Scalability
SCALABILITY
| TTM | ROI | Sellability | Agility | Reputation |
Scalability is a measure of a system's ability to increase capacity, simply by increasing the resources available to it. Therefore, a scalable system requires no software changes - something that might need weeks or months of development, regression, and release effort - only the reconfiguration of its runtime platform/environment (to increase the physical or virtual resources) to meet the capacity. To put it another way, it relates to how well your systems can flex, or adapt, to a change in capacity.
Scalability is a vital quality of many modern (web-based) systems, enabling far greater numbers of users to use a system than what is considered a typical load. Yet (from my experience) it's a trait often ignored, or allocated a second-class status - at considerable cost.
LIMITS ON SCALE, LIMITS ON GROWTH
Ignoring a system's ability to scale may limit the potential growth of a business.
SCALABILITY & PERFORMANCE
Scalability and Performance aren't necessarily complementary qualities.
There is a saying in computing that: “every problem in computer science can be solved by adding a layer of indirection” [1], and an equally accurate quip that: “every performance problem in computer science can be solved by removing a layer of indirection”. [2]
We can link these statements in the following way. Things with few moving parts that are closely located tend to perform very well. Consider embedded devices, or tightly-coupled monoliths (Monoliths). They can perform activities (with a scalability caveat I'm just about to raise) very quickly because all of their dependencies live close by. The downside though is that they make many assumptions about their dependents and environments that create scalability (or Evolvability) challenges.
To generalise, if we were to take one monolith and one distributed system (e.g. Microservices architecture), of similar implementation quality, and push a marginal number of requests through each to test their performance, I suspect the monolith would win on the latency front. However, were we to crank the number of requests up, I suspect we'd see the monolith struggle much earlier (e.g. resulting in a significant increase in latency), whilst the distributed architecture remains consistent for longer.
At the most basic level, scalability is about our software's ability to manage variations in throughput - the number of transactions a system can successfully process for a given time unit. This time unit is anything that can be sensibly measured (e.g. a second, hour, day, or month) - whatever unit is important to the business.
WHAT AFFECTS THROUGHPUT?
Apologies if I'm stating the obvious, but I think it's worth highlighting that a system's throughput is affected by two main factors:
- The usage patterns of our users; i.e. the number of users, when they use it (what times of the day), the functions they use during their visit, and any event that can create a sudden increase in demand.
- The system capabilities. The changes we (or others) make to our software or systems, including its configuration, dependencies (including frameworks, and partner solutions), and the deployment platform.
A transaction is a concept related to your business that you deem important enough to measure. It might be a single API call, or an entire user journey; e.g. 10,000 cart checkout journeys in 1 hour. Throughput is measured as:
Throughput = Number of Transactions / Time
DESCRIBING SCALE
To reiterate, highly-scalable software can successfully cater to significant increases in demand, without modification. If your software requires modification to cater to growing capacity needs, then it does not scale.
There are two common approaches to software scaling:
- Vertical Scalability (also known as scaling up).
- Horizontal Scalability (also known as scaling out).
VERTICAL SCALABILITY
Vertical scalability, or scaling up, approaches scalability needs by adding additional resources to an (real or virtual) instance, such as an increase in available processing power, or memory. The thinking is that increasing the resources available to an instance should enhance a system's technical capabilities, and thus increase its throughput. We tend to use this approach if our software must (or need only) run on a single instance.
To demonstrate this, let's assume that our software runs in a corporate environment, and we have some control over the number of users. The users interface with a web front end to communicate with APIs deployed on our (single) instance. See below.

In this case, we have a single instance serving all user requests, with two CPUs and a total of 16GB of RAM. This has proven sufficient for the current user base; however, over time we see a steady increase, as new staff are on-boarded. See below.
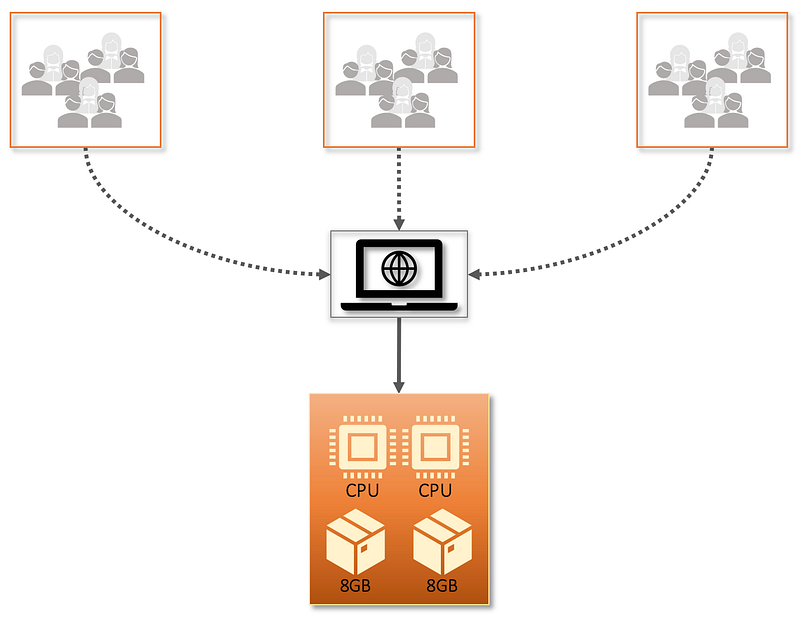
What once was sufficient is no longer the case, and we find ourselves in a precarious position, where the steady increase in users is swamping the current system to the detriment of all. In this case, we adopt a vertical scalability model, and increase the number of resources (CPU and memory) to that instance. See below.
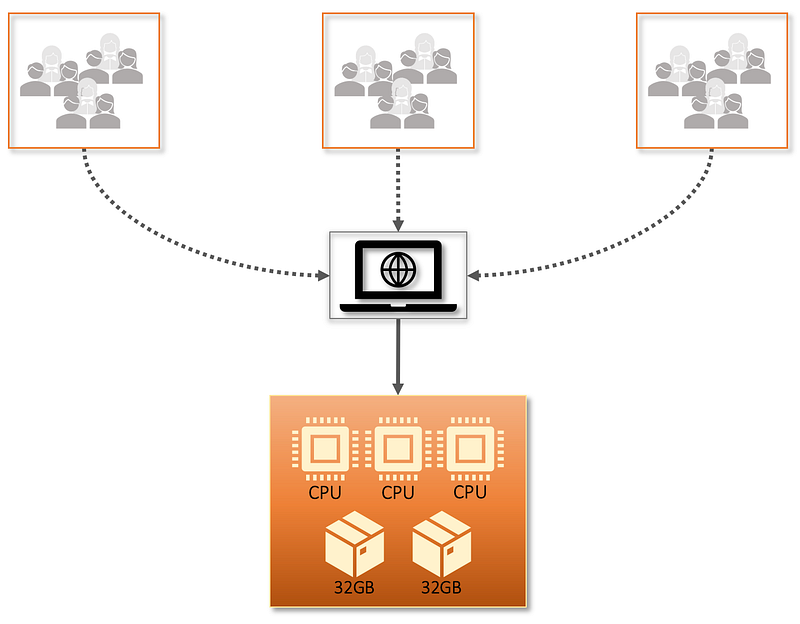
We either provision a new instance, or upgrade the existing instance, to have three CPUs and 64GB of RAM - which should better support our needs. This can be done in two ways, depending upon our setup. If we control the hardware, and there are available slots, then we can upgrade it in-situ (this may involve downtime). Alternatively, we may provision an entirely new host (real or virtual, on-prem or cloud-based) with greater capacity, deploy our software onto it, and then disable the original (as we would with Blue/Green Deployments). In either respect, we (should) now be able to cater to a greater demand, and/or process requests more quickly. Of course I'd expect you to test this, and not rely upon my conjecture of your systems!
Whilst this approach can work well, it can also be quite restrictive. First off, in reality any machine has a finite number of resources. As your user base increases, you eventually reach a tipping point, where no further vertical scalability improvements are possible (or practical). You don't want to be in this position.
Secondly is the question of Control. There tends to be a Lead Time required with this approach. For example, if we choose to migrate to a larger instance, it must first be provisioned, our software (and all of our dependencies) deployed to it, and it started up, before we can allow user access. But… how do we know the type of instance to migrate to (how much resources to provision), or when to action it? Whilst this process can be relatively fast, it isn't without a temporal cost, and therefore the need to preempt it.
This also suggests a level of control and predictability over our users and their usage patterns. For example, let's say we're supporting an internal application for a corporate client who requests support for a new team (~10% increase in users). This is a Known Quantity - something we can likely cater to using vertical scalability. Conversely, let's say we're supporting a product that's open to everyone (e.g. a social media platform, or retail shopping site). In this case we have far less control. Capacity may be affected by many things outside of our sphere of influence (how about a distributed Denial-of-Service?), and the user activity could be described as “significant, but ephemeral” - short bursts of high capacity traffic (short-term spikes). Using a vertical scalability model here (with the lead time and inability to quantify capacity) could be catastrophic.
HORIZONTAL SCALABILITY
Horizontal scalability, or scaling out, adds additional machines (i.e. physical or virtual) to meet increased demand. Or to put it another way, we increase the number of machines in our estate that we can distribute work to.
Let's use a Mass Synergy (Case Study A) scenario to demonstrate. They've recently acquired the rights to distribute a charity football game (with some of the biggest players, past and present, taking part) as a streamed pay-per-view (PPV) event. All parties have agreed that - after outgoings - any profits will be paid directly to the charity. Whilst there's no direct financial gain for Mass Synergy, it's still great advertising, so they can't afford for it to go wrong. They're already excited by the hype seen in social media and mainstream TV advertising around the game.
The first thing Anna - Mass Synergy's CTO - and her team do is to look at the existing architecture and estate. In this case, they know their carts module will take the brunt of the demand. Their current deployment model is very basic, see below. [3]

The first concern is how their system will behave when there's a sudden increase in load, shown below.

They quickly discount the vertical scaling model. The form of scaling needed is likely to be vast, is difficult to quantify, is based upon a number of fluid factors (e.g. which players will play; how well do their advertisements go; whether word of mouth will be a major factor), and lead time (for provisioning) must be very very low, due to the spiky nature of traffic. They opt for the horizontal scaling strategy; seen below.

In this case, the incoming demand is distributed across multiple instances, through an (indirectional) routing mechanism (a load balancer). In simple terms we have potentially tripled our system capacity [4]. Should that prove to be insufficient, then we repeat the practice until we get the desired results.
OF MICE AND MEN
These machines don't need to be of equal size and power. As long as the routing mechanism can understand each node's health, it can route based upon it.
To me, horizontal scalability is a better scalability model, mainly because of the finite limits imposed by a single instance in the vertical mode (or a cost limitation that makes significant scale possible but impractical). But it's also about our ability to promote flexibility and agility - we can keep adding more instances to solve capacity needs (or remove instances when no longer required), and do so at pace. It allows you to grow as your business grows, and not revisit architectural decisions ad-hoc.
HORIZONTAL SUPPORT
The ability to scale out wasn't something widely available (at least at massive scale) a few decades ago, mainly due to computing costs. Nowadays, compute resources are relatively cheap - in large part due to the Cloud, virtualisation, and Economies of Scale - making the horizontal model much more palatable.
Of course there's a downside - there always is. Firstly, the system must be capable of being distributed, and thus supporting a distributed load. This may be straightforward for greenfield projects, but not all projects have that luxury (especially established systems over a certain age). Added complexity is another concern. We've now got to deploy our software across multiple instances, and an additional (indirectional) layer to route traffic to an instance [5].
ELASTICITY
The cloud (Cloud) makes heavy use of the concept of elasticity - a quality closely related to scalability. Elasticity allows an infrastructure to be quickly expanded or shrunk (hence the term elastic) if no longer required, making it a cost-effective solution to variable loads. Elasticity is easy to achieve in a horizontal scaling model.
PILLARS AFFECTED
TTM
It's more difficult to imagine scalability affecting TTM so let me present you with an example. I once worked with a partner delivering downstream services for a new system. The partner successfully delivered the desired features, but neglected to consider the scalability and reliability needs. This led to heated conversations, contractual renegotiations, and significant waste and rework. The end result was it took far longer to deliver than planned.
With hindsight, it was clear that two things had occurred:
- Too much onus was placed on the initial TTM needs, to deliver feature-rich solutions (Functional Myopicism), and not enough on sustainability.
- There had been insufficient expert involvement, or agreement, on what was acceptable, and no SLA to resolve differences of opinion.
ROI
Whilst less obvious, Scalability and ROI are indeed related. For instance, I've experienced first-hand how a system with poor scalability can impact a business, to the point that it forced them to discard it and replace it with a new one. Surely an ultimate form of waste, and thus poor ROI.
SELLABILITY
Scalability can affect Sellability in two ways:
- A prospective customer has heard (or has experience) of your product's scalability issues and won't enter into a sales discussion. Technically, this is reputational harm - caused by an earlier event - that may (or may not) now be a fair representation of your current position.
- A prospective customer enters into a sales discussion, but requests (unavailable) evidence of the system's scaling capabilities. It's also possible to get far along the sales process (with both parties investing significant time and money), only to fail in the technical discussions.
SCALING & COSTS
Scalability also affects cost (and thus Sellability) implications. So what if a system meets a customer's capacity demands if it costs $5 million a year to operate?
AGILITY
Poorly scaling systems hamper a business' Agility, simply because they can't be offered to all potential customer demographics (e.g. the system may support smaller Tier 3 customers, but not large Tier 1 corporate customers). Again, I've experienced this. It caused the business to construct an entirely new product to meet the demand, by moving much of their workforce from supporting new features to building the same features again, but in a scalable manner.
TECHNICAL BRITTLENESS
The inability to support higher throughput suggests a technical brittleness that also hampers Sellability and Reputation.
REPUTATION
Scalability - as a quality - seems to escape the notice (or interest) of some business stakeholders (many - from my experience - suffer from Functional Myopicism). At least until it can't be ignored.
In today's technology-oriented world, we expose our software products to a wide range of demographics - and thus to critical acclaim, or downright disaster, through the medium of social media and news outlets. Users have a plethora of channels to vent their frustrations - such as at poorly performing systems. From new digital services that can't cater to massive demand, retail websites that crash during big sale events, to the failure to stream sporting events on live feeds, it's a relatively common occurrence.
However you view it, the inability to scale creates a potential reputational concern. If your systems can't scale, you may be forced to throttle traffic, suggesting that (customer) demand exceeds (your) supply, and thus losing out on sales. If you don't throttle, the alternative may be that you flood the system (Flood the System) with requests you can't handle. Poor scalability can lead to Availability (and thus Resilience) issues, all to the detriment of Reputation.
SCALABILITY, BRANDING & OVERCOMPENSATION
The problem with failing the scalability challenge is twofold. First, there's the reputational harm to your brand. Secondly - assuming you survive the reputational damage - is Overcompensation. In this situation you may place significant (to the point of the absurd) additional investment in infrastructure and the staffing to prevent a repeat performance.
SUMMARY
As this chapter demonstrates, the subject of scalability is quite involved. A system's (or a team's for that matter) ability to scale is shaped both by the assumptions (Assumptions) embedded within it, and by a (typically external) pressure to expand.
The two models of scalability are:
- Vertical - we add more resources to an existing instance, or replace it with another.
- Horizontal - we add more instances/machines.
The one to adopt depends upon system capabilities (and potentially system age), and the business' needs (such as lead time or traffic type for elasticity). Of course there's also the option to apply both approaches together - we can scale horizontally, adding “legs” as needed, but also vertically scale each leg.
Pricing is another consideration. Today's platforms offer a great deal of flexibility, enabling us to provision compute resources more quickly and cheaply, making horizontally scalability a very attractive offering, not only for scalability, but also for system redundancy, Availability, and Resilience.
Another tried-and-tested technique to improve a system's scalability is to remove the temporal constraint (or temporal assumption) from a workflow. For this, we may disassemble a (unnecessarily) synchronous-heavy process - typically through an Indirectional mechanism (e.g. Streaming & Queueing) - and perform some of its actions offline.
Some limiting factors to scalability include:
- Stateful interactions (e.g. Sticky Sessions [6]). Holding state (information) about specific user sessions in a single, unshared location (e.g. on an instance rather than a central datastore) forces you to route all related requests for that transaction back to the same instance. This can create a bottleneck, and/or availability issues.
- Unnecessary synchronous processes. Described earlier.
- Provisioning speed (this should be fast, predictable, and repeatable). As they say, forearmed is forewarned. In a locked down corporate environment you may be able to accurately predict usage, but that's much harder to do when you have little control. If your system is on fire, the last thing you want is to be told it'll be another thirty minutes to provision more capacity. When you need it, you need it quickly. It's one of the cornerstones of Serverless.
FURTHER CONSIDERATIONS
- [1] - “All problems in computer science can be solved by another level of indirection.” [David Wheeler]
- [2] - “Most performance problems in computer science can be solved by removing a layer of indirection” [unknown]. The source of this is unknown, but it paints an accurate reflection of the balancing act between scalability (which tends to like distribution and layers) and performance (which tends to like closely located things with minimal layering).
- [3] - Ok, I'm using a wee bit of artistic license here… I realise most modern systems aren't built to run on a single node, but I'm trying to tell a story! Also bear in mind that what is currently considered a best practice wasn't always available to engineers a decade or two ago. Many of those systems still exist…
- [4] - it's rarely true in practice that tripling the number of resources equates to a tripling capability in the system. However, it should still be a significant increase.
- [5] - I'm assuming a server-side rather than client-side load balancer.
- [6] - Sticky Sessions - https://www.f5.com/services/resources/white-papers/cookies-sessions-and-persistence
- Assumptions
- Blue/Green Deployments
- Case Study A
- Cloud
- Control
- Denial-of-Service
- Economies of Scale
- Flooding the System
- Functional Myopicism
- Indirection
- Known Quantity
- Microservices
- Monoliths
- Serverless
- SLA
- Streaming & Queueing