUSTOMER-CENTRIC"
It seems to be all the rage for modern businesses (or ones aspiring to modernity) to suddenly declare themselves “customer-centric”. It makes you wonder what they were doing before this... Visit many corporate websites (and their corporate strategy) and you’ll see a liberal sprinkling of such terminology.
Whilst placing the customer first seems rather obvious and unremarkable, these statements may obscure something less appetising. However, to understand this, we must first discuss and compare the customer consumption models of yesteryear (which many established businesses have great familiarity with) and today.
If we were to travel back in time twenty years ago, we’d find a very different social and technological picture to the one presented today. One not long after the arrival of the internet, where Web Services were nascent, mobile technology was still in its infancy (I could phone or text people but not use the internet), there were the first stirrings of a social media revolution, and information infrastructure was patchy.
In the UK (at least), there was still a strong high-street presence. If you wanted to open a bank account, you visited your local high-street branch and arranged its opening. It might take weeks, but you expected it, because you were acclimated to it. If you wanted a new washing machine, you visited your local electronics store. They’d offer you a limited set of delivery slots and expect you to be in all day to receive the item. If you wanted to watch a film, you’d rent or purchase the physical DVD from your local store. Customers continued to conduct business with their current energy utility providers and banks because there was little alternative and change was too hard.
There were no (global) online retail businesses. No streaming services, market comparison sites, next day delivery as standard, or prompt and accurate delivery status notifications (this is a great feature). You see where I’m going with this? Expectation, and thus consumption, was dictated by local market factors - driven less by what the customer really wants, and more by the constraints imposed upon them.
The business practices, systems, communication mediums, and even their staff's working locations and hours - all formed twenty (or more) years ago - aren’t a good fit for modern expectations. Yet they’ve been inculcated and embedded into the culture of established businesses over many years, to the extent that the scale of change required in order to modernise is very very challenging (21+ Days to Change a Habit). Things have changed since then, placing a greater focus on customer-centrism, and challenging the way businesses function, including:
- Ravenous Consumption.
- Greater competition.
- Data-driven decision making.
- Continuous practices.
- Social Media.
- The Cloud.
- I’ll-considered growth.
- Agile practices.
I’ll describe each next.
RAVENOUS CONSUMPTION
I’ve already talked (Ravenous Consumption) about how consumerism has both increased our rate of consumption and increased our expectations. It's also made us less tolerant of slow, or late, deliveries.
Modern consumption habits were somewhat stoked by the technical innovations that came out of the Internet. No longer were we inhibited by local limitations, but we could now access a far wider, global, set of services brought to our door. A customer-centric position is one that delivers at a pace appropriate to customer expectations.
GREATER COMPETITION
Competition for custom, which was once more localised, is now global. If customers don’t find a product or service locally, they’ll look further afield. This makes every customer on-boarding onto your platform a small victory. But you must also keep them. That may involve regular improvements, building things they want, testing hypotheses, employing Fast Feedback, and Continuous practices.
DATA-DRIVEN DECISION MAKING
Remember the days before social media, data pipelines and warehouses, and Google Analytics? In those days, as a developer, it felt pretty rare to get the opportunity to talk directly to the customer. For me, requirements were fed through a series of intermediates (who sometimes added their own expectations), before putting it in front of us for implementation. It also felt quite common for executives to formulate their own interpretation of what the market needed, without necessarily consulting that market.
I would argue that there was (and sometimes still is) too much subjective decision making. Assumptions became commonplace due to the number of intermediates between the customer and engineer, the lengthy release cycles typical of that time (e.g. quarterly), and fewer options to capture metrics. Simply put, there were fewer opportunities to get objective, swift, and regular feedback.
But times are changing. There are many ways to capture data about your customers, and modern practices provide the means to deliver value swiftly. Feedback loops and empirical evidence are driving out decisions that may once have been tinged with bias and subjectivity. The challenge is no longer how to capture this information but how to sift through the vast quantities of captured data.
CONTINUOUS PRACTICES
Practices like Continuous Integration (CI) and Continuous Delivery (CD) help to put the customer back where they should be - at the forefront of your decision-making. Whilst not necessarily true of all, a significant proportion of internet-facing businesses are embracing these principles.
SOCIAL MEDIA
Social media didn’t (really) exist twenty years ago, so it wasn’t a pressing concern to businesses. No longer. Social media provides a quick, cheap, and expansive medium for customers to air their views on your product, service, delivery efficiency (e.g. late or lengthy deliveries), or customer experience. Social media affects branding (Reputation) in both positive and negative ways.
THE CLOUD
One might say that the Cloud was also spawned from such an environment. The customer’s desire for greater pace, flexibility, and better pricing efficiency were key to its creation. It’s very customer-centric, offering a wide range of services to choose from that are quick to provision, (relatively) easy to integrate, and aren’t charged for if they remain unused (e.g. Serverless).
AGILE PRACTICES
Nowadays, most of the customers I speak with expect regular releases that show progress, and enable them to steer things in the right direction. This is key to Agile delivery, and something Waterfall doesn’t offer. Agile is all about customer-centrism. You can find more information here (Agile / Waterfall).
ILL-CONSIDERED GROWTH
A strategy of growth (e.g. Economies of Scale) - typically executed through a series of mergers and acquisitions - that fails, may impede customer-centrism, as the business loses sight of their existing customers in its quest for growth, becoming overly outward-facing.
FAILURE TO GROW
Whilst this practice doesn’t fit directly into customer-centrism, the outcome of a poorly executed growth strategy most certainly does.
This problem will be familiar to those who’ve witnessed the epic rise and fall of businesses who either (a) grow at a rate faster than they can sensibly consolidate, or (b) fail to undertake sufficient due diligence on the technologies or practices of another merged business (a failing from that supplier often falls on the parent business’ shoulders). The harsh reality is that they’ve brought about a Self-Inflicted Denial of Customer Service (DoCS) - where the quality, delivery speed, or agility of the product/service being offered to the customer, in turn for their loyalty, is impeded - potentially causing reputational damage (Reputation). A lack of Consolidation then leads to massive complexity, brittleness, a large Blast Radius, and containment challenges. It creates Change Friction at both the technical and cultural levels (stability usurps change), and eventually reduces customer satisfaction (something you can ill afford in a globally competitive market).
If this strategy fails, then that business may return to an internal-facing outlook that has worked for them in the past, by refocusing on existing customers. Yet this is difficult if it accrues a lot of baggage during the growth stage.
SUMMARY
Being customer-centric in today’s climate is quite different to one twenty years ago, and requires businesses to be extremely agile, fast, and metrics driven. The benefits can be great (e.g. global reach), but so too are the challenges, especially for established businesses.
FURTHER CONSIDERATIONS
- Assumptions
- Ravenous Consumption
- The Cloud
- Change Friction
- Economies of Scale
- Lack of Consolidation
- Blast Radius
- Serverless
- Agile / Waterfall
- Fast Feedback
- Continuous Integration (CI)
- Continuous Delivery (CD)
- 21+ Days to Change a Habit
BRANCHING STRATEGIES
Suggested Reads: "Customer-Centric"
Aligning your code branching strategy around your business goals and aspirations is another important consideration.
“Hold on,” I hear you cry, “how can a code branching strategy relate to a discussion around strategic goals?” I’ll elaborate shortly, but first let’s discuss the qualities many customers now expect of modern businesses.
If we revisit modern Customer-Centrism, we find a synergy with many of these forces:
- Fast Feedback. We must listen to our customers and be nimble in how we change direction based on that feedback. It may involve us investing more in some areas, or even scrapping an idea entirely.
- Shortened integration cycles. Integration times are minimised to enable more immediate communication and shared context, even if the job isn’t yet complete. To analogise, consider someone doing work on your house. Would you rather be there to ensure the right decisions are made and work is implemented to your expectations, or return a week later to find the job isn’t to your liking? And what would that tradesperson prefer: immediate feedback with the (low cost) ability to change it, or a much bigger rework job later on?
- Make some noise! Noise can be a good thing in development. It shows that things are happening, but it also allows people to get involved, increase Shared Context, and therefore create Agility.
- Shift Left. Reduce handoffs and wait time by shifting activities (e.g. testing) to earlier in the development lifecycle.
- Canary Releases / A/B Testing. Trial a feature to a small number of users.
- Show don’t tell. Ask your customer by showing them. You’ll get a different - more accurate - opinion.
- TTM. Reach your (potential) customers quickly, ahead of your competitors.
- Reduce Manufacturing Purgatory. Reduce the amount of time a feature sits waiting to be delivered to the customer. This was typical in the days of Lengthy Releases.
- ROI. Only build things customers want. Do the right thing, over the thing right.
- Change direction based on customer feedback. Agility.
- Promote Innovation. Experimentation enables new approaches to be learned/discovered.
- Apply automation. You probably won’t reach your goals without automation.
- Regular releases, such as the famed 10 deployments a day.
Whilst there are several branching strategies, in reality there are only two models:
- Branch code.
- Don’t branch code.
We’ll visit both.
(FEATURE) BRANCHES
With feature branches, each feature is worked on in isolation (on a branch), and only merged back once work is complete. See below.

In this case Asha creates a branch for Feature A and begins working on it. Whilst Feature A is being worked on, Sally finds she also needs to make a change, so she creates another branch (Feature B). Timing is important here. Since Feature B was created before Feature A is complete, it doesn’t contain any of Feature A’s changes. Finally, Feature A is completed, (technical) code reviewed, and then merged back into the master branch, where it’s now accessible to everyone. Sally may now pull in those changes when convenient, and eventually merge Feature B back into the master branch.
Feature Branches have the following traits:
- There’s little outside noise, and integration is both more conventional and explicit, so it feels safer to many people. However, that depends upon your outlook. There are fewer individual merges than trunk development. However, the final merge is big, creating risk.
- Code reviews may be easier (all change is visible in a single commit allowing a complete picture - context), or it may be harder (there are so many changes that it feels like wading through treacle, so only lip service is paid to reviews).
- It's great for experimentation, or to share an idea, without attaching it to the real (working) solution.
- Poorer TTM. Slower feedback, and increased wait time. It's sitting on a branch after all.
- Poorer ROI. No return is had whilst code sits on a branch (indeed, it sits in Manufacturing Purgatory).
- Reaction times (Agility) are lowered due to slower feedback.
- Some Shared Context is lost, particularly between when the branch is first developed and when it’s tech reviewed.
TRUNK DEVELOPMENT
The alternative to branch development is trunk development, where no branching is involved. The key distinction being that committed (pushed) code is immediately integrated into the current working baseline - called the “trunk”. See below.
Note that changes are occurring on an (almost) ad-hoc basis, and that there’s no intermediate management layer (a branch) where code may sit for a while with impunity (Manufacturing Purgatory). This might seem strange (and disturbing to some) at first glance, being quite different to branching, however, bear with me.
At the start of this section I described how modern businesses look to TTM, fast feedback, early alignment, automation, Continuous practices, and agility for customer-centrism. In contrast to a branch - which may be radically different from the current baseline, and therefore harder to contextualise - work on the trunk is regularly reintegrated back into the current baseline, requiring far lower effort to contextualise (due to its low divergence). You’ve also checked whether it plays well with others, and not waited for a big-bang integration. This has the added benefit of Fast Feedback, both within the team - who all get early sight of the change and can assess/refine it, and also from the customer - value is delivered (almost) immediately to the customer, who can then determine if it’s what they really want.
Trunk development has its own challenges, otherwise everyone would be doing it. To some teams I suspect it’ll never be more than an aspirational state. For instance, the Safety Net of a (technical) code review, typical of branch development, can’t be done in the same fashion, due to the ad-hoc nature of commits. A different form(s) of safety net must be employed, typically through (a) a high degree of test automation (over 80% is a popular - if arbitrary - measurement), (b) TDD - which plays on the first point, (c) Pairing/Mobbing practices (which - to my mind - is a better substitute than a formal technical review), and (d) Quality Gates.
Finally, consideration should also be made for promoting unfinished software - code that’s syntactically correct and executable, but not quite ready for users to access. Feature Flags and/or Canary Releases are commonly used here.
SUMMARY
The decision as to whether to branch has implications that you might not expect, including how and when you deliver software (value) to your customer, and how successful context is shared across a team (Shared Context).
To my mind, branching is an isolationist strategy, and as such it may create:
- An unnecessary differentiation, and thus a divergence.
- Silos, and thus another form of Manufacturing Purgatory.
- Some loss of Shared Context, mainly due to it being a form of purgatory.
- Risk. The longer the branch exists, the greater the potential to further divergence, and the harder it becomes to merge.
But it can also be a good way to experiment, and is a well-established practice.
Whilst trunk development is in many respects a better approach to achieve modern customer-centrism, it’s also much harder to integrate. Even with supporting practices - like TDD and Pairing/Mobbing - it's fair to say that it requires a greater amount of cultural reform.
FURTHER CONSIDERATIONS
- Customer-Centrism
- Manufacturing Purgatory
- Shared Context
- TDD
- Mobbing, Pairing, & Indy
- Canary Releases
- Safety Net
- Shift Left
- Feature Flags
- Fast Feedback
- Innovation
- Lengthy Releases
LIFT-AND-SHIFT
Lift-and-Shift is the practice of lifting an existing solution, and shifting it to another environment in order to leverage some of the benefits of that new environment. It’s a term most commonly associated with migrations from on-premise to the Cloud.
Lift-and-Shift is a tantalising prospect - particularly to business and product owners, but possibly less so to the technology teams maintaining it. It suggests that the lifetime of an existing product can be extended, and the overall offering improved (at least in some way), simply by shifting it onto another platform. However, this is only a partial truth.
Many of the solutions earmarked for Lift-and-Shift are legacy (e.g. Antiquated Monoliths). As such, they come with legacy problems (e.g. inflexible technologies, poor practices, manual Circumvention, security concerns, slow delivery cycles, and costly scaling) which when unresolved are again reflected in the lifted solution. There’s no such thing as a free lunch.
FURTHER CONSIDERATIONS
TEST-DRIVEN DEVELOPMENT (TDD)
In this section (Why Test?) I described why we test software. Testing isn’t solely a means to ensure quality, it’s also an important practice to enable fast change and feedback, and to promote Innovation. Testing also helps to identify and resolve defects early on in the release cycle: “The later that we check for quality, the costlier a breakdown in quality is. Both monetary, and time. Additionally, a lack of (sufficient) tests/testing may also risk reducing business Agility, and impede our ability to Innovate.”
One of the most cited studies on the financial costs of defects (originally by IBM) indicated that the cost of fixing the same defect in production could be four or five times more expensive than doing so in development. [1] Therefore, we can make the following deduction. If software has fewer defects (i.e. better quality), or if they’re caught earlier on in the development lifecycle, then we can reduce costs. This is something TDD can support.
So what is Test-Driven Development (TDD)? Well, to understand TDD’s usefulness, we must first step back in time.
WHY TDD?
When I first started out in the industry, software was built using a very formal waterfall process (Waterfall). Business requirements were captured in an enormous requirements document that was subsequently translated into a more detailed design and specification. Those designs would then be implemented, before being packaged and deployed for formal system testing. In those days there were very formalised delineations of responsibility.
As developers, we would build each function to specification, undertake some manual tests (based upon another formal test specification document) to get a general feel for its quality, and then throw it over the fence to system test (often weeks or months later) to prove its correctness. I wrote very few tests, although I did manually undertake many. You won’t be surprised to know that this was a very long and convoluted process, often creating Ping-Pong Releases. Alongside these development practices were large monolithic deliveries (Lengthy Release Cycles). Feedback was hampered by (amongst other things) manual testing, long wait times, large batches per release, and an over-the-fence hand-off mentality. The take-away for this section though, is that significant testing was undertaken after the software was built.
Equally concerning was the (released) code quality across the business. The code tended to be overly procedural (even though we were employing object-oriented practices), resulting in Fat Controllers and God Classes that were very difficult to maintain. What I didn’t know then, but I do now, was that it was heavily influenced by the testing approach. In some respects, code that is only tested at a coarse-grained feature level is more likely to be messy (even with code reviews), because only the externally perceived quality is being verified.
Fast forward maybe five years and I began to learn about unit testing. These unit tests were great - they helped to ensure the software I wrote functioned, but we were still treating them as a second-class citizen, and only written after the software under test was implemented. System testing was still heavily involved in verifying the quality of the implemented features.
However, whilst I was hidden away in the depths of conditional statements and for loops, something else was happening in our industry. The Internet was driving new consumer habits and expectations (Rapid Consumption). It caused (as it continues to) us all to reassess how (and how quickly) we deliver customer value (Customer-Centric), led us to reconsider our existing, established practices, and was highly influential in the industry’s Shift Left policy. See (a simplified view) below.
This policy caused a gradual blurring of what were once distinctive roles and delivery stages. Developers and testers got invited to requirements gathering sessions - once only the mainstay of customers and Business Analysts - to hear first-hand about customer needs and begin a dialogue. A major shift left. Some aspects of testing - once thought to be a practice solely for testers and of finished software - began to be embedded within the development lifecycle and undertaken by developers. Another shift left. Deployments and operations - historically the responsibility of a centralised operations/sysadmin team - began to be undertaken (with the help of automation) by developers and testers, following the “You build it, you run it” mantra. Another shift left. Even the premise of Cross-Functional Teams is to short-circuit established silos, improve communications, and (you guessed it) support Shift-Left. Each step was an evolution, meant to enable faster delivery and feedback, yet still retain (or improve) quality, and mainly to support modern customer expectations. TDD fits well with this idea of shift left (as does BDD, which I’ll discuss in a future chapter).
Test-Driven Development then is a practice for building better quality software, through the use of a lifecycle that promotes incremental change and a test-oriented delivery model. It’s another element of what I term FOD (Feedback Oriented Delivery). TDDs benefits include:
- The code we build tends to be more modular and has greater cohesion, enhancing Flexibility, Reuse, Maintainability, and Testability.
- It promotes faster lead times over the medium-to-long term. Note the distinction. I’ll cover this a bit later.
- A Safety Net for future change and Innovation. Code tends to have greater coverage, increasing confidence as we make changes in the future.
- It promotes a greater degree of automation. Again, this one sits in the greater coverage camp. Because more code can be tested, and it’s undertaken earlier, then more automated tests are available.
- There is lower development risk due to the incremental nature of each change. The feedback loop is very short, ensuring we can’t go too far astray.
- It promotes a consumer-driven model, where the contract is considered before the implementation. There’s many ways to do something (the realisation of an idea - What Is Software?), so it’s often beneficial to know what you want to achieve (your goal) before identifying a solution. Driving change from the alternate perspective (bottom-up) often leads to the Tail Wagging The Dog - either ideas are polluted by existing implementations, or there is no clear view of the goal. Working from the top-down (consumer-driven) perspective however, acts as a form of reset switch - you must stop thinking about what’s already there (else it pollutes perspective), and build something from the goal. I describe this approach in Consumer-Driven APIs.
- The TDD lifecycle works with all forms of delivery collaboration (indy, pairing, and mobbing).
- Better Shared Context alignment. Because development of the implementation occurs in step with the tests, we can be sure that they are both closely aligned. This is unlike unit testing as an afterthought, where tests are created after (sometimes months or years) the code has been implemented, resulting in the loss of implementation context, which must be relearned.
- Greater dependency awareness than an untested or tardily tested solution.
- And last but certainly not least, TDD typically produces better quality code, with fewer defects.
THE TDD LIFECYCLE
The practice of TDD is founded on a simple (yet powerful) incremental change lifecycle. See below.
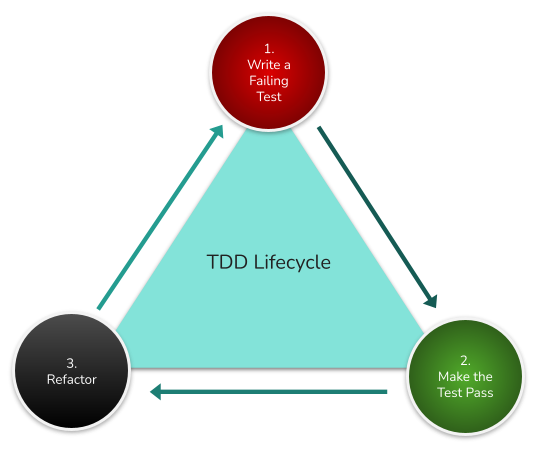
The stages are a repeatable pattern of:
- Write a failing test. This stage gets you thinking about the goal and a testable outcome. It’s more concerned with the contract over the implementation. The test represents the specification of what should occur (and can sometimes replace requirements documents). It tests the outcome, not how you get there. The test should fail, enabling it to be resolved in the next stage.
- Make the test pass. The test should be made to pass by implementing the code to produce the desired outcome. This should be done as quickly as possible (no procrastination); i.e. we find the simplest thing we can do to make the test pass, thus creating a Safety Net.
- Refactor the implementation (and test) code as required. We can do this because we created a Safety Net (something of great value) in the last stage, allowing us to refactor (if necessary) our original implementation into something more robust, performant, cohesive, maintainable etc. This stage is important and should not be circumvented, lest we end up with a major (big-bang) refactoring at the end - certainly not our intent. If pairing is being employed then this is also an opportunity for an informal (ad-hoc) code review.
It’s worth reiterating that TDD is less about the tests that are written and more about writing software that is highly testable. It's through the application of the TDD lifecycle that provides the improvement framework. TDD is not the same as a test-first strategy, where a host of tests are written up front, prior to any implementation code. All of the artefacts (code and tests) built with TDD are written in lock-step to ensure (a) Shared Context is maintained, (b) feedback is swift, and (c) that quality is built in incrementally.
SUMMARY
That all sounds great, and it mainly is. But we should also discuss why and when TDD becomes less suitable. For instance, I wouldn’t use TDD when embarking on highly innovative work containing many unknowns. If a man is lost in the woods, unsure of the direction to his salvation, then lugging around a heavy sack of gold (the tests) quickly becomes a hindrance. In these circumstances, TDD may be unwelcome.
There’s also a point around short vs long-term delivery, and sustainability. Let’s say you’re creating a prototype for an imminent trade show. It’s not meant to be a finished product, just one that can demonstrate capabilities. There’s little time to waste, so (a) why waste time and money on testing a throwaway item, and (b) should you really invest an additional (15%-35% development) effort when there are more pressing concerns? Additionally, are you really going to benefit from increased internal quality in this scenario (Value Identification)? Of course not.
Of course this is a very short-term view, one (rightly in this instance) inconsiderate of medium-to-long term productivity and sustainability. TDD comes into its own when you consider the repeated (and sustained) delivery of features by promoting every future change, providing a Safety Net, and supporting Innovation. TDD makes change sustainable.
FURTHER CONSIDERATIONS
- [1] - https://www.celerity.com/the-true-cost-of-a-software-bug
- https://raygun.com/blog/cost-of-software-errors/
- Why Test?
- Innovation
- BDD
- Shift-Left
- Shared Context
- Safety Net
- Cross-Functional Teams
- Value Identification
- Consumer-Driven APIs
- Tail Wagging the Dog
- What is Software?
- "Customer Centric"
- Rapid Consumption
- Lengthy Release Cycles
- Waterfall
DECLARATIVE V IMPERATIVE LEADERSHIP
In this section (Declarative v Imperative) I described how the declarative v imperative model fits in relation to systems and development. But it need not stop there - this thinking also fits well with a leadership style.
Let's start by describing the two leadership approaches:
- Imperative; e.g. “Ok, do it like this, then do that, and then do this. No, not like that, like this.”
- Declarative; e.g. “Ok, this is how it should look, and it should have these qualities - can I leave it with you to figure it out?”
Fundamentally they’re different ways to achieve the same output (the completion of a project or task), yet they typically have different outcomes (such as on sustainability). Let’s look at them.
IMPERATIVE LEADERSHIP
This approach is mainly driven by one person telling others exactly what to do, how to do it, and the order in which to do it. The leader is (probably) deeply involved in the implementation work, and therefore involved in (and responsible for) how the outcome is reached. See below.

The red circle represents the amount of effort the leader is expected to expend supporting that team. Note how it almost entirely fills the “Leader” circle on the right. There’s little time to undertake other work as a significant chunk is taken up with team interactions. Let’s now look at what happens when that leader has other responsibilities (such as supporting multiple teams, or other strategic work). See below.

The red circle continues to represent the interaction between the red team and the leader. However, we also have two further interactions. The green circle represents another team (the green team), also requiring support from that leader, yet the leader isn't in a position to help. The purple circle is another stream of strategic work the leader is also expected to undertake, but again, is unable to tackle. What’s happened here is that the leader is so flooded with imperative requests from one (red) team that they are unable to fulfil their other obligations.
LEADERSHIP CONSTRAINTS
This harks back to the Theory of Constraints. In this case the constraint is the leader, so everything depends upon both their availability, and their capability (abilities and knowledge).
If I were to use an analogy, imperative direction would be the guardrails employed in tenpin bowling to prevent the ball from going down the gutter. These guardrails are failure prevention mechanisms that may be used to build up confidence, particularly for new players. What they’re not though is a sustainable way to learn and master the game. At some stage they must be lifted. In software terms, the team employing a guardrail (a leader in imperative mode) should be using it to familiarise and improve themselves, in preparation for that guardrail being lifted.
The imperative mode then suits activities where the team may be inexperienced in that area and need support, but it can also be extremely useful when timelines are very tight and the outcome is business critical, typically because it gets results sooner. So why would anyone consider the alternative?
Well, it falls back on the old argument of short-term benefit v long-term sustainability (such as Unit-Level Productivity v Business-Level Scale). Whilst the upside of imperative is indeed swift delivery, the downside is that - dependent upon the leader’s outlook - the team isn’t truly learning the skills needed to succeed, and they remain strongly reliant upon the leader’s guidance. A leader more invested in the short-term - or in creating a name for themselves - may create a situation where the guardrails can never be lifted. Additionally, the team may also be learning bad habits - an expectation is raised that undertaking any critical activity requires the leader to be deeply involved in the minutia. To me, this isn’t leadership. Move at pace, but don’t allow that pace to create a Single Point of Failure that hampers sustainability.
SUPPORTING & DOING
There’s a fine line between leaders offering support, and performing the entire job for another. A leader put in this position must know both their own role and the minutiae of everything necessary to support the team at that granularity. It's not impossible, it's just unsustainable.
There’s also another - albeit more cynical - view. Whilst I don’t consider this widespread, some individuals may relish the possibility of becoming a passenger, of having someone else do the heavy (cognitive) lifting, whilst they only do enough to be seen to participate, aren’t truly engaged, and are learning very little. These individuals may even come to expect it for every other important project.
IMPERATIVE THROUGH NECESSITY
Of course there will be situations that force a leader to behave imperatively, even when it’s undesirable to all. This might, for instance, be a looming deadline, or a newly formed team not quite ready to work imperatively, or even an established team with little experience using modern technologies and practices. Even so, a good outcome is one that both delivers the feature and enhances overall sustainability.
IMPERIOUS IMMEDIACY OF INTEREST
I’ve worked with a range of different leaders, including ones who’ve seemed unable to progress past an imperative style. These leaders spend most of their days down in the weeds, directing and micromanaging the minutia, even when their role was strategic. Worse, rather than being reminded of their other duties, often they were congratulated for their heroic endeavours to (once again) save the day and deliver a feature in record time.
What’s wrong with that? Well, we humans seem to have an inherent weakness to overlook the consequences of “work heroism” - as if there were none - and proffer only plaudits. But… any action has consequences.
I’ve witnessed some of the consequences of overusing this tactic, including:
- The strategic work wasn’t being done (in a timely manner), leaving the wider team rudderless, and progress reports rushed or incomplete.
- The other teams in the wider group were left short of work, as it couldn’t be proactively prepared for them. This (of course) led to more “heroism” from that individual, except this time it rested with the other team (you see the pattern?). As the fires sprang up, that individual was always on hand to put it out, but no one thought to ask where (and why) those fires had originated from.
- Team learning was affected as it became a regular occurrence. The leader began to “steal the team’s” learning - always forcing them down their (imperative) route, allowing them no opportunity to identify their own best route.
- And most seriously, the team stopped thinking, or asking why, and just started doing everything they were told. Thinking people have passion and motivation. They will go above and beyond because they are engaged, challenged, and they care. People who aren’t challenged, are spoon-fed, and are unable to innovate, typically suffer from low morale. I remember vividly one developer saying that he’d stopped trying to think, and was simply following directions. He left soon after.
- The leader didn’t have time (or an inclination) to engage their listening mode, only their broadcast mode. They weren’t deeply engaged in another team’s problems so had no Shared Context. Consequently, they would dive right into the action based upon a murky account of the problem, making false assumptions, and reiterating solutions to problems already solved. This is like visiting a doctor with an ailment and that doctor immediately prescribing a treatment before you’ve given an account of your ailment.
Put simply, this model doesn’t scale well. Leaders caught up in a repetitive imperative cycle are probably spending so much time supporting, nurturing, and nursing a team, that they lose sight of the big picture. Atrophy occurs, and other parts of the body deteriorate. Those leaders begin to work in a short-term mindset. If I were to borrow from a biblical expression, working continuously in this style is like robbing Peter to pay Paul. You gain short-term benefits for longer-term sustainability costs.
It may also result in a Single-Point-of-Failure, Context Switching, and Expediting. The leader becomes the constraint as a new priority is raised, causing them to switch cognitive effort onto another task and then expedite it, thus creating a vicious circle.
One person's leadership is another’s micromanagement. Micromanaging a capable team will likely create animosity (aimed at you), and you’ll find yourself in their way.
DECLARATIVE LEADERSHIP
The declarative approach is quite different to the imperative model. In this model the leader provides the team with a vision, a general direction, and a desirable outcome; and then lets them figure out the rest. They frame the problem and indicate what’s needed, not how it's achieved.
The challenge here is being explicit enough to ensure that the team builds in the expected qualities (so they are exhibited in the final product), but not so rigid as to hamper them from finding the right solution to the problem. If the leader is too standoffish, insufficiently descriptive, or the problem isn’t fully understood or appreciated, then we may find a poor solution being built.
COMMUNICATION STYLE
Using a declarative mode doesn’t mean no communication, nor a one-off, fire-and-forget communication. It should be an open dialogue, allowing the team to (re)confirm acceptance criteria, broach problems uncovered during the implementation, or discuss quicker ways to gain feedback.
Here’s an example of a leader working in declarative mode.
In this case the leader is much freer (than in the imperative mode) and therefore able to support a much wider range of initiatives. The teams are working more autonomously, and are able to make judgement calls and adjustments about how best to solve the problem.
Declarative then may be about performance, but it’s definitely about sustainability. It works best either when the team is capable (declarative in a highly-effective, self-organised team is nirvana), or when the business is comfortable building up that capability, and willing (initially) to accept longer cycle times. In this second case, progress is initially (note the distinction) slower because the team is learning, through trial and error. However, each subsequent delivery gets faster and faster, as the team benefits from experience, to the point where there is little need for the imperative mode.
SCALING THE MODES
Like with other sustainability-oriented practices (e.g. TDD), you won’t necessarily get immediate benefit from declarative, but you do get scale and sustainability.
SUMMARY
Imperative and Declarative are different ways of leading that solve (but may also create) different problems. There’s a time and a place for both. To my mind, good leaders can work in both styles, and more importantly, know when to use one over the other.
In a sense, these models are similar to conducting (in an orchestra) and choreographing (as in dancing). Imperative expects the conductor to help others produce music. The conductor can make something harmonious, enabling a group to deliver sooner, but the group is only learning what the conductor is able (or willing) to teach. Consequently, they are not learning through experimentation (which also involves thinking and making mistakes) - one of the most effective ways to master a skill. Additionally, conducting doesn't scale. A conductor can only conduct one group at a time, so any other groups are demoted.
I’ve seen this model time and again. “Myopic leadership” spend too long conducting small groups that there’s little room left for strategy or sustainability, only the same tactics applied cyclically from one group to the next, to the next. It's good to move at pace, but don’t let it create a Single Point of Failure, and always leave a team in a better place than when you started.
FURTHER CONSIDERATIONS
- Declarative v Imperative
- Expediting
- Shared Context
- Single Point of Failure
- Test-Driven Development (TDD)
- Theory of Constraints
- Unit-Level Productivity v Business-Level Scale
THEORY OF CONSTRAINTS - CONSTRAINT EXPLOITATION
The Theory of Constraints has one key takeaway. An hour lost to the constraint is an hour lost to the entire flow. Or to put it differently, no matter how many productivity increases or waste reduction exercises are made in other areas, the constraint dictates all - an hour lost there cannot be regained through improvements elsewhere. So, identifying, exploiting, and elevating the constraint (and nothing else) is a vital part (in fact the only way) of increasing overall capacity and throughput.
I read this over and over and over; and whilst I understood what was being stated, I found it hard to reconcile with. For me, it felt like some sort of Cognitive Bias was working against me - I understood it, but I struggled to adopt it. Maybe I think differently to others, but I prefer visual descriptions (which is what you’ll find here), that I can return to regularly if I need reassurance, or if I’m demonstrating the principle to others. I hope you find it useful.
In this section I visually describe three examples:
- Exploit and elevate a workstation prior to the constraint; i.e. what happens if we improve a workstation prior to the constraint?
- Exploit and elevate a workstation after the constraint; i.e. what happens if we improve a workstation after the constraint?
- Exploit and elevate the workstation with the constraint; i.e. what happens if we improve the workstation with the constraint?
ELEVATE STATION PRIOR TO CONSTRAINT
If we elevate a workstation prior to the constraint (which is B), we get the following outcome:
| Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 0 | 1 | 0 | 5 | N/A | 0 | 0 |
| 1 | 5 | 4 | 1 | 0 | 5 | 1 | 4 | 1 |
| 2 | 5 | 8 | 1 | 0 | 5 | 1 | 8 | 2 |
| 3 | 10 | 17 | 1 | 0 | 5 | 1 | 17 | 3 |
| 4 | 10 | 26 | 1 | 0 | 5 | 1 | 26 | 4 | Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
Note that this may be any workstation before the constraint, not necessarily the one immediately prior.
In this case our constraint is workstation B (marked in red). At Time Unit 3, something is done to increase workstation A’s capacity (essentially doubling its output from 5 to 10 units). What’s interesting is the overall flow outcome (the Throughput and Done columns). We find:
- It made no difference to our throughput.
- We have increased the amount of inventory (waste) in front of our constraint. It’s now increasing by a rate of 9 units rather than 4.
If we were to pursue this approach further - and assuming no other variances (unlikely in reality) - we would find no increase in throughput, but an increasing amount of inventory in front of B.
ELEVATE STATION AFTER THE CONSTRAINT
If we elevate a workstation after the constraint (workstation B), we get the following outcome:
| Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 0 | 1 | 0 | 5 | N/A | 0 | 0 |
| 1 | 5 | 4 | 1 | 0 | 5 | 1 | 4 | 1 |
| 2 | 5 | 8 | 1 | 0 | 5 | 1 | 8 | 2 |
| 3 | 5 | 12 | 1 | 0 | 10 | 1 | 12 | 3 |
| 4 | 5 | 16 | 1 | 0 | 10 | 1 | 16 | 4 | Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
Note that this may be any workstation after the constraint, not necessarily the one immediately afterward.
In this case our constraint is workstation B (marked in red). At Time Unit 3, something is done to increase workstation C’s capacity (essentially doubling its output from 5 to 10 units). What’s interesting is the overall flow outcome (the Throughput and Done columns). We find:
- It made no difference to our throughput.
- Whilst we haven’t increased the amount of inventory (waste) in front of our constraint (it remains increasing at the same rate of 4 units), we've now (further) starved workstation C of work. That workstation/team is significantly under-utilised.
Were we to pursue this approach further - assuming no other change - we would find no increase in throughput, and very bored, under-utilised staff.
ELEVATE STATION WITH CONSTRAINT
Finally, let’s look at what happens if we elevate the workstation with the constraint (initially workstation B). Assume we can always feed A with sufficient work to fill it.
| Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 0 | 1 | 0 | 4 | N/A | 0 | 0 |
| 1 | 6 | 5 | 1 | 0 | 4 | 1 | 5 | 1 |
| 2 | 6 | 10 | 1 | 0 | 4 | 1 | 10 | 2 |
| 3 | 6 | 11 | 5 | 1 | 4 | 4 | 12 | 6 |
| 4 | 6 | 12 | 5 | 2 | 4 | 4 | 14 | 10 |
| 5 | 6 | 13 | 5 | 0 | 9 | 7 | 13 | 17 |
| 6 | 6 | 14 | 5 | 0 | 9 | 5 | 14 | 22 |
| 7 | 6 | 12 | 8 | 0 | 9 | 8 | 12 | 30 |
| 8 | 6 | 10 | 8 | 0 | 9 | 8 | 10 | 38 |
| 9 | 6 | 8 | 8 | 0 | 9 | 8 | 8 | 46 |
| 10 | 6 | 6 | 8 | 0 | 9 | 8 | 6 | 54 |
| 11 | 6 | 4 | 8 | 0 | 9 | 8 | 4 | 62 |
| 12 | 6 | 2 | 8 | 0 | 9 | 8 | 2 | 70 |
| 13 | 6 | 0 | 8 | 0 | 9 | 8 | 0 | 78 |
| 14 | 6 | 0 | 8 | 0 | 9 | 6 | 0 | 84 | Time Unit | A’s Capacity | B’s Inventory | B’s Capacity | C’s Inventory | C’s Capacity | Throughput | Overall Inventory | Done |
This is far more interesting, and illuminating. I’ve also elaborated (to include 14 time units) to provide a more comprehensive view.
Firstly, you might see that we’re playing our very own version of Whac-a-Mole [1]. As the constraint pops up, we need to identify it, and give it a whack (exploit it). Note also that there’s nothing to stop an exploited workstation from once again becoming the constraint, and thus needing further exploitation (see workstation B in time units 0 and 5). You may also have spotted something about how the constraint was identified. There’s two characteristics useful for identifying the constraint:
- Workstation capacity. The workstation with the least capacity should be the constraint. Theoretically, this is easy to spot, however it’s less so in practice. For instance, how do you determine the constraint if multiple workstations have similar capacity? Small variances (which may be ephemeral) within a workstation can also hinder us (such as flex in team structure, shorter working days, or a productivity increase not promulgated outside of the team).
- The build up of inventory preceding each workstation. The workstation with a low capacity, which is also seeing increased inventory directly preceding it, is likely to be the culprit.
TEAM VELOCITY & QUEUES
When we talk of capacity and inventory in software, we are typically talking of team capacity (e.g. velocity in Scrum) and queues (backlogs).
Secondly, for each row, compare the throughput value to the constraint’s capacity. Except in special circumstances (which I’ll describe shortly), the overall throughput is always the same as the constraints capacity. It’s clear in time units 1 to 4 that there is a relationship. But then something strange happens. We see some variation between the constraint and throughput, for a while (compare time units 5 to 6, and time units 7 through to 14), before it settles back down to the constraint capacity.
For a short while, we find the overall throughput is greater than the constraint capacity. So what’s happening here? Well, we haven’t considered the inventory that is currently in the system (our Manufacturing Purgatory). Notice at time unit 7 that B’s inventory was 14 units (taken from time unit 6, prior to processing)? Each workstation will process its inventory, in addition to any new items it is fed, until there is no more inventory around the non-constraint workstations - at which point the constraint dictates again. This occurs at time unit 14.
Also note that significantly increasing the capacity of the current constraint doesn’t necessarily mean that the overall flow will exhibit that throughput. To see this, look at time unit 5. We significantly increased workstation C’s capacity (from 4 to 9 units), but the overall (flow) throughput never reached it. Why? Because throughput is still determined by the constraint, and C is no longer the constraint - it moved to workstation B. The constraint started at B, moved to C, then back to B, and then on to workstation A.
SUMMARY
I’ve already mentioned that some of the terminology used here originated from the manufacturing industry (workstations and inventory), and is not the typical parlance of the software industry - who tend to use terms like teams, queues, and tickets. This is nomenclature, the concepts are the same whether you use workstation or team, inventory or queues.
To recap, what I’ve shown in this section is that any improvement on a non-constraint has no (sustained) effect on the overall throughput. None. Nothing. Nada. The only way to increase the overall throughput is to exploit the constraint. There’s two challenges to this thinking:
- Convincing others. I’ve already mentioned how hard I have to fight my own cognitive bias to reconcile with it.
- Convincing inward-facing teams to consider the system-wide impact of their own internal improvements, and more fundamentally that their own waste rationalisation schemes may transform, rather than extirpate waste. This is the return of our old friend (Unit-Level Efficiency Bias) - teams that focus on their own improvements may neither help the goal, nor reduce waste; they simply shift it.
THE TRANSFER OF WASTE
I see individuals, teams, or departments regularly promote efficiency improvements internally but remain unaware (willingly or unwillingly) of its effect on the overall “system”. For example, I commonly see teams resolve their own Waiting waste (in TIMWOOD) through the introduction of automation, enabling them to do more, and thus reduce their own wait times. Yet, they’re not looking at the whole, and may simply be shifting waste elsewhere (becoming someone else’s problem, typically the constraints), from waiting waste into inventory waste.
See Waste Reduction for more information.
Ok, so now we have a pattern to identify a constraint, the next logical question might be to look strategically, and ask whether we could preemptively identify the sequence of constraints as a form of constraint forecasting? This idea is very appealing. If we can forecast what our constraints will be, then we can formulate a sequence of improvement transitions, and bring a level of Control to a fluid situation.
The problem with this approach is threefold:
- It undermines one of the Theory of Constraint's most important qualities - its ability to focus everyone on a single goal. If we could forecast constraints, then we’d likely find the group splits to tackle them independently (divide and conquer), whereas we want to focus the whole group on exploiting and elevating the immediate constraint.
- It considers the current position to be immutable, which is rarely the case; i.e. no (or negligible) variation in each workstation. The “subordinate everything else to the constraint” step also suggests that changes may be needed to the non-constraints, for example to ensure the constraint is never starved and always working at its optimum capacity.
- Wouldn’t it be good to base decisions on next steps upon real and current metrics, rather than something that was measured and then forecast months ago?
FURTHER CONSIDERATIONS
- [1] - https://en.wikipedia.org/wiki/Whac-A-Mole
- Control
- Unit-Level Efficiency Bias
- Manufacturing Purgatory
AGILE & WATERFALL METHODOLOGIES
In the heydays of early game development, it was common for a single engineer to do everything. They would come up with the game design, develop the code, test and bug fix, artwork, sound, print off the user manual, and then package it up for release (e.g. copy disks). This was possible because the games were (by modern standards) very small. However, as demand and expectation grew, we also found the software products growing (games today are many orders of magnitude larger than they were in the eighties). It became impractical for one person to do everything, and specialisms became the norm (Adam Smith).
Delivering a (software) product in today’s world is a highly complex, intricate, and involved process, involving many tools, specialisms, and roles and responsibilities, and therefore requires more structured, standardised and formalised project and delivery management techniques. For instance, we should consider the following:
- Coordination between different parties. How do we coordinate a set of distinct activities (some only actionable at certain stages in a project lifecycle), across a wide range of stakeholders (including third-parties), in a way that delivers the solution to customers in the most efficient manner?
- Requirements capture. How, when, from whom, and how regularly do we capture business requirements? How much will they evolve over time?
- Communication. How will a wide range of diverse stakeholders (customers, product owners, business analysts, developers, testers, project management, executives) successfully communicate? What mediums will they use? At what stage(s) and how often will they communicate? How will they articulate progress?
- Quality. What sort of internal or external quality measurements are you using, including when and how often are they employed? At what stage in the project lifecycle are bugs typically identified, and how (and how quickly) are they resolved? When (and how regularly) do you measure non-functional requirements?
- Are the implementation activities a series of small iterations, or one large release? This decision can affect a range of implementation decisions, including Branching Strategies and non-functional testing.
- Project management. Are you managing distinct phases or many increments? How does the choice affect delivery? How do you know how far through the project the team is?
- Delivering software. How and when is software delivered, and to whom? Are features delivered in a complete state, or delivered but disabled?
- Feedback. How and when do you receive feedback, and from which stakeholders? How might that feedback affect the product, during which stage in its lifetime, or how does it affect delivery timelines?
- Releases. How do you delineate and organise changes into something that’s sensible to both customer and business alike?
- What does the implementation team look like? Do they work in specialised (centralised) teams, or are they cross-functional?
To do all this, we need a delivery methodology. A (delivery) methodology encompasses many aspects and is a way of working, managing change, and measuring progress that aligns to all parties' needs. Of those, there are two common approaches:
- The Waterfall methodology.
- The Agile methodology.
Discussed next.
WATERFALL
Until fairly recently the waterfall model has been the de facto delivery model. In fact, it’s so deeply embedded within some businesses that any attempt to dethrone it is met with difficulties. At the most fundamental level, it’s a series of delineated activities that flow downward, like a series of waterfalls. We do a big chunk of this type of activity, followed by a big chunk of that activity, followed by a big chunk of another activity. See below.
Notice how the trend is almost exclusively downwards. There’s no attempt to revisit earlier stages, thereby creating an expectation that each previous stage is correct and of a good (quality) standard. Any slip up can have major consequences on downstream teams (therefore to the project) dependent upon the output being delivered in a timely fashion and being of sound quality.
Rightly or wrongly, our contemporary view of Waterfall is often one of derision (I’ll explain why shortly), yet it can be a good fit in some circumstances. For example, if the project is relatively small, it’s something you’re deeply familiar with (possibly because you’ve done it before), it has little in the way of unknowns (e.g. you’re using familiar technologies, tools, and patterns), neither you nor your customer’s goal or product vision changes over that timeframe (i.e. you’re building to a immutable specification), you can allocate staff at exactly the point in time they’re required, and the output of each stage is of a good standard, then it could be a good fit. Then again… can you think of many scenarios that meet this criteria?
SO, WHAT'S WRONG WITH WATERFALL?
To me, the main issues with Waterfall are:
- It's large-grained and sequential.
- It can create an immediacy bias (or date blindness), where the need to meet a date is placed ahead of other important factors, such as quality, agility, or sustainability.
- There’s a hand-off mentality that leads to a greater loss of Shared Context.
- It’s harder to reorganise and reallocate staff if issues are identified, thus we tend to batch changes.
- Larger releases are better at hiding quality issues.
- It doesn’t deal well with unknowns.
- It is (generally) more risky.
Let’s go through them.
IMMEDIACY BIAS / DATE BLINDNESS
“But surely a focus on dates is good? Without this, how can we satisfy customer demand in a timely manner?” Absolutely. Having a clear view of important dates is certainly a good thing, and helps to focus attention, but an overemphasis on dates - above all else - can also lead to an Immediacy Bias.
MILESTONES
To be clear, a waterfall project is defined by milestones - e.g. you must move from phase A to phase B by date C for the project to succeed. It's seen as definitive, easy to comprehend, and creates a sense (note the emphasis) of Control (particularly in upper management). It's rarely this simple, but if each phase meets its date, the project is on track, and everyone can remain calm.
This bias comes in two forms (date and project blindness). Fundamentally, the needs of delivering by a date, for a specific project, may be placed ahead of longer-term business agility or sustainability needs - quality is forsaken for the delivery date, which creates an increasing accrual of debts, thus making every subsequent delivery harder.
MANAGING WATERFALL PROJECTS
I see this problem again and again. Project managers and executives push so hard to meet the project delivery dates that they lose sight of the problems that can stem from such an approach. The problem is that they are accountable for (and judged by) the success of a project, not necessarily for the sustainable success of the business.
And who can blame them? Waterfall projects aren’t terribly nimble affairs. The impact of returning to an earlier phase can reflect badly on department heads (both the party responsible for the poor quality and the party requesting the rework), or staff are already reallocated onto other projects… so it becomes a game of politics and face-saving, rather than doing right by the business.
The second argument for immediacy bias is an easier sell, but not necessarily sensible. We’re trying to compare something definitive and relatively near-term (a project delivery date), against something that’s less tangible and longer-term (debts, and the sustainability of the business). Of course it’s going to lead to an Immediacy Bias.
HAND-OFF MENTALITY
Another concern with waterfall (or any coarse-grained model) is the hand-off mentality. Because work is segregated into large, distinct phases (or specialisms), we find that those specialists don’t gain access to the project until a large proportion of the work is already complete.
Often, there’s no significant (or regular) collaboration between the specialisms, except some minor interactions at inception or during a handover. This is where vital information is (meant to be) shared - thus creating a Shared Context.
Remember that a software product isn’t just the software (see What is Software?) - it’s the realisation of an idea, which has both a software aspect and the informational (or contextual) aspect. However, context has already been lost, between the time the feature was built to the time it is handed-over (Debt Accrues By Not Sharing Context).
So, instead of regular, timely collaboration and alignment sessions, context is shared through a raft of impersonal documentation, and potentially some high-level discussions (which typically involve pointing the recipients to the documentation), and it’s then left for that team to figure out the rest.
LOW REORGANISATION CAPABILITY LEADS TO BATCHING
The way a business organises itself, its culture, and even its politics, all play a part in how they work and function. In businesses that follow a more centralised (and specialised) form, we sometimes find (knowledge) silos - they are experts in their own domain but lose sight of other areas in terms of knowledge, experience, and (more importantly) empathy. Inevitably, this leads to difficult communication, the result of this being that we tend to do it less (humans tend to avoid difficult things, which exacerbates the problem at the point that they must be done). Those teams aren’t necessarily invested in what they’re asked to do because they’ve never really been involved in it.
Waterfall suits the siloed nature of teams in (some) organisations, as each lifecycle phase fits snugly into a centralised team’s responsibility (e.g. Architecture-and-Design hands off to Engineering, who hands off to Quality Acceptance). But it’s tough to organise and coordinate large groups of people, particularly when those people are of the same specialism and other projects are also vying for their attention. There may also be political considerations internal to that group to consider. Collectively, these difficulties lead to an inability (or unwillingness) to work at a finer grain, and thus the tendency to work with batches of change (in large releases), thus generating greater business risk.
SUCCESS IS MEASURED BY THE WHOLE
You only need one siloed team - awkwardly placed in the value stream - to force the batching of change.
I’ve seen teams working with modern technology and release practices unable to reap their rewards, simply because a downstream team was siloed, constrained by manual practices, and excluded from regular and meaningful interactions. Any strategy to increase the speed of technical delivery (for example to gain Fast Feedback) was hamstrung, both by the lower capacity of the downstream team, and the manner in which they completed their work, and drove the technology teams back towards a batch delivery model, thus creating business risk and competitive concerns.
LARGER RELEASES CAN BETTER HIDE QUALITY ISSUES
We already know that large releases are unwieldy and that waterfall leans towards the batching of changes, and thus larger-grained (big bang) releases (Lengthy Releases). When change is batched, problems are not encountered quickly enough to always do something about them, thus reducing business Agility.
INNOVATION + WAITING CARRIES RISK
Technology innovation typically carries risk due to the unknowns involved. This is exacerbated by lengthy waterfall practices. The longer the wait, the greater those unknowns become, affecting feedback and ultimately ROI.
But how does this relate to hiding quality issues? Well, it’s more of a “you can’t find a specific tree, from all of the other surrounding trees” scenario. A large batch requires us to process far more (physically and cognitively), to an extent that we may be unable to comprehensively process it.
Another concern we see with waterfall is the cultural, and emotional investment in each phase’s output. The bigger the investment (which may be effort rather than money), the more people are invested, and (due to vested interests) the less likely they are to stop investing, even if they know the project will fail (Loss Aversion). To rephrase - we may know of quality issues, but choose to ignore them.
LARGE-SCALE & SEQUENTIAL
As previously described, Waterfall is very sequential and forward-oriented. This in itself isn’t necessarily a problem, but when combined with coarse-grained (batched) deliveries, it can create significant disruption, should there be a need to return to a previous stage. To analogise, it's a bit like a snowball rolling down a hill. It gets larger and faster the further it travels, making it increasingly difficult to stop. The effort to stop it and the ramifications of doing so (e.g. the knock-on effect) become so serious, that bias (including political) and Loss Aversion can usurp other important considerations (like the impact on customers).
SEQUENTIAL NATURE + GRANULARITY
It’s not really the sequential nature of Waterfall that makes it difficult to return to an earlier phase - it’s the sequential nature combined with its coarse granularity.
The Agile methodology is also sequential (we undertake UX, technical design, implementation, testing, and deployments in a specific order). However, we’re working at a much finer granularity of change that enhances flexibility (such as returning to an earlier phase) and reduces risk.
GREATER RISK
My previous arguments point mainly to an increased (and in many cases, unnecessary) risk. Whilst the risk isn’t all-encompassing - waterfall can be very successful, assuming that all of the stars align (there are few surprises) - I see its use as a broader risk to how businesses successfully deliver value and sustainability.
From my experience, waterfall tends to focus groups on projects - finishing the project becomes the goal, rather than finishing it in a way that is sustainable to the business.
AGILE
The Agile methodology spawned from a general discord with the results of Waterfall, and has already been discussed. Like Waterfall, Agile is a project management and delivery methodology.
Primarily, Agile attempts to address the risk associated with software delivery (and with using waterfall). As we know, Waterfall projects tend to be more risky affairs that don't always align well (or quickly enough) with customer needs.
The Agile Manifesto states:
“We are uncovering better ways of developing software by doing it and helping others do it. Through this work we have come to value:
That is, while there is value in the items on the right, we value the items on the left more.” [1]
Agile differs from Waterfall in the following areas:
- It places greater emphasis on interactions and collaboration to create better software.
- It limits the scope of each change, to reduce risk and gain Fast Feedback.
- It supports the ability to (pragmatically) return to earlier phases.
- In general, it creates a greater level of Agility (I guess the name may have given it away).
Let’s talk through them.
FOCUS ON INTERACTIONS & COLLABORATION
One of Waterfall’s biggest failings is that it tends to produce (or support the extension of existing) silos. Agile confronts this by emphasising relationships, through more interactions and greater collaboration.
This may sound irrelevant, but the way in which we interact with others (and its regularity) can strongly influence the outcome. I’ve already talked about how techniques like Pairing and Mobbing (Indy, Pairing & Mobbing) can create better quality software and build up an important Shared Context. But building strong relationships also allows us to ask deeper questions and obtain better answers from a more diverse group.
Greater diversity has other benefits too - it counters bias, and less bias equates to fewer assumptions, which leads to reduced risk. It also reduces risk in other ways. A wider range of diverse stakeholders can typically identify problems much earlier, react sooner, make better decisions, and thus enable alternative approaches to be tried. You can’t do this when time is working against you - the decision is made for you.
A greater focus on interactions has also led to an increase in Shift Left activities - activities that not only increase collaboration, but often support improvements to TTM, ROI, and Agility. We may never have had activities like Story Mapping, BDD, TDD, or DevOps without the mantra behind Agile.
THE SCALE OF CHANGE
I’ve already described how the waterfall model, and the team structures it promotes, tends to advance the idea of irregular batching of change; thus creating unnecessary risk. Conversely, Agile prefers the regular release of small amounts of change that:
- Aid learning and feedback (Fast Feedback). You get valuable information sooner, and that allows you to adapt and change direction.
- Create a better alignment with what’s actually needed (i.e. we work on the right thing). The greater the distance you are from your customer (that’s also in the temporal sense), the less accurate (greater Assumptions) you are about what they deem important.
- We may also generate better ROI by (a) getting some return on what we deliver, even if it’s just from a system’s integrability perspective, and (b) ensuring we don’t overprocess or overproduce (The Seven Wastes).
- Reduce risk.
RERUNNING PHASES
The two key reasons why waterfall struggles to rerun phases are (from a pragmatic perspective):
- The scale of each change (bulk), and therefore its impact on teams/departments (Lengthy Releases).
- The implicit promotion of siloing within organisations.
Agile is in stark contrast on these two points. I’ve already mentioned that Agile prefers small deliveries of incremental value. Also, from an organisational perspective, it tends to favour dedicated Cross-Functional Teams - responsible for building, delivering, and operating features. This creates a nimbleness (or agility, if you prefer) at both the team level and in terms of the scale of change, which consequently makes it much easier to return to an earlier phase. The second-order consequence is the ability to build in quality at a much earlier stage (Shift Left).
BUT IT’S NOT PERFECT
Agile isn’t perfect, but what is? Voltaire would say that “the perfect is the enemy of the good”.
Earlier, I lamented that waterfall sometimes focuses groups on the success of projects, rather than the sustainable success of a business. Agile, though, can focus groups at too low a level - they solve the immediate concern, but lose sight of the big picture, resulting in a lot of team alignment sessions.
ALIGNMENT TECHNIQUES
The good news is that there are plenty of techniques (such as Story Mapping, and BDD) to help teams to align to the big picture.
The other aspect I hear some agile purists vocalise relates to any sequential (and potentially lengthy) activity that doesn’t necessarily fit well into an iterative model. I’m thinking of activities like solutions architecture or alignment sessions - they may not “fit” directly into such an incremental (agile) delivery, but that doesn’t discount their value.
AGILE & LESS ITERATIVE ACTIVITIES
Beware of others who would prefer to discount important project (or product) activities, simply because they don’t fit well into an incremental delivery (e.g. Agile & Less Iterative Activities).
To me, agility is also about having the flexibility to choose the right approach for your project/organisation. Therefore, we should employ any aspect of project (or product) delivery that is sensible, and not neglect them simply because they don’t fit well with an incremental bias.
WAGILE
Before finishing this section, I’d like to summarise a third way - which I (somewhat mischievously) call Wagile (Waterfall-Agile).
Let me first defend myself by stating that Wagile isn’t a formally defined methodology; neither is it something that most businesses would actively set out to achieve. I record it here for the sake of completeness.
Wagile is a term I use to describe businesses who are stuck in perdition, somewhere between the Waterfall and Agile methodologies. It's typically found in established organisations that are already familiar with waterfall methods, are now wishing to adopt Agile, but are unable to extirpate all of waterfall’s lingering hallmarks - like a firm and unwavering “date orientation”, incremental changes but batched releases (e.g. teams provide change fortnightly, but these are simply grouped into a large quarterly release the business and customers are already attuned to), or skill-delineated (silod) phases (e.g. “we do a full regression test of our release in this phase”).
EXAMPLE
“We don't do waterfall, we do Agile,” claimed the CTO.
“Really?” I thought, “so what are all these quality issues - causing you to spend an additional month (of our money) fixing at the end of the project? And it’s still not been released to customers…”
The morale of the story? If you’re not embedding quality into each and every iteration, you’re still doing a form of waterfall.
Wagile can be very difficult to extract yourself from. In many ways it's an improvement on Waterfall, but it’s still lacking some of Agile’s key qualities to mitigate risk and improve decision-making.
SUMMARY
Waterfall and Agile (and even Wagile) are delivery methodologies - i.e. they are different ways of delivering projects.
Waterfall is a series of delineated activities that flow downward, like a series of waterfalls. It can be effective if: the project is relatively small, is a known quantity (possibly because you’ve done it before), and neither you nor your customer’s goal or product vision changes over that timeframe (no scope creep). However, it tends to favour bulk change and organisational silos, reducing collaboration and feedback, and therefore increasing risk.
Conversely, Agile is a lighter-weight iterative methodology, well suited to managing (constant) change and unknowns. It focuses more on interactions, feedback, and iterative change, and is a useful tool to manage risk.
To analogise, consider how TV and film studios (typically) manage risk. Although it's not unheard of, you rarely hear of studios filming/producing a film trilogy contiguously (equivalent of Waterfall), simply because of the high risk associated with it. Studio executives won’t waste money creating content that the public won’t consume. They need to find alternative ways to gauge the likely success of a film or show with its audience, prior to making a significant investment, and typically counter financial risk by releasing trailers, pilot episodes, ad-hoc episodes, or only initially committing to a single season. This most closely resonates with Agile - we test our assumptions, by quickly releasing something to our customers, and then assess what to do from there.
FURTHER CONSIDERATIONS
- [1] - The Agile Manifesto - https://www.agilealliance.org/agile101/the-agile-manifesto/
- Assumptions
- Shared Context
- BDD
- Branching Strategies
- Agile & Less Iterative Activities
- Shift Left
- Cross-Functional Teams
- Lengthy Releases
- The Seven Wastes
- Fast Feedback
- TDD
- Indy, Pairing & Mobbing
- Loss Aversion
- Debt Accrues By Not Sharing Context
- What is Software?
- Control
AGILE & LESS ITERATIVE ACTIVITIES
The main thrust of Agile - as an iterative delivery methodology - is that by reducing the scope of each cycle of work down to a small chunk (typically ranging from a few days to a few weeks), you benefit from lowered risk, increased feedback, and increased agility (see Agile & Waterfall).
This is excellent in theory, but in practice a typical software project consists of many different activities - including UI/UX, product management, vision and inception (alignment) sessions, and architecture - not all of which can be (sensibly) achieved using iterative practices.
I’ve heard some suggest that these (non-iterative) practices are un-agile, and therefore take the astonishing leap that they therefore have no value, nor place, in the lifecycle of a modern software product.
The most common example I’ve heard is that: “Now that we’re doing Agile, we don’t need architecture, or an architect.” i.e. “We can do quite well without you, thank you very much.” And you know, quite often, they do. At least in the beginning…
SOLUTIONS ARCHITECTURE IN WATERFALL
This view isn’t necessarily helped by past experiences. In the wrong hands - and embedded within a unidirectional, waterfall-oriented delivery - the outcome of a solution’s architecture can be sketchy at best. I’m thinking of those theoretical architectures that are passed down to others to implement something that can never be realised.
It happens, but it’s not exclusively true, and certainly doesn’t make the activity valueless, whether in Waterfall or Agile.
Just because value can’t be seen, or contextualised, nor the effects easily measurable should such an activity be precluded, doesn’t make said activity devoid of value. This is true of many things, including architecture. Of course I would say that, but I’ve seen too many projects, products, and applications go astray - not in the immediate present, but half a decade later - when all of the decisions that were made independently of any joined-up thinking or vision, return to haunt the business.
It might help if we consider the purpose of solutions architecture. Would we create a new city, a film, or a product, without first considering its composition, how we link its constituent parts together, or the ramifications of one set of techniques or materials over another? Of course not. A city builder, film director, music composer, product owner, and architect provide a vision that binds distinct components into something cohesive and (hopefully) desirable.
Solutions architecture for instance allows us to comprehend as much of the whole (as is sensible), ensuring that we’re not just building in isolated silos; e.g. isolated solutions that don’t “fit”, integrate, add unnecessary complexity, or create longer-term sustainability challenges (e.g. no uniformity). Yet there are still aspects that can be embedded into an iterative model. We may define a holistic view, verify it with spikes, but be prepared to change that view and realign as more information arrives.
PREFER, BUT DON'T NEGLECT
The Agile Manifesto [1] states that we should prefer certain activities over others (e.g. individuals and interactions over processes and tools). It doesn’t suggest that we neglect, or ignore, these activities if they don’t fit easily into an iterative model.
This isn’t the only example. Agile teams already use up-front inception techniques with Story Mapping, where we try to tease out a narrative, features, interactions, and ideas to get a more holistic view, create a shared context, and build alignment. Likewise, you can’t define a UI/UX without understanding something about the whole. And what about product management? Wouldn’t you be sceptical of any product manager who only considered the next step, and didn’t also take the big picture into account? I certainly would.
(Solutions) Architecture, Story Mapping, UI/UX, and Product Management all influence the vision - they don’t fit directly into an iterative model (i.e. why some may view them as un-agile), but they’re all important.
FURTHER CONSIDERATIONS
- [1] - The Agile Manifesto - https://www.agilealliance.org/agile101/the-agile-manifesto/
- Agile & Waterfall Methodologies
DUPLICATION
Software Engineering is a complex business. Many aspects - if not carefully considered or controlled - can cause significant business-scale problems over time. One of which is duplication.
Duplication can take many forms; the most common being:
- Functional duplication. A behaviour is duplicated within another context to satisfy another need, thereby creating multiple solutions to essentially the same problem.
- Data duplication. We copy data (or information) from one place to another, to satisfy another need.
But this doesn’t explain the potential dangers of duplication. Let's start with functional duplication, shall we?
It’s common for established businesses to manage multiple software products offering the same (or very similar) functionality. In some cases, the problem is so acute that there may be tens of applications offering the same thing. This can occur for many reasons, including: lack of awareness (“we didn’t know it already existed so we built our own one”), political (“we don’t want their department dictating what we do”), necessity (“the existing solution doesn’t meet our modern needs”), or mergers and acquisitions. In this context it matters not why it occurs, simply that it does.
GROWTH THROUGH ACQUISITION
Businesses that follow the Economies of Scale and Growth Through Acquisition model (mergers and acquisitions) can find themselves with this problem unless they actively pursue a consolidation model.
Doesn’t sound like a problem (Why Consolidate)? The business is now managing the same function, in different technologies, on different platforms, requiring different skill sets, for essentially the same behaviour. This is massive (unnecessary) complexity.
POOR ROI CAUSED BY DUPLICATION
Now consider that we must implement a governmental directive (e.g. GDPR) - affecting each duplicated function - in order to prevent significant financial penalties.
In the zero-duplication model our task would be relatively small, with minimal waste. However, in a business with functional duplication, we suffer massive waste (it's a multiple, based upon the number of duplicates you have, across the entire portfolio). Talk about poor ROI.
BRANCHING TO CREATE BESPOKE PRODUCTS
Some businesses use a branching strategy to create bespoke client solutions (each branch began as a generic solution but was branched to deliver bespoke client behaviours). This is essentially functional duplication. It may be the same product, but the branch creates a distinction, and you’re therefore at the whims of functional duplication.
Data duplication can also create problems - as anyone familiar with the Resilience through Data Duplication model can likely attest to. Data may be duplicated into other systems, teams, departments, and businesses for various reasons, typically using an ETL (Extract Transform Load) mechanism. Whilst certainly a well-trodden path, the quality of the output (data integrity) depends upon many factors, including platform reliability, temporal factors, and the accuracy of the implementation (which may vary after each release). Consequently, it’s common for the duplicated datasets to be poorer equivalents of the original, with missing, stale (it was once accurate, but no longer so), or inconsistent data.
The impact of such an inaccuracy depends upon: the scale of the inaccuracy, reliance upon those datasets (is it heavily used or only by a small group of users?), how swiftly it can be identified and then remedied, and the importance of the data (e.g. is the data used for critical healthcare decisions?). Such an inaccuracy is likely to affect at least one of:
- Usability - e.g. missing or incorrect data makes it impossible to navigate the system.
- The CIA Security Triad - data confidentiality, availability, and integrity may be impacted.
- Reputation - an inconsistent or patchy dataset (particularly if they are important) can have a reputational impact on the business.
RELEASE (VERSIONING) INFLUENCE
As I previously stated, the quality of the output (data) is affected by the quality of the solution responsible for moving and transforming that data. See below.
Note how versions V1 and V2 both output data of the same shape. This suggests that the new release (V2) leaves the output in a consistent, expected state (assuming that the V1 state was already accurate). Version V3, though, creates a differently shaped output, which (in our scenario) is both unexpected, and unwanted.
The point of this exercise is to show that not only can a system change the output, but also each version of that system, and why regression testing (Regression Testing) is critical. Any solution that either does the wrong thing (such as by misinterpreting a business requirement, or creating a bug), or behaves in an unexpected manner (such as an availability problem), can affect the quality of the data.
AVAILABILITY INFLUENCE
In the previous section I described how a functional behaviour (whether intentional or not) can affect the outcome. In this section I briefly describe how a non-functional characteristic (availability) can also affect it.
Consider a system consisting of three steps, that takes data (records A, B, and C) from one system, transforms and filters it (the three steps), and then stores the output in another location for consumers to access. See below.
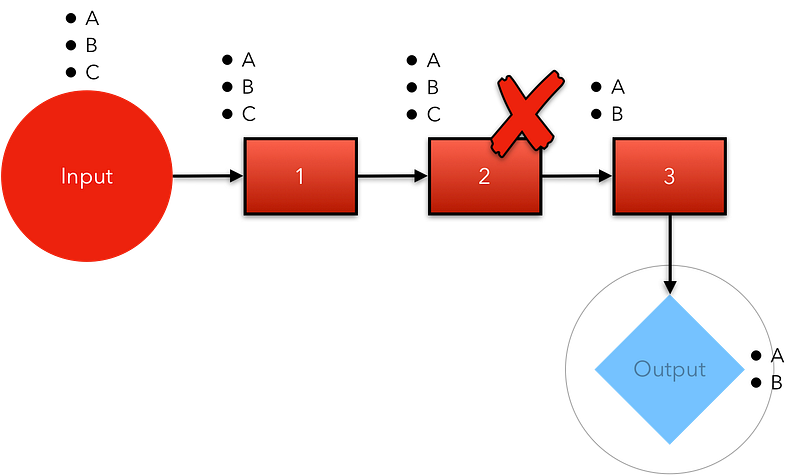
Let’s assume that datasets A and B are successfully processed and the output is stored. Dataset C now enters the system. Whilst step 1 is successful, an unexpected system failure occurs at step 2. Dataset C is discarded, never reaching the end system (note it is only aware of records A and B). We now have a discrepancy between the number of records in the master dataset and that in the downstream secondary.
SYSTEM RELIABILITY
Unless the system moving the data is as accurate and reliable as the system that initially captured that data, then there will always be some loss - either in quantity, or in quality. This affects the consumers of those datasets, and thus overall Stakeholder Confidence.
SUMMARY
I first entitled this section: “The Curse of Duplication”, but the more I thought about it, the more I realised that duplication in software engineering isn’t always a curse. In fact, it’s sometimes advantageous.
Microservices are a case in point. True microservices are fiercely independent. They make few assumptions (Assumptions). To achieve this, they must limit any external influence that can affect its independence. As such, a common microservice pattern is to duplicate behaviour in multiple microservices, rather than make use of a shared external library that may impact its lifecycle. Admittedly, whilst I understand the reasoning, I’m not quite sold on the practice.
Additionally, were we to consider Streaming technologies (such as Apache Kafka [1]), we’d find the use (nay, the advocation) of data duplication (Event Sourcing). It’s advantageous as it allows teams to work more independently and even add new consumers to existing data points. And whilst it can't fully resolve every difficulty around the data duplication model, it’s exciting because these new platforms offer a highly reliable and scalable platform, with near real-time synchronicity.
FURTHER CONSIDERATIONS
- [1] - Apache Kafka - https://kafka.apache.org
- [2] - CIA Security Triad - https://www.bmc.com/blogs/cia-security-triad/
- Assumptions
- Streaming
- Legacy Systems
- Microservices
- Resilience through Data Duplication
- Stakeholder Confidence
- Why Consolidate?
- Economies of Scale
- Growth Through Acquisition
- Regression Testing
- Growth without Consolidation
RELIABILITY THROUGH DATA DUPLICATION
I've encountered this approach a number of times. In an attempt to gain system reliability (resilience and availability), data is duplicated into another system, or area, for consumption; either to protect, or to circumvent problems, in the original system. See below.

WHY DUPLICATE DATA?
You may use this approach to create read-only data sets, data subsets for specific user demographics, or to filter it in some other way appropriate to the consumer.
This approach suggests that by creating an independent system to cater to a specific user group, and copying/transforming datasets into it from the original, it should promote greater reliability (mainly by limiting access to a subset of users, or by having more rigid SLAs in the new system).
Whilst this argument holds water, it has a very narrow focus, and other ramifications. Firstly, it is heavily influenced by the quality of the replication mechanism. One that contains bugs, partially meets the business needs, or isn’t available when needed, is unreliable, and therefore may create more problems than it solves.
DATA QUALITY FACTORS
The quality (integrity) of the data is dependent upon many factors, including platform reliability, temporal factors, and the accuracy of the implementation.
Secondly, and paradoxically, by neglecting to consider the whole (system thinking), we’re divorced from a potential joined-up response to the root cause problem (“I solve my problem, you solve yours - we don’t help one another”), meaning that the original system (and its dataset) remains less reliable than it probably should be.
CONTROL
There’s also a question of Control. Some teams take issue if they’re not in complete control of their own solution, so will find ways to gain that control for their own sake, and not necessarily for the benefit of the entire enterprise.
THE ARGUMENT
Ava is the original system owner, Sam the secondary system owner.
“Hi Sam, it’s Ava. Hope you had a nice break. I was speaking with some of your team members whilst you were off. They showed me some of the technical diagrams on your new system and I’m trying to understand why you chose to copy data out from our system, rather than using our master record?”
“Hi Ava. Well, when we looked at it, we were concerned that it wasn’t sufficiently reliable for our needs. We decided it was safer to duplicate the data to meet our customer’s needs, and thus create a better user experience.”
“Oh, ok,” says Ava, rather put out, “so you think our system isn’t reliable?”
“Err, sorry, but yes. I’ve heard of a few incidents…”
“You mean the thing that happened last year? Yes, that was rather unfortunate.” A brief pause. “But you solved it by doing a nightly replica. And, from what you’re saying, it leaves our solution in no better position. It's still - as you point out - not as reliable as we, nor our business, needs it to be. It’s circumventing the real problem. I feel if we’d talked this through sooner, we could have pooled our resources, and then achieved both. We could have offered you what you need and improved our own system. That would have been a win for all parties.”
DATA CHAINING
I’ve seen the following type of approach used as a data chaining model to create many distributed systems for different needs.

Data is copied from A and B into C, a subset of which is then copied from C and moved into D, before another subset of data is copied from D into E.
Remember my point about the quality of the systems responsible for transforming and moving the data? If it’s inferior to the original capturing system, then there’s a data degradation occurring after each hop, creating data entropy. That’s an issue with a single hop, so consider this approach with a chain of such systems, as shown above. It can’t get any better (the input isn’t really changing), and it’s unrealistic to think the data transfer mechanism is in every way and at every point in time an equal to the original capture means, so it can only really go in one direction.
SUMMARY
This approach can (and does) work. However, it can also create unnecessary complexity, and may not yield a good, holistic outcome - the resolution of an underlying problem for the entire business. Before using it, I’d first recommend that you understand why such an option is being considered? Is it an attempt to bring reliability, or scalability, to a solution lacking those qualities? And if so, why doesn’t the existing system already exhibit those desired traits, and is there a sensible way to support them, without duplicating datasets?
FURTHER CONSIDERATIONS
WASTE MANAGEMENT & TRANSFERRAL
To my mind, the best way to reduce waste is simple - don’t undertake tasks of little, or no value. Of course the problem with this is that reality sometimes gets in the way.
I've repeatedly stated throughout this book that success in feature development is often a form of betting. In any form of product development (including software), it’s difficult to determine the features which will be valuable and succeed [1], and those which won’t, without building something and showing it to customers.
So, if we can't (necessarily) prevent unsuccessful features from being released (an idealistic state), surely the next best thing is to swiftly release change to customers, doing no more than necessary (no Gold Plating), gain instantaneous feedback, and then pivot work based on this? If a feature is a flop, we rip it out (an important step in managing long-term complexity), and then reassign the team onto the next idea. Waste reduction in this case is achieved by increasing flow to our customers, and making better choices based upon Fast Feedback.
THE TRANSFERAL OF WASTE
Something I see regularly within engineering teams is a haste to remove waste. This is admirable, but it’s also important to understand that waste - like energy - may be transferred from one form into another. Consequently, and paradoxically, teams undertaking waste reduction activities may not be supporting the overarching business goal.
Most commonly I see individuals and teams promoting internal efficiency improvements, whilst remaining ignorant to its effect on the overall “system”. The displacement of the Waiting waste for the Inventory waste - where we speed up our own area, only to flood the constraint (Theory of Constraints) in another area - being a particular concern.
I’ve also seen engineers attempt to counter the Waiting waste with the Overprocessing waste - i.e. whilst they wait for others to complete a dependent task, they keep themselves busy by enhancing (Gold Plating) the current solution with unnecessary refactoring, testing, performance improvements, and documentation activities. The solution may be significantly enhanced, but it was unnecessary, the customer isn’t paying for it, and we’ve now stacked an additional waste (Overprocessing) upon the existing (Waiting) waste.
FURTHER CONSIDERATIONS
- [1] - A feature can be valuable without being successful. Consider all of those great ideas that customers like, but there simply isn't a big enough market for them to be a success.
- Fast Feedback
- Gold Plating
- The Seven Wastes
- Theory of Constraints
BEHAVIOUR-DRIVEN DEVELOPMENT (BDD)
The primary intent of this book is to bring business and technology closer together. Behaviour-Driven Development (BDD) offers one way to do this.
Throughout this book, I’ve expounded the challenges of software engineering. Those challenges - however - don’t always lie with the implementation, but in bringing together all of the various stakeholders (e.g. customers, developers, product owners, testers) to understand, comprehend, align, and then build the right solution.
In the past, we’ve attempted to deliver software using a mix of highly specialised and delineated responsibilities, phased deliveries, and stages interspersed with work queues (i.e. Waterfall). Customers engaged with Business Analysts (BAs), who wrote lengthy tomes of business requirements, that were then articulated into solutions by architects and designers, before being broken down into implementation phases that finally saw developers and testers involved. This approach led to waiting, the loss of Shared Context, the risk of building the wrong thing, and rework (The Seven Wastes).
Since then, there's been a steadfast countering of such disjointed practices through Shift Left activities, such as in automated testing, TDD, Pairing & Mobbing, and DevSecOps. The one common theme they share is that they all promote greater and earlier collaboration.
BDD is another means of supporting the shift left. Rather than the customer (or their proxy) engaging solely with a business analyst, we actively encourage technical (designers, developers, and testers) and business stakeholders to engage and collaborate with customers, both to create a shared context, and to use diversity to identify better solutions, risks, or unknowns. Additionally, rather than constructing lengthy business requirements documents (that take weeks or months to write and are quickly outdated), we take a more Agile (iterative) view, having lots of short, focused, just-in-time (JIT Communication) discussions instead.
So what is BDD? BDD is often misperceived as a form of testing, or as an alternative to TDD. Neither is accurate. It's a way to support collaboration and alignment (e.g. Shared Context) in the building of software, using scenarios to understand context, the output of which has secondary benefits, both in the form of a common language and in the support of automated testing (Acceptance Testing).
EXAMPLE MAPPING
BDD is commonly practiced using a technique called Example Mapping. In this approach a (cross-functional) group collaboratively discusses the next user story (ideally just-in-time), using coloured cards to capture the story, its rules, outstanding questions, and (importantly) examples. This discussion helps us to discover different scenarios and considerations, and is critical to understanding - and thus solving - the problem. See below.
PURPOSE
The idea is to collaboratively map out the feature in sufficient detail that all of the stakeholders understand it, and have sufficient detail to complete it (implement, test, and deliver it). It need not be exhaustive, but it should be a good indicator of how ready you are to begin work.
Example Mapping shouldn’t be viewed as a lazy way to determine requirements; or a vision for that matter. There should still be some groundwork done up-front - typically by the product owner - to understand the vision, scope, and give a general sense of what’s expected. This ensures the team isn’t asking fundamental questions during the shaping session, which is about gaining sufficient clarity to build a solution.
FURTHER CONSIDERATIONS
- Acceptance Testing
- Agile
- BDD Outcomes - Common Language Testing
- Example Mapping
- JIT Communication
- Pairing & Mobbing
- The Seven Wastes
- Shared Context
- Shift Left
- TDD
- Waterfall
BDD BENEFITS - COMMON LANGUAGE
As previously mentioned, BDD is not a form of testing. It's a way of aligning different stakeholders around a common problem in order to better understand, and thus solve, it. However, BDD also produces useful outputs in the form of:
- A common (shared) language (also related to Living Documentation).
- A means to form test automation from the common language.
The common language can take any form, but a common one is Gherkin's [1] Given, When, Then syntax:
- Given - set up the context; i.e. set the scene.
- When - the action(s) being undertaken.
- Then - the outcome that should occur.
Let's look at an example shall we? Assume that Mass Synergy is building a new discounting feature for their customers. Our first feature might be to offer domestic customers (let's say US for the sake of argument) a percentage discount if their purchase exceeds $50 and 5 items (yes, it's slightly arbitrary). Using the Gherkin syntax, we identify the following scenarios.
Feature: Derive Discount
Derives a discount applicable to the supplied cart and customer combination.
Scenario: David lives in country and meets purchase criteria to receive percent discount
Given David is a Mass Synergy member
And resides in USA
When he places the following order:
| Item | Quantity |
| lordOfSea | 1 |
| danceMania | 1 |
| lostInTheMountains | 1 |
| balancingAct | 1 |
| mrMrMr | 1 |
Then he receives a 10% discount
Scenario: David lives in country but fails to meet purchase criteria, he receives no discount
Given David is a Mass Synergy member
And resides in USA
When he places the following order:
| Item | Quantity |
| lordOfSea | 1 |
| danceMania | 1 |
Then he receives no discount
This feature file encapsulates our requirements. It needs a bit of work, but so far we've defined two scenarios - one where the customer receives the discount, and one where they don't. It's readable by all (Shared Context), unambiguous, uses personas (e.g. “David”) to help contextualize (and empathize), and (critically) can be used as a foundation for automated testing.
OTHER SCENARIOS
I've intentionally shown you a very simplistic, and incomplete set of discounting scenarios. We've shown one happy-path scenario, and one where the customer fails to meet the criteria, but there's lots more scenarios to consider. For example, can our customer (David) get a discount if he purchases five of the same item? What about if David is traveling to the UK, should he receive that discount whilst in London? What about customer churn? Should we encourage customers who've recently left with an incentive to rejoin? What about offering an alternative form of discount? Should a customer who spends $100 get a larger discount?
In a BDD session I'd expect the team to identify many other scenarios, and capture them in cards.
The above feature file example is not an automated test suite. We've still got work to do. To do this, we must map the common language to a technical implementation (the tests), using a “gluing framework” to link them together. Here's one such example (implemented in Java and using Cucumber).
public class StepDefinition {
private DiscountEntitlement discountEntitlement;
private Customer david;
// assume this has already been set up with items
private Map catalogueItems = new HashMap<>();
@Given("David is a Mass Synergy member")
public void david_is_a_mass_synergy_member() {
david = new Customer("34567", "EH9 5QT");
}
@Given("resides in USA")
public void resides_in_usa() {
david.setPostCode("90210");
}
@When("he places the following order:")
public void he_places_the_following_order(DataTable dataTable) throws IOException {
Cart cart = new Cart(UUID.randomUUID().toString());
// add all of the items to the cart, using the id to lookup map key
dataTable.cells().stream().skip(1)
.map(fields -> {
Item item = catalogueItems.get(fields.get(0));
return item.setQuantity(Integer.valueOf(fields.get(1)));
})
.forEach(cart::addItem);
Entitlement entitlement = new Entitlement(david, cart);
HttpRequest request = …; // set up the request
... now call the discounts service to get the entitlement
HttpResponse response = httpClient.execute(request);
discountEntitlement = mapper.readValue(convertResponseToString(response), ...);
}
@Then("he receives a {int}% discount")
public void he_receives_a_discount_and_cart_total_is_reduced_by(Integer discountAmount) {
assertTrue(discountAmount == discountEntitlement.getAmount());
assertEquals("PERCENTAGE", discountEntitlement.getType());
}
@Then("he receives no discount")
public void he_receives_no_discount() {
assertTrue(0 == discountEntitlement.getAmount());
assertEquals("NONE", discountEntitlement.getType());
}
}
A word of warning. This code won't compile - I've simplified it for brevity's sake. Note the method annotations starting with @ (e.g. @Given, @When, and @Then)? This mechanism allows the framework (Cucumber [2], in this case) to map the feature definition to specific implementations (methods), thus allowing us to link test automation to the common language Gherkin DSL.
This concept of taking the requirements (in the feature file) and running them through a test automation suite - without any extraneous (unnecessary) documentation - is powerful indeed.
FURTHER CONSIDERATIONS
- [1] - Gherkin - https://en.wikipedia.org/wiki/Cucumber_(software)
- [2] - Cucumber framework - https://en.wikipedia.org/wiki/Cucumber_(software)
- Shared Context
- BDD
SINGLE POINT OF FAILURE
As the name suggests, a Single Point of Failure is a point within a system (in a purely abstract sense, not a technological one) which is singular, and therefore vulnerable to failure (or throttling/slowdown). Understanding Single Points of Failure is important because they represent weaknesses in a system, or practices, and can quickly lead to an avalanche of failures elsewhere.
I commonly encounter two forms of single-point-of-failure:
- Within a (software) system - such as only running a single instance of a microservice.
- Within an individual or team - such as Knowledge Silos.
Let's look at them now.
SYSTEM SINGLE-POINT-OF-FAILURES
In a software system, a single-point-of-failure can directly, and significantly, affect Availability, and therefore your Reputation. It typically occurs when false assumptions (Assumptions) are made about a system, and remain unresolved, eventually causing the system to fail.
A FAILURE? WHERE?
System failures occur for many reasons - including hardware, networking, operating system, application, power, or geographic failures.
Therefore, highly available and resilient systems typically require duplicates of every system component to negate the possibility of a single-point-of-failure. This sounds straightforward in theory, but less so in practice. Any component - given enough time or neglect - will fail, and the complexity of modern systems hampers the discovery of single-points-of-failure.
The Cloud vendors have done an excellent job here. Sure, there's the occasional wobble, but overall they've built the physical sites (e.g. regions and availability zones), infrastructure (e.g. direct network connections, load balancers, and IaC), services (e.g. distributed NoSQL databases), and platforms (e.g. multiple instances deployed across CaaS and Serverless platforms) to significantly reduce the likelihood of a single-point-of-failure. Why would we think we could do a better job?
Examples of single-points-of-failure include:
- A single location. A single geographic location can also be a single-point-of-failure, should there be a major incident (e.g. an “act of god”). Thus, storing all of your software on servers in a single geographic location (a data center) creates such a scenario. Cloud vendors solved this by supporting regions and availability zones.
- A single server/instance. Should that server fail, how difficult is it to replicate it to another? Clustering, or replication, can be used. Not only does this reduce the effect of server failure; it also provides performance and scalability benefits through shared resource usage.
- A single database. It's quite common to run relational databases on a single instance, and scale using the vertical scaling model (Scalability). This raises the same problems as a single server - if it fails, everything that depends on it (most things, if it's a database) fails. The fierce independence model of microservices - where each service gets its own database instance - can help here.
- A network. Networks are unreliable - packets may never reach their destination, may be malformed, or may be received out of sequence. A heavy dependence upon an unreliable (or overworked) network connection can stop a system from functioning (or adversely affect Availability, by reducing throughput). We can do something to alleviate this issue. For instance, most Cloud vendors also offer more reliable network options to directly connect your enterprise to the cloud's services through an intermediate. Asynchronous processing can also help here. By minimising the time software waits for a response, the fewer long-running connections are needed, and thus, the reduction in broken connections.
- A single component or service. If other system components rely upon a single component that fails (such as due to a reliability issue), then it may render all reliant components useless. A common solution to this problem is to spawn multiple instances of the component (preferably across multiple servers), and use load-balancing to distribute load to them.
- Third-party software. A heavy reliance upon a third-party can also become a burden if they are unreliable, or vulnerable. SLA's exist for this reason, forming an incentive to ensure third-parties take responsibility for their service's availability.
- Power supply failures. Systems that depend upon a continuous supply of power may assume that power is always available; which is not necessarily the case. An Uninterruptible Power Supply (UPS) is one solution – providing power (for a short period) to allow a generator to be started.
- A new deployment may also fail. Arguably, the Blue/Green Deployment approach is a remedy for a single-point-of-failure, allowing us to revert to an older, more stable version if required.
You can see that a lot of things can go wrong, making the Cloud a very appealing prospect.
ORGANISATIONAL SINGLE-POINTS-OF-FAILURE
MY TAKE
Organisational single-points-of-failure represent the habitual use of experts (Knowledge Silos) working within a silo to complete work and promote efficiency.
People, or teams, can also be single-points-of-failure - sometimes known as Knowledge Silos. Someone with vast system or domain experience and knowledge - commonly referred to as a Domain Expert - is an extremely valuable (company) asset, and could be a potentially disastrous loss if they leave, or are unable to work. Rightly or wrongly, intentionally or otherwise, these entities (individual or team) have a level of Control over your business, creating a dangerous situation where delivery is impeded, the tempo is set by, or decisions are dictated by that single-point-of-failure.
EMPIRE-BUILDING & CULTURAL IMPACT
The cultural impact of a single-point-of-failure is not something to be quickly dismissed. I've seen it enough times to be wary of it, and may include a loss of professionalism on an individual's part, and cultural challenges.
It can also be treated as a form of empire building. Unfortunately, as some people become aware of their superior knowledge over others (on a particular subject), they realise they have a certain degree of power over them, and - if so inclined - can bend decisions to their desire. A minority use this power to do what's best for them, or their team, rather than what's in the best interests of the business. Given sufficient time and exposure, this forms an almost impenetrable culture - something very difficult to shake - in any established business.
Quite simply, no one entity (be it an individual or a team) should know everything about a system; knowledge should be shared.
To me, the “domain experts” concept can quickly transition from asset to anti-pattern. Of course some level of expertise is unavoidable, and certainly not a bad thing. However, if you find yourself in a situation where only a single person knows how a system or process functions, I'd recommend asking why this is? Is it because the system is too complex for outsiders to understand, and therefore only the person who created it can understand it? This could be an architectural “smell”. Alternatively, could it be an over-emphasis by the business on efficiency over all else, suggesting a cultural and sustainability concern.
The other key problem with an organisational single-point-of-failure is that it creates a bottleneck, and thus a lack of flexibility, or Agility, in the business. It's also another case of the tail wagging the dog (Tail Wagging the Dog), with the bottleneck forcing the decision-making and pace of the business. This is disadvantageous to the business, yet it's a practice businesses (and managers) repeat again and again with an overemphasis on productivity, putting the efficiency needs of an individual unit (be it person or team) over the agility needs of the business. I describe this thinking here (Unit-Level Efficiency Bias, Unit-Level Productivity v Business-Level Scale).
And finally, the very nature of a single-point-of-failure in this context indicates a lack of collaboration (willing or not) and isolation, creating two issues:
- The quality of the work within that domain may deteriorate and no one knows. Diversity isn't just some buzzword, it's a critical aspect to promote quality in the overall solution, and its Evolvability. Without it, we are increasing our Technical Debt (in a sense doubling down on the problem), without knowing it.
- The individual feels increasingly isolated and overworked, and eventually quits - something particularly disruptive when we're talking about a single-point-of-failure. Some (bad) managers might place the blame on the individual, but more often than not, it's a problem of our own making. By isolating someone, to the point where no-one could support them, we have - in fact - driven them away, making it a fault on the part of management, not the employee.
FURTHER CONSIDERATIONS
- IaC (Infrastructure-as-Code) - https://en.wikipedia.org/wiki/Infrastructure_as_code
- Assumptions
- Blue/Green Deployment
- Cloud
- Control
- Serverless
- SLAs
- Tail Wagging the Dog
- Technical Debt
- Unit-Level Efficiency Bias
- Unit-Level Productivity v Business-Level Scale
ENDLESS EXPEDITING
Endless Expediting typically happens when a business is so large or unwieldy, their communication paths so convoluted, and the work they undertake takes so long, that nothing is ever finished. They are embraced by massive Manufacturing Purgatory.
These businesses are constantly in the throes of Expediting as new ideas are generated, the business changes priorities, or modernity (e.g. technology) makes an earlier decision substandard. Work-in-Progress (WIP) is paused or cancelled in favour of the new approach, which - due to the aforementioned challenges - then follows exactly the same trajectory as the usurped idea. Ad infinitum.
Endless Expediting also creates a lack of Agility (one of the worst possible outcomes), caused by the glacial pace that everything moves at, and thus causing the business to move even more slowly.
FURTHER CONSIDERATIONS
PROJECT BIAS
The "cult of the project" often promotes short-term, project-oriented thinking and delivery, over longer-term Sustainability needs; i.e. there's a bias heavily in favour of finishing the project, but forsaking some Sustainability.
CAVEAT
Of course this isn't true for every case, but it's certainly something I see too much of.
In this model, project leads are incentivised (and applauded) to deliver a project within the original constraints (regardless of the problems encountered during it that weren't considered at inception), and (implicitly) disregard the longer-term consequences of their decisions and actions. Once the project is deemed complete, project staff are quickly shifted onto the next, to repeat it all over again, never to resolve the issues created previously.
AGONY & ECSTACY
Broadly speaking there's a penalty to staff who fail to deliver a project (e.g. the notorious annual review), but rarely one for missing the sustainability needs of a business. In part, this is due to a lack of a common Sustainability definition, making it impossible to accurately measure. But there's also an immediacy bias (Immediacy Bias). The consequences of missing a project delivery is felt almost immediately, whereas the consequences of missing Sustainability needs may not raise itself for years.
FURTHER CONSIDERATIONS
EFFECTIVE OVER EFFICIENT
The statement to "do the right thing, over the thing right" means that we should prioritise working on the correct things ahead of prioritising the quality aspect of a feature with little customer value.
The words “efficient” and “effective” are not synonymous. Efficiency relates to Productivity - e.g. how efficiently you can make a change. Effectiveness relates to how effective we are at influencing and engaging our customers and business.
For instance, let's say that I can build and release a new API feature all in a day. That's pretty efficient. However, let's now say that the functionality I built within that API is irrelevant to my customers. That makes me (and my API) ineffective. I've been working on the wrong thing, and therefore haven't engaged my customers' interests, generating Waste (in terms of ROI and TTM, but also by further complexifying the estate). So what if I'm highly efficient if I can't make something to benefit my customers, and solve real business problems. In that case I should immediately stop and identify effective ways to make a difference.
GOLD PLATING EFFICIENCY BIAS
Gold Plating - the unnecessary refinement of software or processes for no effective benefit - is an easy trap to fall into, and often the sign of an Efficiency Bias.
FURTHER CONSIDERATIONS
MULTI-FACTOR AUTHENTICATION (MFA) & TWO-FACTOR AUTHENTICATION (2FA)
Authentication (and authorization) is a broad subject, and one I will only touch upon. Authentication relates to how someone (or something) proves they are who they claim to be. Authorization relates to what they are permitted to do.
The most common form of authentication is the single-factor (“password”) model, in which the user supplies a username and password for the system to verify. Whilst it's been used for many years, it has certain flaws.
Because it only uses a single factor, it only requires that one factor to be captured (i.e. stolen) for the account to be compromised. To counter this, the industry introduced a series of hardening approaches - from increasing password lengths, mixed-case, and mandating certain special characters, to encryption, “salts”, and the notorious (monthly) password reset, which added a temporal aspect. They increased Security, but sacrificed Usability, in the form of increased complexity and cognitive load, leading to more forgotten passwords, written-down passwords, and password reuse. Fundamentally, the single-factor model is limited.
BALANCING SECURITY & USABILITY
There's always a balance to be struck between Security and Usability. Lean too far toward security and we affect how usable the solution is, lean the other way and we've probably got a highly usable solution but little in the way of security.
The single factor (password) model is a prime example. New controls were introduced when the model was deemed to be insufficiently secure (e.g. regular password resets), each one reducing the usability of the solution, and in some cases, having the opposite effect to what was planned.
So what is MFA (and 2FA)? As the names suggest, multi and two factor use more than one authentication factor. It's rare for us to discard our existing (password) factor, rather we enhance its security potential with another factor.
So how does it work? Well, a factor is typically one of the following:
- Something you know. Our ubiquitous password factor fits in here, but a pin might be another example.
- Something you have (or own). These are channels like a SMS text message, a Soft Token (such as Google Authenticator), or a hardware key fob. They are something you can physically access.
- Something you are. This relates to something peculiar to the individual, such as a fingerprint or a retinal scan.
Note that the "something you have" factor often has a temporal aspect to it too. For instance, a SMS link may be valid for 5 minutes, whilst a soft token value may change every minute. The point of this isn't to frustrate the user, but to enhance security. Should an attacker capture the SMS message, they must do so within the allocation window for it to be useful.
LOCALISED ATTACKS
It's significantly harder and more taxing for an attacker to capture both the first factor (assume username/password) and the second (e.g. device). Many attacks originate from afar (even internationally), and happen digitally. Having to undertake a localised and physical hack isn't - I suspect - particularly appealing, and consequently we can view multiple factors as a decent form of protection.
Returning to our options (something you know, something you have, something you are), the recommended practice is to employ two (or more) distinct factors, such as: a password and a SMS text message, a password and soft token, or a password and fingerprint.
VARYING THE FACTORS
A two-factor authentication that incorporates a password and a pin is preferable to a single-factor password model, but it still represents two discoverable items an attacker can uncover or brute-force. This is tougher when those factors are distinct.
And finally, there seems to be some haziness around the distinctions between 2FA and MFA. Put simply 2FA requires two forms of identification, whilst MFA requires at least two forms of identification. That's it.
DORA METRICS
In 2016 the DevOps Research Assessment (DORA) team [1] published a set of measurable qualities considered to be a good foundation for success. They are:
- Deployment Frequency. How often do you release change to the production environment?
- Lead Time. How long does it take to release a change to the production environment?
- Change Failure Rate. What percentage of those released changes caused a failure or instability?
- Time to Restoration. On failure, how quickly can you recover the service to a working state?
DEPLOYMENT FREQUENCY
The frequency with which we deploy changes (to production) tells us something about Flow, risk appetite, and working practices. I've described elsewhere how a batch mindset leads to low (and slow) rates of change, high risk, and (most importantly) a culture of Release Fear. This isn't healthy.
There's something to be said for the regularity and normalisation of software releases. Some businesses still view them as a dark art that few are willing to brave, rather than a straightforward and commonplace activity. This generates fear, and consequently, creates an unseen (and undesirable) barrier.
Normalising releases though, by enabling anyone (or anything) to perform them, making them a (relatively) simple and low risk activity (through automation), and through cultural promotion (e.g. Small Batches, Definition of Done), promotes excellent TTM and Agility. Customers receive something sooner, and (business) risk is reduced.
NEW & EXISTING CODE CHANGES
Deployment frequency should relate to all changes (new software, and the maintenance of existing software) to ensure Sustainable practices are employed. It's easy to deploy new software once, quickly, but miss the (vital) repeatability aspect associated with regular change.
PREDICTABILITY
Predictability is another important consideration. It's difficult to accurately predict a release date with large batches, due to its many influences, complexity, and inconsistent sizing. That's less true of regular, small releases, who attract opposing qualities - limited (comparable) complexity, fewer influences, and fewer Surprises.
LEAD TIME
Lead Time has interesting connotations on TTM, ROI, Entropy, Flow, and Manufacturing Purgatory. It may also imply Waste (e.g. Waiting), issues within a Value Stream, and cultural concerns (e.g. too much Work-in-Progress (WIP)).
Customers want quick delivery, as do businesses. Long lead times reduce returns (ROI) - with work stuck in Manufacturing Purgatory - but it also slows feedback (Fast Feedback), making it difficult for businesses to react and adapt to changing circumstances.
Again, Batch Size plays a significant role here. The larger the batch, the more change (and consequently risk) it contains, the greater the effort (time) to verify and release it, and the greater the coordination effort.
CHANGE FAILURE RATE
The rate of change failure - the percentage of changes causing a failure or other unintended consequence - can be revealing, and may include: our true beliefs on quality (i.e. not the ones we might publicise), how well we've prepared and planned for work activities, the strength (or otherwise) of our testing and automation approach, and our operational readiness.
For instance, a failure due to poor preparation (e.g. a missed requirement) indicates something about our Definition of Ready (have we sufficiently captured, understood, contextualized, and collaborated on the requirements and acceptance criteria?), or our Definition of Done (have we done everything required to make this successful?). A defect intimates an inadequacy in our testing and automation strategy (and engineering practices), whilst a runtime failure identified by our customers (rather than us) implies something untoward about our operational readiness.
PRODUCTION ONLY
We're only discussing failures in the production environment, not those which are caught earlier.
There's no point in being fast if you can't also be accurate, and consistent. It's the equivalent of being efficient but ineffective (Efficiency v Effectiveness), which is ultimately pointless. Production failures are one of the worst forms of waste (The Seven Wastes), of course due to their impact, but also to their rework cost [2].
TIME TO RESTORATION
Everyone makes mistakes. The key is to not repeat them and quick resolution. The longer a problem exists, the greater the potential Blast Radius (as it increasingly impacts a greater number of users and systems). The greater the Blast Radius, in this case time, the more potential damage is done to a business (Reputation).
MTTR
Mean-Time To Recovery (MTTR) was discussed in the Availability section. It's the duration it takes to restore a system to a working, and available state, including the time required to fix it.
Lead Time also plays a factor in recovery time. The longer the lead time, the longer the likely recovery time (without resorting to Circumvention and Hotfixes). WIP is another concern. The more work a business juggles, the harder it's coordination, and the more need to expedite (Expedite) - a desirable quality in such a scenario.
SUMMARY
DORA metrics are a great way to measure progress, and I believe, success. They link back to every Business Pillar, certain underlying qualities, and therefore influence KPIs.
RELEASABILITY
Releasability is: “the ability to efficiently, repeatedly, and reliably deliver value to the customer”. This fits nicely with some of the DORA metrics.
One benefit of these metrics is that they can be used comparatively, either to view trends, or to address more immediate concerns. For instance we can identify deterioration, indicating downturns in production (output), lengthening lead times, or increases in faults. A steady decline suggests a lack of sustainable practices (Sustainability) being employed, and that Technical Debt is rising and requires addressing.
FURTHER CONSIDERATIONS
- [1] - https://cloud.google.com/blog/products/devops-sre/using-the-four-keys-to-measure-your-devops-performance
- [2] - the cost of a production failure is many times more expensive than if caught early in the engineering lifecycle. It also causes Expediting and Context Switching.
- Blast Radius
- Circumvention
- Definition of Done
- Definition of Ready
- Efficiency v Effectiveness
- Entropy
- Expediting
- Fast Feedback
- Flow
- KPIs
- Manufacturing Purgatory
- The Seven Wastes
- Surprises
- Technical Debt
- Value Stream
- Work-in-Progress (WIP)
KPIS
A quick philosophical question for you. How do you measure success?
There are, of course, many ways to answer this. You might answer it from a purely materialistic perspective (money, fame, or reputation), or as something more personal. You might start by establishing a (joint) definition of success, since it's not necessarily objective, is it?
Initially, we may disagree - my idea of success might be quite different from yours. But one thing we should agree upon is that success is rarely quick. It's typically the result of many months and years of toil and hard labour (and even then it's not guaranteed).
Success then - in whichever form - is influenced by two things. Your ability to define your goal, and your ability to reach it. But - as the weeks and months slip by - how do you know whether you're getting nearer, or further away from it? That's what Key Performance Indicators (KPIs) offer - they record and measure a business' performance, improvements, and consequently success. It gives us a means to compare (against historical datasets), and adjust accordingly.
KPIS AND REACTIVE BUSINESSES
The concept of defining the goal and then measuring progress towards it seems a rather obvious premise, and surely a widespread practice, but it's sometimes lost in the busy day-to-day activities, particularly of highly reactive businesses. Staff in those environments become conditioned to work and think reactively, something that's surely not sustainable. KPIs can help here.
KPIs could be anything. They might be the number of orders, client sales, annual subscriptions, on-boarded customers, "active" customers (whatever that means in your context), success rollout of staff training, staff retention, publications, page reads etc. It's probably a combination of things. It's your business, you decide upon the indicators.
SENTIMENT
Not everything is readily measurable. One alternative is sentiment. For instance, we might gauge cultural improvements through a mix of metrics, like staff retention, and sentiment (“are people happier or sadder than three months ago?”).
Many of the challenges with KPIs lie not with the measurements, but with the gathering of the information. It's not that you don't have it, but it's either difficult to retrieve or aggregate it, or it's strewn over too wide (and diverse) a range of sources to be extracted from them all.
DATA ACCESS
This is often the case in large organisations with a vast and diverse estate (essentially multiple systems doing the same job), or widely distributed data sources (e.g. Datasource Daisy Chaining). The data exists, but gathering it is - to all intents and purposes - unrealistic and (overly) burdensome.
A data centralisation strategy (e.g. Data Warehouse) is commonly employed here in an attempt to simplify data consumption. However, it rarely takes into account making the data available to centralise it in the first instance.
IMMEDIATE V EVENTUAL CONSISTENCY
Consistency relates to a system's or dataset's ability to remain in a consistent (complete) state. Fundamentally, it's about its Reliability and Confidence. It's consistent with your expectations, such as how it's represented in relation to the real world. All parts are all complete and accurate (integrity).
Consider a legal document, such as a will. It's composed of multiple parts, including testator, executors, guardianships, assets, and signatures. Should we capture everything except signatures, it wouldn't be credible. Being incomplete, it's inconsistent with our expectations of what a will should be.
DEFINITION
Consistent is described as - "always happening or behaving in a similar way" [1]
Unless carefully managed, inconsistencies create unexpected behaviour and a loss of confidence. It's easy to see why. It's frustrating for customers to see incomplete information on an important transaction. But it's also frustrating for the engineers managing the systems, who must spend hours investigating why there's an incomplete picture.
Before moving on, it's important to discuss atomicity, time (i.e. the temporal factor), and transaction distribution.
ATOMICITY
Atomicity - the act of being atomic - is a very useful system quality, particularly around transactions. Fundamentally, it's an all-or-nothing model - all operations occur, or none do. When atomicity is guaranteed, a system can't get into an inconsistent state.
Wikipedia describes it as: “An atomic transaction is an indivisible and irreducible series of database operations such that either all occurs, or nothing occurs. [2] A guarantee of atomicity prevents updates to the database occurring only partially, which can cause greater problems than rejecting the whole series outright. As a consequence, the transaction cannot be observed to be in progress by another database client. At one moment in time, it has not yet happened, and at the next it has already occurred in whole (or nothing happened if the transaction was cancelled in progress).” [2]
If we were to apply atomicity to our will transaction, and view it, we'd find it could only be in one of two states: nothing (time unit 0), or everything (time unit 1). See below.
| Time Unit | 1 | 1 | 1 | 1 | 1 |
| Operation | Testator | Executors | Guardians | Assets | Signature |
The centralised (Monolithic) model, with more localised interactions, can better leverage database transaction scope, and thus Atomicity. One application, one database, one transaction. It doesn't exist, and then it does, there's no in-between. Or to reiterate, it's immediately consistent. The transaction is complete and accurate and can be immediately worked on. This is in marked contrast to the temporal and distributed factors I'll describe next.
THE TEMPORAL FACTOR
Time is a useful tactic to introduce some slack between business processes, people, and systems. For example, when I initiate a business transaction with some parties, I'm commonly told by them that: “the systems aren't updated till close of play tonight. It should be there tomorrow.” I'm so used to this behaviour that I don't even bat an eyelid. Under the hood, it's clear there's some form of queueing (not necessarily in the technology sense), or distribution of work, going on.
This approach allows us to decouple the requestor (the entity requesting an action) from the processor (the entity, or entities, responsible for actioning the request). Whether it's a system, or people, is beside the point. We've broken a complex, synchronous, and time-dependent task down into multiple discrete stages, thereby promoting . Availability (the processor doesn't need to be available at exactly the same time as the requestor), Scalability (we may introduce more entities to support increased loads, or reduce a queue size),
Performance
(the requestor need not await for you to finish everything, they can do other things), and Agility (we can make adjustments to better meet our objectives).QUEUES & TIME
We employ Queues to decouple, and therefore protect, systems of differing performance, scalability, and availability characteristics from one another.
Regrettably, the act of decoupling ourselves from time can create consistency issues, particularly if ordering isn't adhered to (consider the effect of creating an order prior to the customer record), with some parts of a transaction complete, and others still unprocessed. In this case, the transaction is inconsistent with our expectation of what it should be. The most obvious consequence of using time as a bulkhead is Eventual Consistency. We can't guarantee exactly when each part of a transaction will complete, and must accept some likelihood of inconsistency.
TIME != ASYNCHRONICITY
Asynchronicity isn't directly about time, it relates to any dependencies upon previous steps. It's quite possible (and sensible) to employ a temporal bulkhead in a sequential flow. We do this all the time in the real world, for example, when we queue for coffee in our local coffee shop.
Failure in this mode can leave us in a bit of a mess, with a partially complete (inconsistent) transaction to be identified, diagnosed and remedied.
Finally, it's worth mentioning that temporal implies distribution, something we'll discuss next.
DISTRIBUTION
The third aspect to consider here is distribution; e.g. a Distributed Architecture. In a similar vein to the temporal factor (time), we employ distribution to promote (for instance) Agility, Scalability, Releasability, Flexibility, and rapid change. Unlike the centralised model, it requires us to distribute a (business) transaction across multiple system boundaries, implying a loss of Atomicity. See below.
In the first scenario (left), typical of a monolith, one transaction (Tx A) manages all five database interactions, often into the same (monolithic) database schema. The second case, more familiar in distribution, is quite different. In this case, a transaction is managed per action (assuming each database interaction is encapsulated by a single distributed interaction).
Distribution need not be asynchronous (independent), yet we can still fall foul of inconsistencies. Let's return our attention to the Will writing scenario. In the distributed model, we might build distinct microservices for each step; i.e.: Testator, Executors, Assets, Guardians, and Signature services. See below.
| Time Unit | 1 | 2 | 3 | 4 | 5 |
| Operation | Testator | Executors | Guardians | Assets | Signature |
It doesn't look vastly different to the earlier, centralised example. Note though, how we get different views of the overall business transaction at different points in time. For instance, we only see the testator, executors, and guardianship records at time unit 3. It's definitely not atomic, which makes sense considering that each service is discrete and typically has its own (independent) data store.
Failures are another problem in this model. What happens if our transaction fails part-way through? We don't have the luxury of all-or-nothing atomicity, so we're left with a partial data set - a partial digital representation - that isn't representative of the whole, nor the real world.
DATA DUPLICATION CONSISTENCY
Data Duplication (Data Duplication) is just another form of distribution - in this case of data. We commonly find ETLs sandwiched between the (two) data stores, shifting data from one to the other.
ETLs though have a tendency to be (written as) a bit heavyweight, and “batchy”. It's quite common to execute them only once or twice a day, meaning data is stale, or inconsistent during that period.
CAP THEOREM
CAP Theorem (Consistency, Availability, Partition Tolerance) states: "In theoretical computer science, the CAP theorem, also named Brewer's theorem after computer scientist Eric Brewer, states that any distributed data store can provide only two of the following three guarantees… Consistency, Availability, Partition Tolerance.” [3]
You might be curious about Partition Tolerance. With this in place: “The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.” [3]. Therefore, when a failure occurs, you may either continue (knowing that it might lead to inconsistencies), or you stop the action (knowing you've reduced availability).
To reiterate, if you have a partition, which you must do with a distributed system, then you can have either Availability or Consistency, but not both. The data is either available, but not necessarily consistent, or it's consistent, but not necessarily (immediately) available. If you need high availability and partitioned services, then you must reduce your consistency expectations. If you want consistency and partitioning, then you must reduce your availability expectations.
SUMMARY
Consistency is a measure of a system's or dataset's ability to remain in a consistent (complete) state. A transaction is consistent with your expectations if its component parts reflect how it should be represented in the real world.
There are two common modes:
- Immediate Consistency. The transaction is immediately consistent with your expectations.
- Eventual Consistency. The transaction becomes consistent over a period of time, but not immediately.
Centralised (Monolithic) applications tend to have more localised interactions, so can better leverage Atomicity; i.e. an all-or-nothing success or rollback model. That makes them immediately consistent.
Conversely, distributed solutions (e.g. Microservices) exhibit greater isolation, and often use independent (and different) database technologies. Atomicity isn't really an option here, creating consistency (eventual), and rollback challenges. This is also true of temporal practices (e.g. bulkheads, such as Queues) - a business transaction remains incomplete (and may produce inconsistent results) until all temporal parts successfully complete.
That leads us into a nice segway into failures. A failure in the atomic model results in the complete reversal (rollback) of the transaction. Admittedly, this isn't always necessary, but it's a powerful protective tool to retain consistency. A failure in the distributed, or temporal model, though, requires a degree of detective and remedial work to return the transaction to a consistent state.
FURTHER CONSIDERATIONS
- [1] - Cambridge Dictionary
- [2] - https://en.wikipedia.org/wiki/Atomicity_(database_systems)
- [3] - CAP Theorem - https://en.wikipedia.org/wiki/CAP_theorem
- Asynchronicity
- Data Duplication
- Distributed Architecture
- Microservices
- Monolith
- Queues
(BUSINESS) CONTINUITY
"Humpty Dumpty sat on a wall.
Humpty Dumpty had a great fall.
All the king's horses and all the king's men
Couldn't put Humpty together again."
- Nursery Rhyme
Google's dictionary defines continuity as: "the unbroken and consistent existence or operation of something over time."
Continuity, in the context of an organisation, is its continued ability for it to function, to operate, and retain an appropriate level of operational service, even after a significant disruptive event (or disaster).
It might surprise the reader to learn that not everyone thinks in these terms. From my experience, I'd say a panglossian, overly optimistic, outlook is quite common. And not everyone has a plan.
Whether your business is in the private, public, non-profit, or governmental sector, your business (probably) offers its customers a service. What happens though, when its ability to offer that service is impaired, or eliminated, by an unexpected factor? Does it continue to function? In what capacity? As Humpty Dumpty found out (probably to his dismay), how do you put the pieces back together when your world is so fragmented, obscure, nebulous, unautomated, and untested (in terms of proven resilience), or when you are no longer in Control?
ASSUMPTIONS
Like Resilience, Continuity is heavily influenced by Assumptions - e.g. an over-reliance on a partner, system, physical location, or geographic zone. What sort of assumptions have you made that are false or unreliable?
Of course, the counter-argument is money and time; i.e.: "Why should we spend all that money and time on something that'll never happen?" Sure, you could do nothing, but isn't that a form of betting? Consider our modern world. It's more complex than it's ever been, and becoming increasingly so. Rightly or wrongly, humanity is more dependent (i.e. coupled) on technology, our consumer expectations and needs are greater (Ravenous Consumption), and our reach (e.g. social and commercial) extends much further. Only a short time ago many businesses still relied upon their staff to be physically present at a specific location to undertake operational activities - they weren't prepared when the pandemic struck, and it ended up being a poor Assumption. In this case, continuity was risked by a pandemic, but it could just as easily be a cyberattack, an employee leaving (if they are a Knowledge Silo), a failing business partner, a Single Point of Failure, or some other “disaster” causing a loss of service.
RECOVERY TIME
Recovery is important, but so too is recovery time. For instance, if your system is lost, can you take it elsewhere, and do so within a reasonable timeframe? How would you do this? Has it been tested?
The key to continuity is being proactive. Probably the most important starting point is creating a Disaster Recovery (DR) Plan. From there it should be regularly tested. SLAs also have an important part to play here. They define acceptable service levels (typically under normal conditions), making them a useful metric to build resilient systems and operations. Red Teaming is another useful technique for identifying weaknesses. Finally, you should consider Complexity. If your estate is complex, that implies something that's difficult to fathom and recreate. Continuity here is protected by reducing that complexity.
FURTHER CONSIDERATIONS
- Assumptions
- Control
- Disaster Recovery
- Knowledge Silo
- Ravenous Consumption
- Red Teaming
- Single Point of Failure
UPGRADE PROCRASTINATION
Upgrade Procrastination relates to a tardiness in upgrading systems (or indeed practices) in line with customer (possibly indirectly), business, or industry expectations. It has a notable effect on both Security and Evolvability and is often influenced by Functional Myopia.
Procrastination may occur in any layer, including in hardware, Operating Systems, runtime platforms, libraries, and applications. Security and Evolvability are more heavily influenced (and mitigated) through a coordinated, multi-layered strategy. For instance, upgrading a software application only to leave it running on an old (insecure) hardware, operating system, or runtime platform, only alleviates, it doesn't remove risk.
WHY PROCRASTINATE?
Why procrastinate? Well, like many other non-functional aspects, upgrades are generally deemed less important than features. Also, regression costs are often an impediment.
The second point I have on Upgrade Procrastination is time. The longer it's left, the harder it is to do. Tardy upgrades involve more changes, thereby increasing risk, causing a large Blast Radius and Change Friction, and consequently a lack of impetus. An upgrade "event horizon" is reached - a point of no return - where the upgrade, even when highly desirable, becomes (pragmatically) impossible, and must be abandoned. Such a position typically leads to a shortened product lifespan, slowness (i.e. poor TTM), reduced competitiveness, and reduced staff retention. Don't leave it too late. It's not important until it's important, and by then it might be too late.
BLAST RADIUS V CONTAGION
Whilst Blast Radius and Contagion are related, they're not the same. Blast Radius relates to our (in)ability to act, whereas Contagion relates to our (in)ability to contain something (bad) that's currently occurring.
To reiterate, Contagion is the consequence of an event that further exacerbates it. It's typically more fast-acting than Blast Radius, stemming from more fluid events, like an ongoing cyberattack or Scalability issues. Blast Radius is slower. It creeps into systems over months and years through bad practices, and poor architectural and design choices.
CONTAGION
The word contagion is well-used in the parlance of our modern world, particularly since the pandemic. Google's dictionary describes it as "the communication of disease from one person or organism to another by close contact." Fundamentally, it's the spreading, or exacerbation, of a problem or situation.
Software systems (indeed any system) face these same challenges. The more interconnected, the greater the potential of contagion, and thus disaster.
BLAST RADIUS V CONTAGION
I've already discussed Blast Radius in this text, which is loosely related to Contagion. Whereas Blast Radius relates to our ability to act, contagion relates to our ability to contain something (bad) that's occurring. See Blast Radius v Contagion.
Within a software system, Contagion can be managed through the employment of a number of techniques, including: an Andon Cord (stop all further processing until a root cause and satisfactory resolution is found), Circuit Breakers (the contagion here being the flooding of another system or component), Canary Releases (to limit how widely a new feature is promoted, until we have conclusive evidence of its suitability), Microservices (one contagion being from large, high-risk releases that are irrelevant to it), Loose Coupling (possibly the contagion of large, high-risk releases, or the impact of a security vulnerability), Time and Bulkheads (such as Queues, to throttle interactions between systems of varying performance characteristics and prevent flooding), isolated backup networks (to retain Business Continuity), Data Centers and Availability Zones (e.g. reduce potential contagion from Acts of God).
FURTHER CONSIDERATIONS
- Andon Cord
- Bulkheads
- Business Continuity
- Canary Releases
- Circuit Breakers
- Loose Coupling
- Microservices
- Queues
PRINCIPLE OF LEAST PRIVILEGE
Systems contain a plethora of damage limitation controls. Indeed Contagion - how widely a problem is exacerbated - is about damage limitation. The Principle of Least Privilege is another of these.
Most systems expect the user (person or system) to be authenticated and authorised before further access is granted. However, it's dangerous to give people more access than they're entitled to (you've seen those spy movies where the protagonist steals a keycard from the security guard, thus allowing them full access to the facility?). Excess privileges may be (intentionally or unintentionally) abused, either by that user, or indeed by attackers able to steal it. Users should only get access to what's necessary, no more. This is the Principle of Least Privilege.
The underlying idea of Least Privilege is quite fundamental, and common sense suggests this should be best practice, so why do we need a principle? Because, even with the best intentions, it isn't always followed. For example, during an application development cycle, it's quite natural to use broad (extended) access to get things done, yet never retract those privileges in production, leaving the application open to abuse. Convenience is another reason. Some businesses make it inordinately difficult to broaden access once it's set. I've seen it take weeks (or months) in some cases, if at all. The somewhat obvious knock-on effect of this is to circumvent it, by starting with those higher privileges, even if they're not immediately required, nor desirable from a security perspective.
MONOLITH & MICROSERVICE
A pure Microservices model, with its own independent datastore, may lessen Contagion over its Monolithic cousin (e.g. access to all tables across all domains), but Least Privilege still applies. Only give users (and others systems) what they need, no more.
INFRASTRUCTURE AS CODE (IAC)
Surprise is rarely a good thing in software. It's often caused by a lack of Consistency, either in environment, or in process. Notably, it also impedes two key delivery qualities - Repeatability and Predictability.
Environmental Drift (the undesired divergence of runtime environments - e.g. dev, uat, production) is a common problem in software businesses. Even a seemingly small and insignificant variance between two environments can have a significant impact. I've seen production deployments fail for no less. Consistency here (i.e. Uniformity) is critical, yet it's at a major disadvantage where: (a) changes occur manually, (b) changes can be circumvented (Circumvention) to only occur in one (typically production), (c) there's no adhered standard for software promotion (from least stable to most stable), and (d) change is commonplace.
TWELVE-FACTOR & IaC
12-Factor Apps makes similar points; e.g.:
- "Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
- Minimize divergence between development and production, enabling continuous deployment for maximum agility;" [1]
As intimated, keeping an environment accurate and aligned can be a costly affair. If it's overly encumbering it'll inevitably get circumvented, and inconsistencies creep in. Over time, it drifts until all credibility is lost, and ultimately, it's discarded. We should avoid this situation.
Another concern lies in the overextension of environmental responsibilities; i.e. an environment is used for too many unrelated responsibilities. Possibly the most notorious example of this is running sales demos from an unstable, unbounded (development or test) environment. It's fraught with danger and has a whiff of unprofessionalism best left unadvertised to prospective customers. The common factor here is typically one of cost (financial or time), to provisioning another environment, or from a Tight-Coupling dependence on another system (e.g. IDs must match).
Nothing I've said so far breeds confidence (Stakeholder Confidence), Repeatability, Predictability, Continuity, nor speed - all of which should be our driving factors.
Ok, now I've set the scene, let's discuss Infrastructure as Code (IaC). Fundamentally, software needs a place to run. There are some exceptions, but most typically that means infrastructure and runtime platforms. We deploy our software to a (runtime) platform that we've provisioned and configured for that very purpose, thus allowing us to use that software. But how do we get our infrastructure / platform into such a position?
Recall that, historically, this activity has been almost exclusively manual; yet due to the increased complexity of software, it's made such intervention entirely impractical [2]. The only real alternative is automation, but to do that, we need a way to program it. This is Infrastructure-as-Code (IaC). We write code to provision (and configure) the infrastructure necessary to run our software applications. We declare how it should look and allow the machine to find the most reliable and efficient way to achieve it.
Let's turn now to our driving factors and see what IaC means for them.
REPEATABILITY
The main problem with manual intervention is its (relative) lack of Repeatability. If you ask two people to do the same job, there's a reasonable chance they'll do it differently, even with explicit instructions. Yet we need consistency. Two environments can't be almost the same, they must be precisely the same [4].
IaC solves the repeatability problem through Automation, repeatedly producing the same results time after time. Confidence flows from this.
PREDICTABILITY
If you can create stability, consistency (through repeatability), and limit Surprise (e.g. by using machines rather than people) then you can - with reasonable accuracy - predict the outcome. And when you can predict the outcome is predictable, everyone gains.
SPEED
One of the drawbacks of manual provisioning is its (relative) slowness. The more steps, the longer it takes, and the more likely an error will creep in.
If environments can be quickly and easily provisioned, then we can do it Just-in-Time (JIT). Consider the tester who wants to test an older software release that's been superseded by a later one in the UAT environment. They can easily spin up a new environment, test it, and destroy it in quick succession. Consider a Sales team who can quickly spin up a demo environment just-in-time for an important sale, and then easily destroy it afterwards. Consider a prospective client who can quickly spin up their own environment to try out your product. Speed is of the essence. You can do all this with IaC.
CONTINUITY
A less obvious - but important - benefit of IaC is Continuity and Disaster Recovery.
For instance, should a successful Ransomware attack be executed on your systems, it needn't be catastrophic. Yes, you may be locked out of your current transactional systems, but IaC makes it recoverable. You can take that code and (rapidly) recreate it elsewhere [3].
CONFIDENCE
All of the previous points create confidence (Stakeholder Confidence). Confidence we'll get a like-for-like environment; confidence we can predict the outcome; confidence we can deliver it quickly; confidence we can continue to function as a business in the most unpredictable of circumstances; and confidence that a new environment can be "self-served" by a non-tekkie. What more do you need?
FURTHER CONSIDERATIONS
- [1] Twelve-Factor applications - https://12factor.net
- [2] - It's too easy to miss something, run something in the wrong order, or misconfigure it. The sheer quantity of instances - mainly due to distributed architectures - also makes this impractical.
- [3] - other than the expected environmental differences.
- [4] - You have backed up your code to an alternative site haven't you?
- Circumvention
- Continuity
- Disaster Recovery
- Stakeholder Confidence
- Surprise
- Tight-Coupling
BLAST RADIUS
Blast Radius relates to the scale of change, and therefore the effort necessary to make a single change. Or: “if I change this, what's the knock-on effect?” See below.
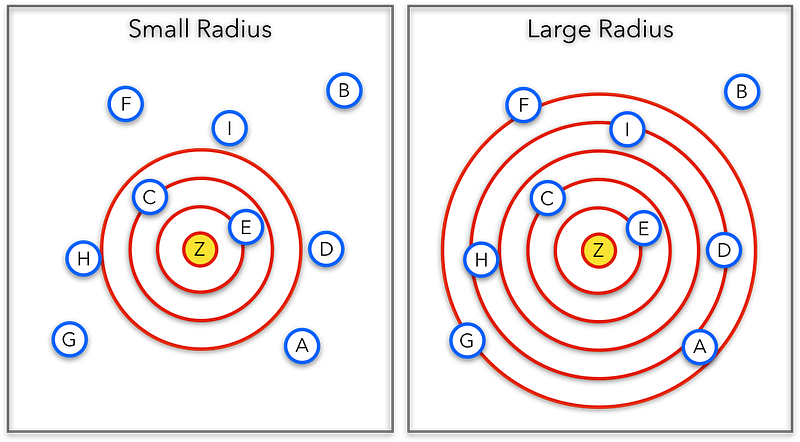
It shows the impact between a small blast radius (on the left) and a large blast radius (on the right).
Assume in both cases that the central component (Z) acts as the initial stimulus of change. In the example on the left, our component's radius is relatively small. It impacts two others (C and E). The example on the right though impacts many (eight by my reckoning). Now, it depends upon the type of change, but given the choice, I'd opt for the first scenario [1]. It's more change than I'd like, but it's eminently more manageable than the second.
Of course, this mindset is quite natural. Do the smallest thing, of the highest (immediate) value. Don't undertake work where one (anticipated) change generates eight pieces of reactionary, unrelated, but necessary activities, when you can do something smaller.
Clearly, it's unappealing, and therefore never gets done. Yet it doesn't resolve the root cause, it simply kicks the problem further down the road for someone else to deal with.
SMALL V LARGE RADIUS
To be clear, a Blast Radius which is small (a small radius) isn't necessarily an issue, since its impact is likely to be low. Conversely, a large Blast Radius implies lots of change, regression effort, high organisation and coordination costs, and risk.
A large blast radius reduces optionality, your ability to make change (Agility), and thus stymies Innovation and advancement. It's typically associated with a large amount of Tight-Coupling, and generates Change Friction. As the saying goes - there be dragons! Any attempts to resolve it are hampered, leading to longer-term Evolvability, Sustainability, and Agility concerns.
BLAST RADIUS & CONTAGION
Blast Radius relates to Contagion, however I view contagion as the consequence of an event that typically exacerbates it. It's more fast-acting than Blast Radius, such as from a cyberattack or poor Scalability. In contrast, Blast Radius is slower. It creeps into systems over months and years through bad practices, and poor architectural and design choices. See Blast Radius v Contagion.
Blast Radius can occur anywhere where: (a) many dependencies rely upon something capable of evolution, and (b) you can't sensibly break the change into smaller, independently releasable units of work. Most often I see it in systems that allow “database dipping” - where many (unrelated) consumers dip into a database to access data for their own needs, and circumvent any existing interface (e.g. API), such as with Domain Pollution. This is why Encapsulation is best practice! The other common scenario is a runtime platform upgrade on a Monolith.
FURTHER CONSIDERATIONS
- [1] - it's possible that the high complexity of change within a small number of areas actually overshadows the complexity of many small changes within a large number of areas.
- Blast Radius v Contagion
- Change Friction
- Contagion
- Domain Pollution
- Monolith
- Tight-Coupling
RUNTIME & CHANGE RESILIENCE
I can think of two distinct forms of Resilience. In the more traditional sense, we have the resilience (or lack of) introduced by unexpected events (e.g. environmental factors). In the other sense we have the resilience (or lack of) introduced by intended changes that don't go to plan, such as a software release. Both forms can cause service outages.
Why distinguish between them? Because some systems and approaches are more susceptible to one form of resilience, or both, than others.
For instance, let's consider the Monolith. In terms of runtime resilience, we have something of a mixed bag. It's resilient to a point. However, in terms of change resilience, its broad scope, Tight-Coupling, Batching, and Lengthy Releases actually generates change risk, thus making change resilience relatively poor.
Alternatively, by easily adding further routes for High Availability, Infrastructure-as-Code (IaC) can magnify runtime resilience, and also offer decent change resilience, due to its repeatable (and therefore predictable) attributes.
THE PRINCIPLE OF LOCALITY
In Alexandre Dumas' novel The Count of Monte Cristo, Baron Danglers amasses a small fortune through insider trading, by receiving important information before others. The Count then employs the telegraph (and some social engineering) to publish false information and therefore impoverish Danglers [1]). This approach makes use of the Principle of Locality - the idea that some sort of benefit is received by being physically close to something else.
High performance is typically achieved through a combination of low latency (the time taken to travel from component A to B), and fast processing time. Low latency is strongly influenced by the locality between sender and receiver. The closer they are (both physically and logically), the less traveling time, the lower the latency, and the greater the performance. The Monolithic application is a case-in-point. The fact that it's centralised means communications between sender and receiver are local (no network), making them extremely fast.
THE PRINCIPLE IN TRADING
There's a reason why traders pay top dollar to locate their software as close to the stock market as possible. It's based on the Principle of Locality. A seemingly small delay (e.g. fractions of a second) in high-speed trading can give your competitors an unfair advantage over you, resulting in significant lost revenue.
We also find this principle relevant across global solutions. For instance, it's not always expedient to centralise locality in one place, and expect customer requests to travel long distances. See below.

For instance, customers from India or Japan probably aren't going to have a good experience if their digital transactions must travel halfway across the world to access services in the U.S. Rather, by using the Principle of Locality, we place those services nearer to their customers (Cloud vendors use Edge Services in a similar way), tailoring that experience to them.
REACTION
Some businesses find themselves stuck in an endless spiral of reaction, so much so that their decision-making is based almost exclusively on it and they lose sight of their overarching goal and business strategy. It's like being stuck in a foxhole, under fire, with no clear idea of how to get out.
Reaction is fine in small quantities (e g. it shows a willingness to meet customer needs), but it's a trap to continually work in this manner. See The Cycle of Discontent.
EVOLUTION'S PECKING ORDER
In terms of software, evolution has a pecking order, determining how regularly it changes, morphs, or evolves. See the table below.
| User Interface (UI) | Business / Service Tier | Data Tier | |
|---|---|---|---|
| Rate of change | Fast | Medium | Slow |
The user interface (UI) is seen by the largest number (and variant) of stakeholders, and therefore receives the most opinion, Bias, and Bike Shedding. It's what you put in front of your prospective customers, or onto your corporate website. It's therefore one of the first signs of modernity, or lack thereof. That puts it high on the evolutionary pecking order.
Next comes the business / service tier, containing all of the features and business logic required to offer customers a “business service”. This tier certainly changes, but holistic change tends to be harder and slower (than UI changes), the functions are more valuable (than a UI), and we expect a decent level of reuse from it. This makes evolution slower. It's common, either to route new (service layer) components into existing data sets, or to use them to wrap legacy monoliths (e.g. SOA).
Data is probably your most valuable asset, bringing Loss Aversion into play. It's seen by the fewest (at least directly [1]), and probably requires the deepest level of understanding and contextualisation. It's also a time machine - a historic record of the past - which most of us consider immutable. That makes change hard.
TRANSFORMATION AFFECTS ALL TIERS
Digital transformation is hard, in part because it typically affects all three areas (user interfaces, business layer, and data). You're fundamentally changing the way you operate the business and technologies to meet modern challenges.
FURTHER CONSIDERATIONS
- [1] - I mean direct interaction with it. Data could have layers of transformation in the business tier, before it's consumed.
- Bias
- Bike Shedding
- Loss Aversion
LATE INTEGRATION
Integration is typically one of the final stages of a project. It's also one of the more complicated and time consuming. Waiting to integrate therefore adds risk and creates unpredictability. It thereby goes that by integrating early and often, you create Fast Feedback, generating the confidence to proceed, but also reducing risk and increasing Predictability.
- It's incredibly common to get pushback here - people are naturally inclined towards producing the best possible solution (this is true of authors too!) - so be prepared for comments of the ilk:
- "But it's not ready". Yes, and that's ok. The cause here could be a form of Gold Plating - in the sense that the individual (or team) is unwilling to show their work before they've completed it. This, I understand. It's a bit like asking an artist to present their work before it's finished. However, we're not dealing with work that can be considered in isolation, we're talking about complex, interrelated software entities that don't function in isolation. Without a path to early integration, we introduce two (unnecessary) risks: (a) we invest too heavily in the individual component before we consider if it fits - i.e. we may be working on the wrong things (placing efficiency ahead of effectiveness) and therefore putting the project at risk [1], or (b) we rush the integration piece and may miss something important [2].
- "It can't be done until the end". Possibly. For instance, this might happen when a key dependency (e.g. solution, infrastructure, partner, activity, or access to specific user demographics) is unavailable. But it's still important to understand the details. I can't count how many times I've heard this concern raised, but we've still found a way [3].
- "We can't have our users manually integrating the parts together - that's unprofessional". Possibly, but surely it's less professional to fail to deliver on your promise? The automation of business processes typically requires software representations of the useful functions and the workflows to glue them together. It's common to build the functions first, thereby leaving the workflow part until later. That means you've got useful features, but not necessarily a comprehensive, automated workflow for users. That though, doesn't mean it holds no benefit. Why not ask your users if they'd use it right now, in a valuable but incomplete state? If they're already dealing with a complex, onerous workflow, they may be quite comfortable to manually integrate into it (at certain parts), given it simplifies their lives in other parts. View it as an opportunity - you gain valuable feedback, and the user gets something better.
- "It'll take me longer to do that than to keep going”. Ok, there are cases where this is true, but there are many where it's not, or it's negligible, and it simply needs a bit more coaxing.
Try to understand why these comments are being made (techniques like The Five Whys can help here). If possible, avoid building too deep, too soon, and force integration issues to be solved earlier.
FURTHER CONSIDERATIONS
- [1] - The more features are added, the greater the potential for embedded assumptions, thereby exacerbating integration risk.
- [2] - I can think of at least one space launch that went awry due to poor / missed communications and insufficient integration-level assurances. Something can function at the component level but fail holistically - you need to know that.
- [3] - A common one is the supposed inability to connect a user interface (UI) to APIs because those APIs don't exist. Yet there's a bunch of things you can do to mimic a real API, including "mocking" it, or loading data directly into the user interface from files. Another common one is the suggestion that you can't test new functionality with real users without exposing it to everyone. Not so. You can use Canary Releases here.
- The Five Whys - https://en.wikipedia.org/wiki/Five_whys
- Fast Feedback
- Gold Plating
EXPEDITING
Expediting is the act of promoting a previously lower priority work item ahead of current priorities. Fundamentally, something has changed, you're adopting a new priority, to the detriment of your current work items, with the expectation of some gain (e.g. financial).
Expediting can be a valuable tool, or a nefarious enemy, determined to stop advancement. When correctly employed, it allows you to meet an objective that: (a) wasn't previously known or foreseen, or (b) that has since been influenced by internal or external pressures, and is now causing you to adapt [1].
When used incorrectly, or too often, it becomes a hindrance that: limits Agility and the release of value, creates a lethargy and stasis, promotes Manufacturing Purgatory, Environmental Drift [2], and Circumvention. It affects quality, and can demotivate the workforce (how would you feel after doing work to be told it's no longer important?).
Expediting can feel like the Hokey-Cokey [3]. You put a change in, do a bit of work on it, then take it back out. You then put in another change, do some work on it, and take it back out again. See below.
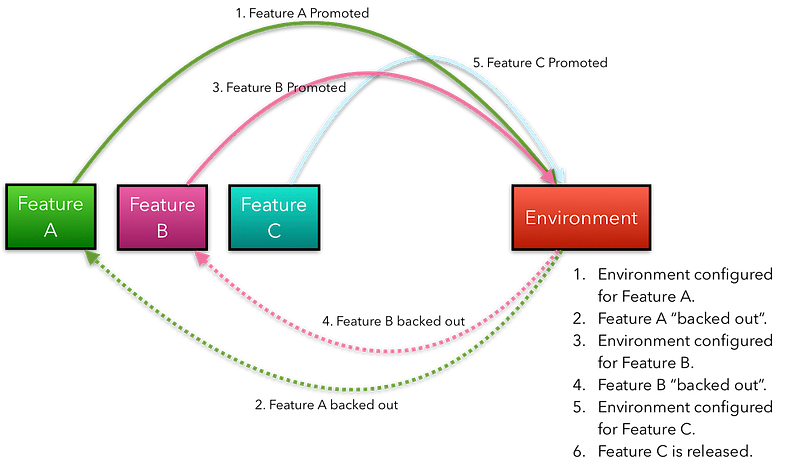
It's messy and difficult to follow. For instance, what's the current feature in the environment? It's also easy to see how drift occurs.
ENDLESS EXPEDITING
The most egregious form of this is Endless Expediting - a business remains in the throes of expediting everything, whilst delivering nothing.
We've talked about what Expediting is, its benefits and its dangers, but we've not yet discussed what causes it. Expediting occurs due to a change in business priorities. Of course, this isn't a cause [4], it's more likely to be the direct result of (some of) the following stimuli: poor culture or cultural inequality (e.g. unruly execs making unrealistic promises without informing others), the lack of a clear strategy (a lack of direction, causing subjective reasoning), too much Work-in-Progress (WIP) (which is both a cause and an effect), large batches of change (i.e. high risk, slow change), slow releases cycles (causing self-inflicted damage - it becomes the victim of expediting), imbalanced evolutionary cycles (such as between you and your dependencies), and external pressures (e.g. critical security vulnerabilities causing immediate attention, or new technologies eclipsing previously selected choices). More fundamentally, it may signal that idea generation is moving much faster than idea realisation (the creation and delivery) can be achieved, leading to half-realised solutions that are only partly, but never wholly, introduced [5].
FURTHER CONSIDERATIONS
- [1] - However, a continued lack of foresight isn't a good position to be in. A regular change in priorities may say something about: a lack of strategy, diktats from execs who don't appreciate, or care, about the difficulties, poor program management, poor quality (these get stuck in purgatory), the wrong work items being built.
- [2] - This leads to environments with a mish-mash of software and configuration introduced, and then partially removed. Environments in this position are bound to be different, thus lowering confidence.
- [3] - https://en.wikipedia.org/wiki/Hokey_Pokey
- [4] - The real culprit is whatever is causing the change in business priorities.
- [5] - This adds complexity. Some indicate their desire to simplify an estate through new change, but then only partially introduce a solution before replacing it with another, and then another and another. This isn't simplifying things, quite the opposite.
THE THREE S's - SURVIVAL, SUSTAINABILITY & STRATEGY
There are three traits I look for when judging the worthiness (its overall value to the business) of a work item, based on what I call The Three S's Principle of: Survival, Sustainability, and Strategy.
SURVIVAL
The first to consider is survival. Or, to reiterate, is the work item critical to your continued existence?
Survival may be of immediate concern, since it may feed immediate cash flow needs, but that doesn't make the work item either sustainable, or strategic. As the word suggests, being in a continued state of sustenance is undesirable; indeed it's unsustainable, and suggests that things aren't improving. Businesses that constantly react (e.g. the Cycle of Discontent), or ones with little control of an outcome, are probably stuck in the sustenance space.
SUSTAINABILITY
Sustainability is the second trait, and is about behaving sustainably. As described earlier (Sustainability), it relates to: “Behaving in a manner that is favourable to the continued viability of your business or the environment.”
This trait isn't specifically about the environment (although that's important too), it's about how you sustain any practice, process, maintenance, delivery, technology, application, or tool, to deliver a work item repeatedly, within an appropriate time frame and budget, and executed with appropriate regularity to meet customer and business needs. If you're doing this, you're in a pretty good place, but that doesn't necessarily make you strategic.
STRATEGY
Strategy then, is the final piece of the puzzle. It describes what you want and how you intend to get there. It's a guiding star, and directional (thinking and planning), but still requires realisation.
A work item can offer sustenance (e.g. immediate cash flow), and be sustainable, yet be non-strategic. Consider those activities in sectors that the business has previously supported, but no longer wishes to. Sustainability, like survival, can promote efficiency, but be ultimately ineffective (see Efficiency v Effectiveness). You can build sustainability into a process, but the question is should you if it's not strategic?
SUMMARY
Sometimes, there's a good reason to undertake a work item solely to satisfy one trait. The ideal position, however, is one that meets all three. See below.
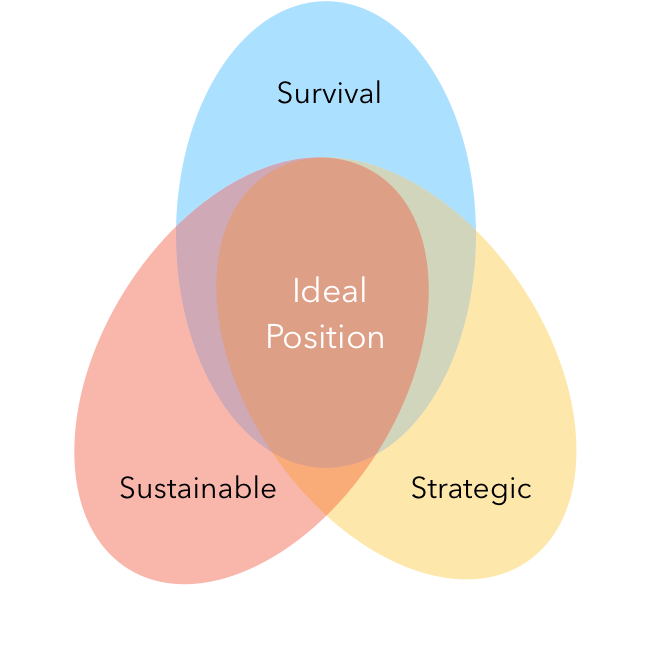
In such cases, we get survival (e.g. it has an immediate return to support cash flow), sustainability (e.g. it can be repeated in a timely, efficient, and cost-effective manner), and it is strategic (e.g. it meets the business' directional expectations). I've included a simple matrix below indicating some of these scenarios.
| Survival | Sustainable | Strategic | Comment |
|---|---|---|---|
| Y | N | N | It offers survival only. It's bringing in money (e.g. to satisfy immediate cash flow concerns), but it lacks any repeatable or sustainable structure, nor any strategic direction. |
| Y | Y | N | It offers survival, and is sustainable, but is not strategic. You may be making money and the practices you apply may be efficient, but are they taking you in the right strategic direction? Are they effective? |
| N | Y | N | It is sustainable, but lacks survivability, nor any strategic direction. You might build in efficient and repeatable practices, but they may not be immediately transferable into revenue, nor meet the business' strategic direction. Are they effective? |
| Y | Y | Y | It offers survival, is sustainable, and is strategic. This is the ideal case. You're able to subsist, by making some income from the work item, it's sustainable, meaning it's low cost and repeatable, and it's strategic, indicating it will meet the business' longer-term aspirations. |
FURTHER CONSIDERATIONS
INAPPROPRIATE FOUNDATIONS
The (Leaning) Tower of Pisa [1] might be the most exoteric example of the impact of building upon Inappropriate Foundations. First constructed in the twelfth century, it quickly showed signs of subsidence when a second floor was added. Investigations quickly discovered the problem lay not with the tower, but with its foundations (which were only three meters deep, in a infirm subsoil). During its lifetime, multiple costly restoration and stabilisation attempts have been made. And whilst tourists continue to flock to it as an attraction, as a building it's a very costly and ineffective failure - the result entirely of its poor foundations.
The same principle holds true in software construction. When the foundations are poor - the foundations here being some important quality, like Resilience - you'll likely get substandard results. It may not be immediately obvious, but, like the Pisa tower, it will become increasingly clear.
It's much harder to resolve a failing in a foundation, because many things have been built upon it (dependencies), thus making (sometimes incorrect) Assumptions about it. When you build on the equivalent of digital quicksand, you introduce risk, and place the longer-term outcome in question.
FURTHER CONSIDERATIONS
- [1] (Leaning) Tower of Pisa - https://en.wikipedia.org/wiki/Leaning_Tower_of_Pisa
- Assumptions
SILOS
Fundamentally, Silos equate to working, and thinking, in isolation. In terms of discoveries and innovations, they can be very successful, yet in terms of (business) sustainability, they often create the following concerns:
- A lack of collaboration.
- A lack of diversity, either in thinking, or in skills and experience.
- Waiting and handoffs.
- The creation of unnecessary specialisms.
- Batching.
- A lack of holistic thinking; i.e. a lack of Systems Level Thinking.
- Talent retention challenges.
Let's start from the collaboration and diversity angle. Perhaps the most obvious example of a silo lies with the individual. In the Indy, Pairing, and Mobbing section I describe how working independently is often deemed (by most) to be the most efficient way of delivering change, yet, it often leads to (unnecessary) specialisms, a loss of Shared Context, and the risk of Single Points of Individual Failure. Of course teams, departments, and even companies, can also fall foul of this. Simply merging two entities doesn't mean they're working collaboratively, nor collectively. Again, the silo often permits the individual entity to move faster, typically because there's a lower cost (or fewer short-term ramifications) to decision-making, but I regularly find this to be a false economy [1].
The lack of (early) diversity is also interesting. As I've stated elsewhere: "Greater diversity […] counters bias, and less bias equates to fewer assumptions, which leads to reduced risk. It also reduces risk in other ways. A wider range of diverse stakeholders can typically identify problems much earlier, react sooner, make better decisions, and thus enable alternative approaches to be tried. You can't do this when time is working against you - the decision is made for you". Silos, then, limit options, and that often leads to quality issues due to missing opportunities to share information and ideas with a wider, more diverse group. Late access to work and ideas that someone thinks they should be involved in, but isn't, is also likely to have a negative effect on morale, and relates to my point on talent retention.
When you work in isolation, it's easy to lose sight of your surroundings. Unfortunately, in terms of work management, that demotes Systems Level Thinking and promotes Batching. For example, even with the advent of Continuous Integration (CI), I still find individual engineers sitting on code branches for weeks, or even months. When it's finally merged back, you're then dealing with a large, risky batch of change that few have seen. No wonder things don't always go to plan. This same principle is true though at all levels of a business. A business that is siloed, tends to work with large batches of change (and the Waterfall Methodology [2]), which is risky, reduces feedback (Fast Feedback), and lowers potential ROI. Another consequence is that since large batches excel at hiding quality issues over smaller ones, then by proxy, Silos have more opportunities to lower quality.
SYSTEM-LEVEL THINKING
Business processes require holistic, system-level thinking, which considers the effect of batching and siloes. There's little point in building efficiency everywhere else, only to leave a key team siloed and working with batches [3].
For the aforementioned reasons, Silos also generate Waste (The Seven Wastes). Batching, for instance, tends to cause Waiting [4] and Overprocessing [5] (which is just another term for Gold Plating), resulting in poor ROI. Only the activities necessary to achieve the goal should be undertaken, no more, anything else is waste.
FURTHER CONSIDERATIONS
- [1] - For instance, it's quite common to find Technology Sprawl in businesses who've allowed individual teams to make their own choice and never consolidate.
- [2] - The Waterfall Methodology tends to favour bulk change and organisational silos, reducing collaboration and feedback, and therefore increasing risk.
- [3] - I've seen efficient teams hamstrung by a single siloed team they depended upon. That siloed team was constrained by manual practices, batching, and excluded from regular and meaningful interactions with the others.
- [4] - As each release is finished within one team, it sits and waits for the next to pick it up.
- [5] - When work occurs in isolation, it's typically opaque, meaning that a person or entity can work with impunity for much longer, and allowing for ample time to overprocess.
- Batching
- Continuous Integration (CI)
- Fast Feedback
- Gold Plating
- Indy, Pairing, and Mobbing
- The Seven Wastes
- Shared Context
- Single Points of Individual Failure
- Systems Level Thinking
- Technology Sprawl
MINIMAL DIVERGENCE
“Any customer can have a car painted any color that he wants, so long as it is black.” - Henry Ford.
In his biography, Grinding It Out, Ray Kroc, of McDonalds fame, describes the importance of a minimal menu, with minimal divergences in price points. Henry Ford used similar principles in his production lines. In short, this approach allows for consistency, quality (at every step), and growth.
Of course intentional product variances can make you stand out against your competitors. The theory being the greater the variance, the greater flexibility and choice a customer has, thus the more customer-oriented it is. The bad news is that unnecessary, or unsustainable, variances can quickly become a drain on the business offering them. They create a divergence (a lack of Uniformity), increasing complexity, creating (unnecessary) specialisms and Knowledge Silos, and hampering growth (it's harder to scale the business).
Clearly this is undesirable, so why do it? The two most common forms of software-related divergence I can think of are (a) bespoke features and (b) technology variance (e.g. Technology Sprawl). Let's discuss them now.
Bespoke (or custom) features are, of course, a natural outcome of customer-orientation, and shouldn't necessarily be feared. They should, though, be carefully managed to avoid an unnecessary overabundance.
Consider first that every custom feature you opt to include is an agreement by you to embed the complexities of another party within your own business. Let's pause briefly to reflect on that. For instance, if your business serves ten clients, and each comes with its own uniqueness, then you've adopted ten sets of other business' complexities within your own. Consequently, you've created client specialisms, and are (arguably) employing staff on behalf of another business [1]. Was that your intent?
Adopting too much complexity (and that includes complexity from others) can be detrimental to rate of change (TTM), your ability to adapt, or be nimble (i.e. Agility), and Evolvability (you're handing over some Control to other parties), mainly because higher complexity typically goes hand in hand with greater Assumptions, and that leads to Change Friction.
The second concept, technology variance, has already been covered elsewhere (see Technology Sprawl), so I won't dwell long here. Again, it's fine in relatively small amounts, but it's easy to overdo, thus creating divergences in skills, experience, processes and techniques, and Value Streams, that hampers scale and growth.
FURTHER CONSIDERATIONS
- [1] - I suspect there are staff coordinating with them, implementing their desired change, testing it, releasing their change, and maybe even managing their own environment.
- Assumptions
- Change Friction
- Control
- Knowledge Silos
- Technology Sprawl
- Value Streams
THE CYCLE OF DISCONTENT
Reaction can be one of the most challenging aspects of running a business. Whilst some level of reaction shows your willingness to adapt and satisfy customer needs, too much has a negative effect on deliveries, and can restrict growth and Innovation. Constant reaction leads to what I term the Cycle of Discontent; shown below.
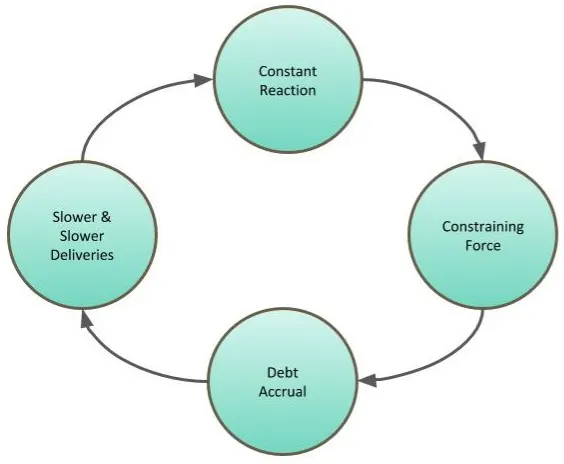
The cycle has four phases:
- Constant Reaction.
- Constraining Force.
- Debt Accrual.
- Slower & Slower Deliveries.
Let's look at them in more depth.
PHASE 1 - CONSTANT REACTION
The cycle begins when constant reaction becomes the norm. Work begins, typically with the belief that everything has been sufficiently planned and is accurate, but in this (reactionary) reality, it probably isn't.
REACTION IS THE PAST
Reaction looks to the past, thus it suggests that you're probably not looking at what's to come, nor are you innovating.
PHASE 2 - CONSTRAINING FORCE
Constraining Force may occur anywhere in a project lifecycle. It's often caused by Assumptions made earlier in the process, later discovered to be false. It may be realised by the inability to: think, assign sufficient resources or time, or satisfy the desired outcomes of all stakeholders.
When reaction is constant, there's rarely sufficient time or resource to fully analyse, understand, or contextualise the problem, and thus to identify the correct solution (which should be based upon costs, time, and quality).
Let's say your project doesn't go to plan. Your options are:
- Renege on the deal, and incur any financial or reputational costs associated with it.
- Ask for more time and/or money. This is possible but unlikely.
- Undertake the work, but soak up the costs internally.
- View quality as a mutable quality [1].
This last point often seems to be the one most travelled.
PHASE 3 - DEBT ACCRUAL
If Constraining Force has impacted quality (i.e. corners are cut to deliver the feature), then over time, Technical Debt accrues. This debt accrual starts small, but quickly mounts up as the cycle repeats with no remedial action.
These debts are poor decisions, chosen for both right and wrong reasons, that are never resolved (“paid back”). They force us to employ substandard practices, where unnecessary and overly-complex work become the norm. This is made possible by Creeping Normalcy - we become acclimatized to incremental change, but lose sight of the longer-term, holistic effect.
PHASE 4 - SLOWER & SLOWER DELIVERIES
Debt Accrual leads to the final stage; Slower Deliveries. Each change has greater risk, is more complex, or impacts many more (unnecessary) areas (it has a high Blast Radius). Tasks become harder, take longer, Change Friction is encountered, and in the most severe cases, it prevents any form of change.
Slower Deliveries has some important business implications:
- Poor TTM - feedback is slow, opportunities are missed, and unnecessary effort is spent on failing features of low value.
- Poor long-term ROI - unnecessary effort is spent on failing features and productivity is poor.
- Reduced Reputation - it becomes increasingly difficult to satisfy client demands and reputation is affected.
SUMMARY
Reaction can be a good way to emphasise your commitment to clients, yet, to paraphrase the saying, anything taken to the extreme is likely to have negative consequences. Without careful consideration and planning, it's quite easy to allow near-sighted views to dictate terms and obscure long-term goals (e.g. Sustainability), affecting quality and speed, and thereby diminishing your business.
Paradoxically, Constant Reaction has the power to undo the very qualities you may be aspiring to; e.g. your desire to support short-term TTM and ROI needs pollutes your longer-term TTM and ROI aspirations. Watch how often you sacrifice quality for delivery - it's almost always the first to face the chop, but often has the greatest long-term impact.
FURTHER CONSIDERATIONS
- [1] - One person's view of quality may differ radically from anothers. And even if there's a consensus, quality covers such a broad and diverse range of areas and subjects, that it's difficult to measure in its entirety.
- Assumptions
- Blast Radius
- Creeping Normalcy
- Innovation
- Minimal Divergence
- Reaction
- Technical Debt
CONTEXT SWITCHING
Context Switching is the concept of switching focus (and thereby, context) from one idea (and its realisation) to another. Its occasional use isn't an issue, indeed it may be healthy, but the constant need to do so is highly wasteful, both from an efficiency and effectiveness (efficacy) perspective.
CONTEXT SWITCHING & WASTE
Context Switching generates waste (The Seven Wastes) in the forms of: Transportation (we digitally transport our current activity out of one environment, and brain, and replace it with another) and Waiting (activities are paused, meaning slower delivery and less ROI).
From the individual's perspective, it's deeply frustrating and morale-zapping to be asked to regularly pause (or stop) an activity of significant cognitive load, in favour of another equally demanding activity [1]. It's disruptive, intrusive, and often requires high re-acclimatisation effort.
There's a few potential causes here. From a project perspective, we have poor planning. When work is incorrectly scoped or prioritised, or incorrect Assumptions are made, then it's likely to force the expediting of other (more important) project activities that weren't previously considered.
Some technology teams are regularly interrupted by system failures (incidents), causing them to switch focus from improvements back to nursing systems. Modern autonomic systems mitigate this, at least in part, through self-healing mechanisms that cause limited disruption (Context Switching) to humans.
Over-communication is another possibility. Outward communication should be appropriate, and timely to the audience, otherwise it's diverting them from more pressing activities [2].
Highly reactive businesses (Reaction) do a lot of Context Switching, thus, so too do their staff. However, it's the businesses which are both highly reactive and have Lengthy Release Cycles that suffer the worst. These businesses struggle to retain focus on a specific work item for long enough to finish it, before Endless Expediting occurs. The end result is that very little is delivered, Innovation and evolution are lowered, and the business' overall effectiveness is questioned.
FURTHER CONSIDERATIONS
- [1] - Although most of us should expect the occasional switching contexts. It's not necessarily a bad thing, but the repeated and regular need to do is a sign of broader issues.
- [2] - this for me has always been a hard one to gauge. Tell them too much, or too early, and much is lost, but tell them too little, and you've got a lack of clarity and morale issues.
- Assumptions
- Endless Expediting
- Innovation
- Lengthy Release Cycles
- Reaction
CREEPING NORMALCY
Since we've already discussed the causes of Technical Debt and the Cycle of Discontent elsewhere, it should be clear now why they exist. However, that doesn't describe how they're able to remain in existence. Or to reiterate, why aren't we better at tackling it?
Let's start with an analogy. Imagine yourself in a lush green forest, lazing by the tranquil azure waters that trickle down off the mountains, sunning yourself in the morning sun. It's idyllic. Suddenly though, without warning, you're transported to an arid desert. The heat is so intense that, without swift action, you will surely perish.
My point relates not to the environment, but to your need to handle extreme change in very short order. It's clear that the second situation / circumstance (arid desert) is far worse than the first (lush and temperate), and without swift action, will mean the loss of something important. See below.
| Temperate | Hot and Arid |
| 1 | 2 |
The comparison here is stark, but it's rarely how change actually occurs in a business. It's more like this.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
Note how the transition - from temperate to blisteringly hot - occurs over many steps (time). It doesn't occur overnight, otherwise it would be identified and resolved. This is the concept of Creeping Normalcy. Creeping Normalcy survives (unwanted [1]) because - by only comparing slight variations in our current and previous positions - we miss the trend. Should we view the trend though (say over fourteen steps), the problem is clear.
In real terms, Creeping Normalcy sees the normalisation of substandard practices and processes into a business (in waves) over many months and years, with each becoming a deeper impediment. It's not expected, no one wants it, nor plans for it, but it's still allowed to happen.
So, what can be done? Creeping Normalcy's breeds on inconclusive evidence. There may be sentiment, but it can't be converted into credible data to "sell" to the key stakeholders holding the purse. It's therefore allowed to exist. Metrics - such as KPIs and DORA Metrics - can help here. For instance, if the data indicates your failure rate has jumped by thirty percent in the last quarter, that's evidence of a necessary intervention.
FURTHER CONSIDERATIONS
- [1] - Unwanted because it adds poor practices, or technical debt, which goes (almost) unseen.
- Cycle of Discontent
- DORA Metrics
- KPIs
- Technical Debt
ECONOMIES OF SCALE
Economies of Scale - the act of gaining competitive advantage, by increasing the scale of operation, whilst decreasing cost - is often used to gain competitive advantage by:
- Protecting your assets from competitors.
- Reducing pricing through greater efficiencies and better bargaining power.
- Incentivising existing customers to buy more, at a cheaper price, than if those customers had to source them independently.
UNSUSTAINABLE GROWTH
I've witnessed three failures in business strategy caused by an unwillingness (or a neglect) to consolidate, that led to poor agility, reputational issues, and subsequently, growth. They are:
- Failure to consolidate a product(s) after a merger or acquisition.
- Failure to consolidate after undertaking a product replacement strategy.
- Failure to standardise on (unnecessary) variants.
Growth, through mergers and acquisitions, creates its own set of challenges. It's quite common for those businesses to be in the same industry, so they're bound to have commonalities embedded within them, in terms of capabilities and processes. Yet, it's also typical for those capabilities and processes to be sufficiently different to hamper any sort of simple lift-and-shift. One businesses' "ways" can't be easily slotted into another's [1].
Probably the most simplistic example of this divergence is a CRM solution. Each business is likely to bring its own CRM solution with them. Yet they're probably either different products, or the same, yet configured quite differently for that individual business' needs. Consequently, the merged entity now has two ways to manage and store customer information. It is a divergence in the same capability, and therefore a complexity, introduced through the merging of those businesses.
Some choose to ignore this problem. Others try to solve it through an integration project (sometimes years in length) [2]. Both approaches though, could be viewed as hiding the problem away for another day. Some choose to consolidate.
SUSTAINABLE GROWTH
Of course, businesses have successfully used this model to grow; some, however, have found it difficult to sustain, a key reason being insufficient consideration of the longer-term implications (e.g. Technical Debt) of such a strategy, and therefore not planning for it.
Each new acquisition comes with a host of new technical debts you must adopt. Without intervention, it's easy to see how an estate grows into a complex behemoth that doesn't respond well to any sort of significant change.
The product replacement (modernisation) approach - in which the business believes more custom is available through the modernisation of an existing product - also needs careful management. It's a replacement only if you remove the original solution, there is functional parity [3], and all traffic has been migrated onto the modern solution - otherwise you're left managing multiple products, and thus significant additional complexity.
However, building the new solution will take years, and your current product will still be evolving during that time. The goalposts continue to move. There's a fair chance then, that the business never performs the consolidation phase, leaving their customer base strewn across multiple applications.
Finally, we have the variants embedded within a business, caused by an overemphasis of bespoke client needs (typical in the client services model). As described in Minimal Divergence, when you choose to work on behalf of another business, you embed that business' variants (i.e. complexities) into your own, creating specialisms and potentially hampering scale.
SUMMARY
As businesses grow, some lose sight of their more humble beginnings. A single customer holds less importance than a large group, or indeed, for the need to keep growing.
But surely there's always a need to balance business growth with customer retention? Lean too far towards growth, and run the risk of alienating existing customers by diverting focus elsewhere, and eventually, creating churn [4]. Too far in the opposite direction, and you never grow, and risk competitors eating up your market share.
Unsustainable Growth is almost exclusively the result of allowing complexity to take root, of which the following diagram shows the potential consequences.
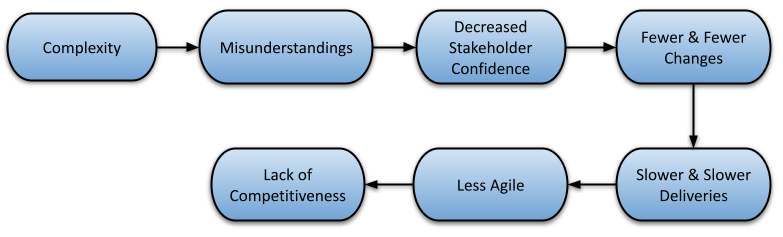
The best way to manage complexity isn't to pretend it doesn't exist, nor is it to abstract it (e.g. behind some vast integration project, albeit I can follow that logic); it's to consolidate it (see Consolidation).
FURTHER CONSIDERATIONS
- [1] - Many factors, including the environmental and cultural means evolution happens independently, leading to variances.
- [2] - To bring consistency, uniformity, staff efficiencies, and of course, customer friendly.
- [3] - Existing customers are willing to move, since it offers (at least) the same functions.
- [4] - Example? How unvalued do you feel as an existing customer when you see a great deal “only open to new customers”?
- Consolidation
- Minimal Divergence
- Technical Debt
CONSOLIDATION
Most businesses desire growth; however - as described in Unsustainable Growth - it often requires it to embed a significant amount of additional complexity. If left unchallenged, it eventually leads to evolutionary, agility, innovation, resilience (both release and runtime), staffing, cultural (e.g. new initiatives), and speed burdens.
In many cases, this complexity stems from a lack of consolidation, either in business processes, in products, tools and technologies, or in the lack of a standardised offering.
EXTREME HOARDERS
From a products, tools, and technologies perspective, it can feel a bit like those "extreme hoarders" TV shows, where the homeowner has collected many items over many years. Their house is now so packed with sundry items that it's barely liveable, and certainly not healthy. Businesses that have collected many other businesses, products, or tools, and never tidied up, may find themselves in a similar situation.
One answer is Consolidation; i.e. by identifying and removing duplication - in technology, tooling, capabilities, and business processes - complexity is reduced, leaving a leaner estate that's less confusing and easier to manage.
Consolidation, of course, takes time, and rarely adds new (sellable) functionality. Consequently, it rarely receives plaudits - i.e. why spend time and money on something that provides no obvious benefit to the customer? Of course, this is a somewhat short-term, ill-informed, and parochial view. A competitive business isn't just one that offers (at least) comparable products and services, it's also one that is effective and efficient, and that requires the constant streamlining of bloat. So if it doesn't get first-class status, maybe it should?
FURTHER CONSIDERATIONS
ROADMAPS
A roadmap is a living artifact that presents a high-level view of (mainly) future important activities to internal stakeholders and customers, and shows how the business intends to meet its future aspirations. If done right, it's a simple, yet powerful concept that quickly and succinctly articulates a high-level plan. Yet I suspect many readers, like myself, have found themselves mouthing the illustrious words: “it'll never work” once or twice in their own career.
Of course there's many reasons why a roadmap fails, but here's a breakdown of the most common problems I encounter:
- It's inaccurate.
- It's had insufficient, or untimely, stakeholder engagement.
- It's unidirectional, and thereby missing key information.
- It's treated as if it's a plan.
- It's a big list of parallel activities.
- It constantly changes.
INACCURACIES
Possibly the most common complaint with a roadmap is its lack of accuracy. Indeed some of the later points are specialisations of inaccuracy.
The most obvious problems are fictions, either in timelines, capacity, or capability. There's a good reason roadmaps don't always present timelines, at least not granular ones, yet the first question asked of a roadmap is usually when, so there should be something to back it up. Yet, amazingly, this isn't always the case. They're built on (educated) guesswork and conjecture.
Capacity is another aspect. Even if you've correctly estimated the effort, have you considered your capacity to implement such a change? If you're only working on one item, you can be confident of your capacity, if not, then you're vying for all other activities (see the section on parallel activities) and have no way to achieve it, so why make it a roadmap item?
Finally, there's capability. Have you considered the current capabilities (abilities) of the people aligned to those activities? How long will it take to get those skills and where will they come from?
INSUFFICIENT ENGAGEMENT
Anyone can build a roadmap, but building a viable one requires you to engage the right stakeholders at the right time. Never present a roadmap without giving the affected people sufficient time to consider and influence it. After all, they have the insight to validate its achievability.
TREATED AS A PLAN
A roadmap presents a high-level, typically horizontal view of the major activities required to achieve a goal. It's not a plan, or the realization of a strategy, nor should it be.
Think of it like this. Your strategy influences your plan, which influences your roadmap, but they're all independent processes and/or artefacts. You can't achieve a roadmap without an accurate, detailed, and thereby achievable, plan. Don't equate a roadmap with a plan. Alternatively, if your roadmap presents every gory detail, then it's a plan, not a roadmap, and shouldn't be presented as such.
UNIDIRECTIONAL
In Top-Down v Bottom-Up Thinking, I describe the two different, and often competing, approaches to approaching change. You may approach it from a bottom-up, current view position, where you attempt to change your current position to align with a future state, or alternatively, you may approach it from a top-down perspective, somewhat ignoring the current position, and focusing on the significant strategic changes required to reach your goal.
A roadmap that only focuses on strategic change, ignoring the tactical (bottom-up) activities, isn't a complete view of the problem space. A roadmap that presents tactical (bottom-up) activities may not be sufficiently aspirational, strategic, and future-proof. A roadmap (and plan) that considers both is a more truthful position. Unless you're delivering a purely greenfield change, you'll need both approaches.
A BIG LIST OF PARALLEL ACTIVITIES
A roadmap with lots of vertical activities probably has a smell about it [1]. You're either presenting it at the wrong granularity (e.g. are you presenting the plan rather than an overview of it?), or you're trying to do too much, and risk falling foul of WIP, coordination challenges, Expediting, and long delivery timeframes.
CONSTANT FLUX
A roadmap that is in constant flux (i.e. fortnightly or monthly changes) suggests one (or more) of the following about the business:
- It is overly reactive (Reaction, Cycle of Discontent). The business is hamstrung by reaction, forcing it to constantly adjust its plans (and thereby its future).
- It is unable, or unwilling, to control (Control) its own destiny, and is overly influenced by external (or internal [2]) factors and events. Unplanned Work may also cause this.
- It lacks direction, potentially due to a lack of strategy (Strategy), one that is ambiguous, or one that not everyone is aligned to.
- It lacks the strong leadership to challenge the external factors forcing the reaction.
- It suffers from poor or insufficient planning and estimating so predictability (Predictability) is poor and constant adjustment required.
- It is attempting to do too much (WIP), thereby causing massive complexity (Complexity) and poor assumptions (Assumptions) that must eventually be discarded.
- It is indecisive, possibly due to Complexity and the Paradox Of Choice.
- Its delivery methodology doesn't fit its needs, preventing it from adapting to changing circumstances [3].
FURTHER CONSIDERATIONS
- [1] - Unless you're a giant organisation with lots of people.
- [2] - Execs continually interfere with agreed work.
- [3] - This fits more in the solution pile.
- Assumptions
- Complexity
- Control
- Cycle of Discontent
- Expediting
- Paradox Of Choice
- Reaction
- Strategy
- Top-Down v Bottom-Up Thinking
- Unplanned Work
- Work-in-Progress (WIP)
STRATEGY
A business strategy is a detailed plan of how that business will realize its future goals. It's not just a bunch of hazy goals or fuzzy statements written down on a page for others to implement. To reiterate, a good and useful business strategy doesn't just describe what, it also describes how.
Many of the businesses I encounter who fail to make meaningful, transformational change don't have a strategy. They may think they do, but they don't. They have a set of written “goal statements” and/or themes, but no “bite”. Yet the plan is the most important piece in the puzzle. Without it, how do you know what's required, or indeed what's noise? How can you ensure everyone is aligned and focused without a detailed plan of what's required? And how do you know it's achievable?
Also note that this is not a roadmap (Roadmaps). A roadmap is a high-level (externally publishable) artifact, not a plan. A strategy is a plan that allows you to understand and sequence all activities in the most efficient and profitable manner for the business to achieve its goals. It likely requires a mix of top-down thinking and activities, and bottom-up thinking and activities (as described in Top-Down v Bottom-Up Thinking), and perhaps paradoxically, doesn't need to be fully strategic.
FURTHER CONSIDERATIONS